MongoDB 数据库介绍
01、MongoDB简介
MongoDB官网:https://www.mongodb.com/
MongoDB 是一个开源文档数据库,提供高性能、高可用性和自动扩展的功能。是用 C++ 语言编写的非关系型数据库。
MongoDB 是免费使用的(MongoDB分 社区版 [在所有环境下都免费] 和 企业版[在开发环境免费,生产环境收费] 两个版本)
1、性能高
MongoDB 是一个开源文档数据库,是用 C++ 语言编写的非关系型数据库。其特点是高性能、高可用、可伸缩、易部署、易使用,存储数据十分方便,主要特性有:面向集合存储,易于存储对象类型的数据,模式自由,支持动态查询,支持完全索引,支持复制和故障恢复,使用高效的二进制数据存储,文件存储格式为 BSON ( 一种 JSON 的扩展)等。
MongoDB 提供高性能数据读写功能,并且性能还在不断地提升。根据官方提供的 MongoDB 3.0 性能测试报告,在 YCSB 测试中,MongoDB 3.0 在多线程、批量插入场景下的处理速度比 MongoDB 2.6 快 7 倍。
2、支持分布式
在生产过程中,因机器故障导致系统宕机的问题不可避免;集中式系统在计算能力和存储能力方面的瓶颈,也无法满足当前的数据量爆发式增长的需求。这两个问题就是系统对高可用和可伸缩架构的需求,MongoDB 在原生上就可满足这两方面的需求。
MongoDB 的高可用性体现在对副本集 Replication 的支持上,可伸缩性体现在分片集群的部署方式上。
MongoDB 的 Replication 集提供自动故障转移和数据冗余服务,Replication 结构可以保证数据库中的全部数据都会有多份备份,这与 HDFS 分布式文件系统的备份机制比较类似。采用副本集的集群中具有主(Master)、从(Slaver)、仲裁(Arbiter)三种角色。
主从关系(Master-Slaver) 负责数据的同步和读写分离;Arbiter 服务负责心跳(Heartbeat)监控,Master 宕机时可将 Slaver 切换到 Mas 血状态,继续提供数据的服务,完成了数据的高可用需求。
当需要存储大量的数据时,主从服务器都需要存储全部数据,可能会出现写性能问题。同时, Replication 主要解决的是读数据高可用方面的问题,在对数据库查询时也只限制在一台服务器上, 并不能支持一次查询多台数据库服务器,并没有满足数据库读写操作的分布式需求。
MongoDB 提供水平可伸缩性功能的是分片(Shard)。分片与在 HDFS 分布式文件系统中上传文件会将文件切成 128MB(Hadoop2.x 默认配置)相似,通过将数据切成数片(Sharding)写入不同的分片节点,完成分布式写的操作。同时,MongoDB 在读取时提供了分布式读的操作,这个功能与 HDFS 的分布式读写十分类似。
3、安装和部署容易
MongoDB 的安装十分友好,部署容易,支持多种安装方式,对第三方组件的依赖很低,用户可以使用它较容易地搭建起一个完整的生产集群。MongoDB 的单机部署十分简单,针对分片副本集安装也有第三方工具提供辅助。
4、便于开发
MongoDB 对开发者十分友好,便于使用。支持丰富的查询语言、数据聚合、文本搜索和地理空间查询,用户可以创建丰富的索引来提升查询速度,MongoDB 被称为最像关系数据库的非关系数据库。读者可以通过对比 MongoDB 与关系数据库的操作,掌握 MongoDB 的操作特点。
MongoDB 允许用户在服务端执行脚本,可以用 Javascript 编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,使用时直接调用即可。MongoDB 支持各种编程语言,包括 Ruby、Python、Java、C++、PHP、C# 等。
5、NOSQL与SQL对比
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它是可扩展的高性能数据存储解决方案,经常被用于非关系型数据的存储,能存储海量的数据。常见的非关系型数据库还有:Redis,但 MongoDB 比 redis 更具有数据库的特性。
关系型数据库有(SQL):MySQL、Oracle、SQL Serve…..
非关系型数据库有(NOSQL):Redis、MongoDB…
传统的关系型数据库(如 MySQL)存储数据使用的是一种“行/列模型”。而 MongoDB 是一种“文档数据库”,它将数据存储在类似 JSON 的文档中。以 JSON 文档的方式存储数据,其中的好处有很多。比如,支持使用数组和对象作为值、文档间可以嵌套、查询的本身就是一个 JSON 等。
02、文档存储结构
MongoDB 文档数据库的存储结构分为四个层次:从小到大依次是:键值对、文档(document)、集合(collection)、数据库(database)
下图描述了 MongoDB 的存储与 MySQL 存储的对应关系,可以看出,MongoDB中的文档、集合、数据库对应于关系数据库中的行数据、表、数据库。
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 表/集合 |
| row(一条记录) | document | 行/文档 |
| column | field | 列/字段/域或者属性 |
| index | index | 索引 |
| table joins | 不支持 | 表连接,MongoDB不支持 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
1、键值对
文档数据库存储结构的基本单位是键值对,具体包含数据和类型。键值对的数据包含键和值,键的格式一般为字符串,值的格式可以包含字符串、数值、数组、文档等类型。简单说就是:key/value。
"name" : "mongodb"
2、文档
文档是 MongoDB 的核心概念,是数据的基本单元,与关系数据库中的行十分类似,但是比行要复杂。文档是一组有序的键值对集合。文档的数据结构与 JSON 基本相同,所有存储在集合中的数据都是 BSON 格式。BSON 是一种类 JSON 的二进制存储格式,是 Binary JSON 的简称。
{"country" : "China", "city": "BeiJing"}
{
_id: "joe",
name: "Joe Bookreader",
address: {
street: "123 Fake Street",
city: "Faketon”,
state: nMAnz
zip: T2345”
}
}
3、集合
MongoDB 将文档存储在集合中,一个集合是一些文档构成的对象。如果说 MongoDB 中的文档类似于关系型数据库中的“行”,那么集合就如同“表”。
集合存在于数据库中,没有固定的结构,这意味着用户对集合可以插入不同格式和类型的数据。但通常情况下插入集合的数据都会有一定的关联性,即一个集合中的文档应该具有相关性。

4、数据库
在 MongoDB 中,数据库由集合组成。一个 MongoDB 实例可承载多个数据库,互相之间彼此独立,在开发过程中,通常将一个应用的所有数据存储到同一个数据库中,MongoDB 将不同数据库存放在不同文件中。
03、基本数据类型
BSON 支持的数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。表示,{“x” : [“a”, “b”, “c”]} |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Timestamp | 时间戳:var a = new Timestamp() |
| Object ID | 对象 ID。用于创建文档的 ID。(如果不指定的话,mongodb默认会给一个 _id) |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式 |
MongoDB 下载与安装
01、Win10 安装
1、下载指定版本
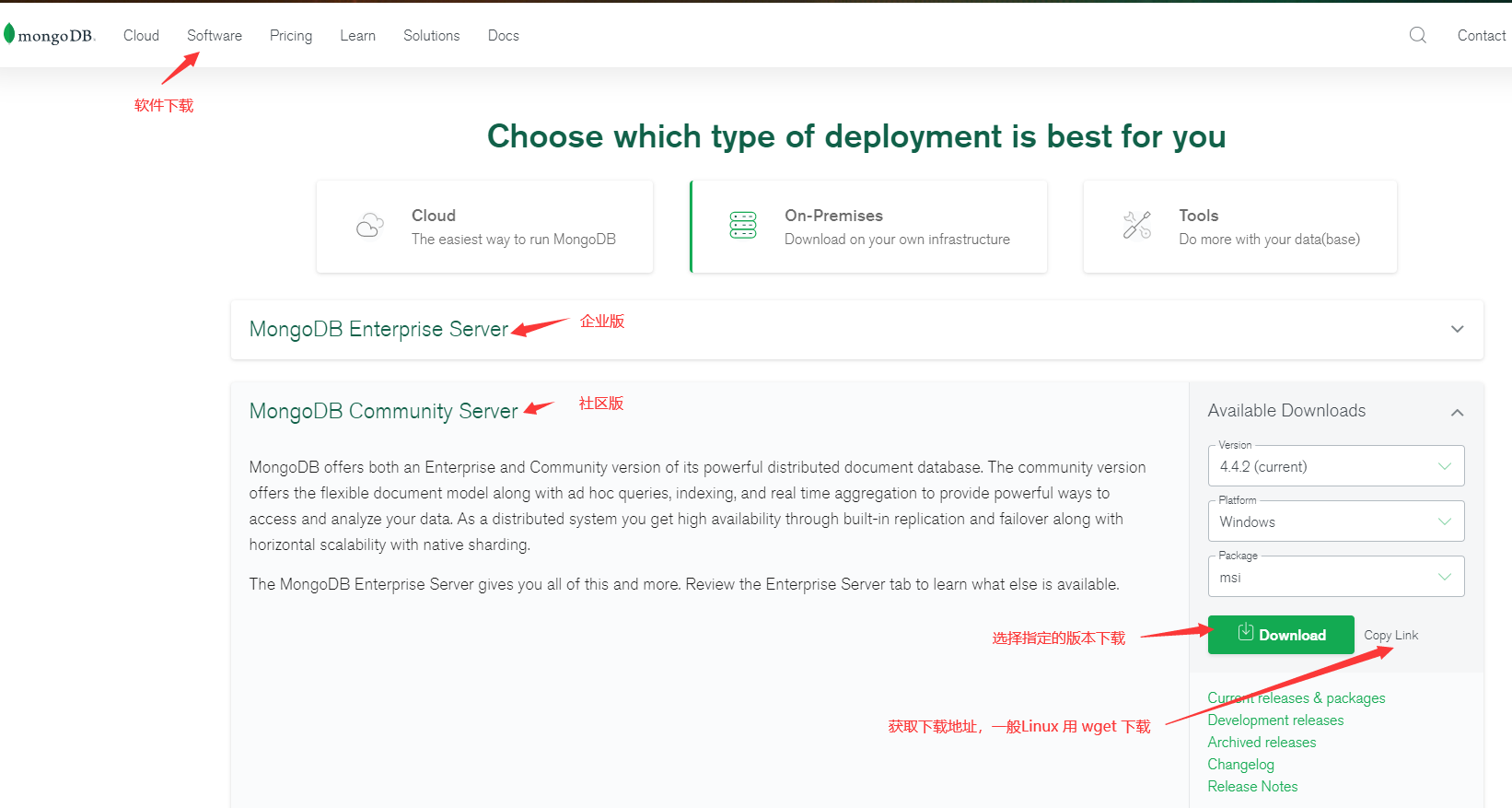
- MongoDB Enterprise Server:企业版(收费版)、MongoDB Community Server:社区版(免费版)
- 下载完成后,获得安装包:
mongodb-windows-x86_64-4.4.2-signed.msi,双击即可安装。
2、选择安装方式
- 如果已经安装过该版本的MongoDB,会是这个界面(如果没有安装过忽略此步骤)
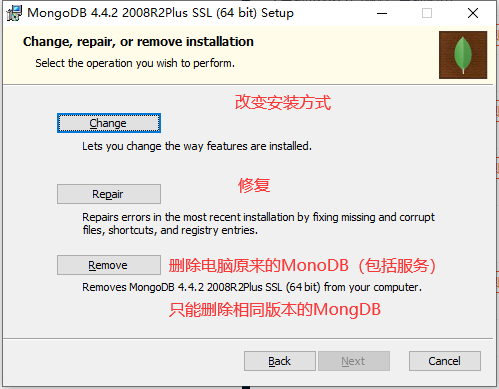
选择Complete,表示安装到默认路径(不推荐,C盘懂的都懂)
选择Custom,表示自定义安装路径(推荐)
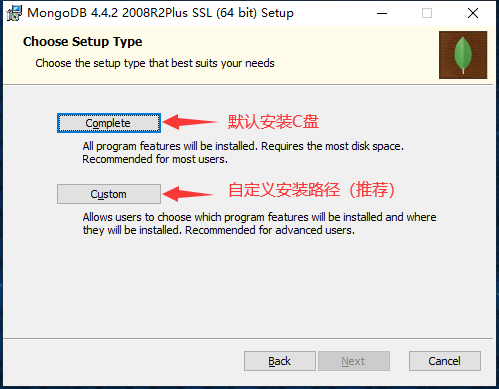
3、选择安装路径
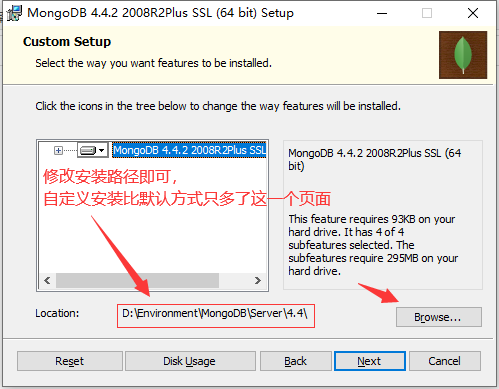
注意:MongoDB 3.x 系列版本的数据库,在安装成功后,每次在使用前都需要手动启动MongoDB服务!
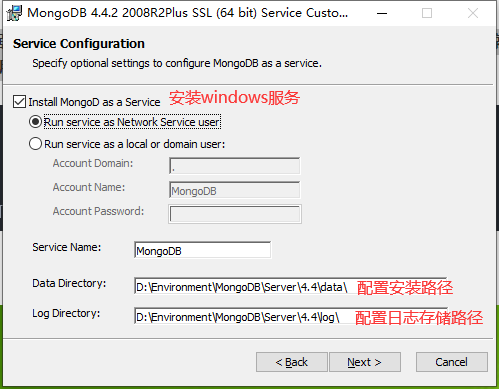
现在:MongoDB 4.x 系列版本的数据库,在安装时默认安装(选中了 Install MongoD as a Service)服务 ,就是在开机时自动启动 MongoDB 服务,然后就可以直接使用啦!
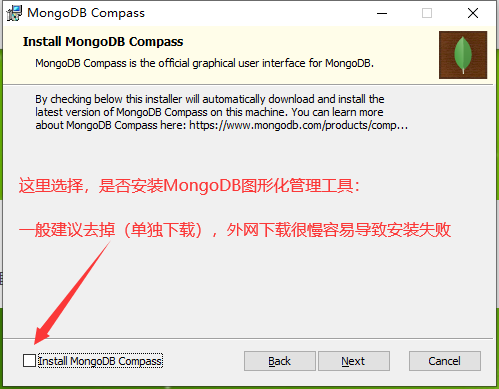
然后就一直下一步、Next 直到 Flnish 安装完毕,到此就MongoDB就安装结束啦!
4、检查是否安装成功
- 方式一:
1、运行 Win + R
2、输入 services.msc 命令便可以查看到 MongoDB Server (MongoDB) 服务啦!!
- 方式二:
1、打开任意浏览器输入:http://127.0.0.1:27017/
2、返回如下信息代表安装成功:
It looks like you are trying to access MongoDB over HTTP on the native driver port.
- 方式三:
C:\Users\lenovo>mongod -version
db version v4.4.2
Build Info: {
"version": "4.4.2",
"gitVersion": "15e73dc5738d2278b688f8929aee605fe4279b0e",
"modules": [],
"allocator": "tcmalloc",
"environment": {
"distmod": "windows",
"distarch": "x86_64",
"target_arch": "x86_64"
}
}
到此位置:windows安装mongodb已经成功了。
备注:由于我们是用.msi方式安装的,所以可以省略掉MongoDB服务的安装,还有data目录和logs文件的创建。
如果是下载 ***.zip** 文件安装的话,请参考下面:mongod 命令启动服务端。
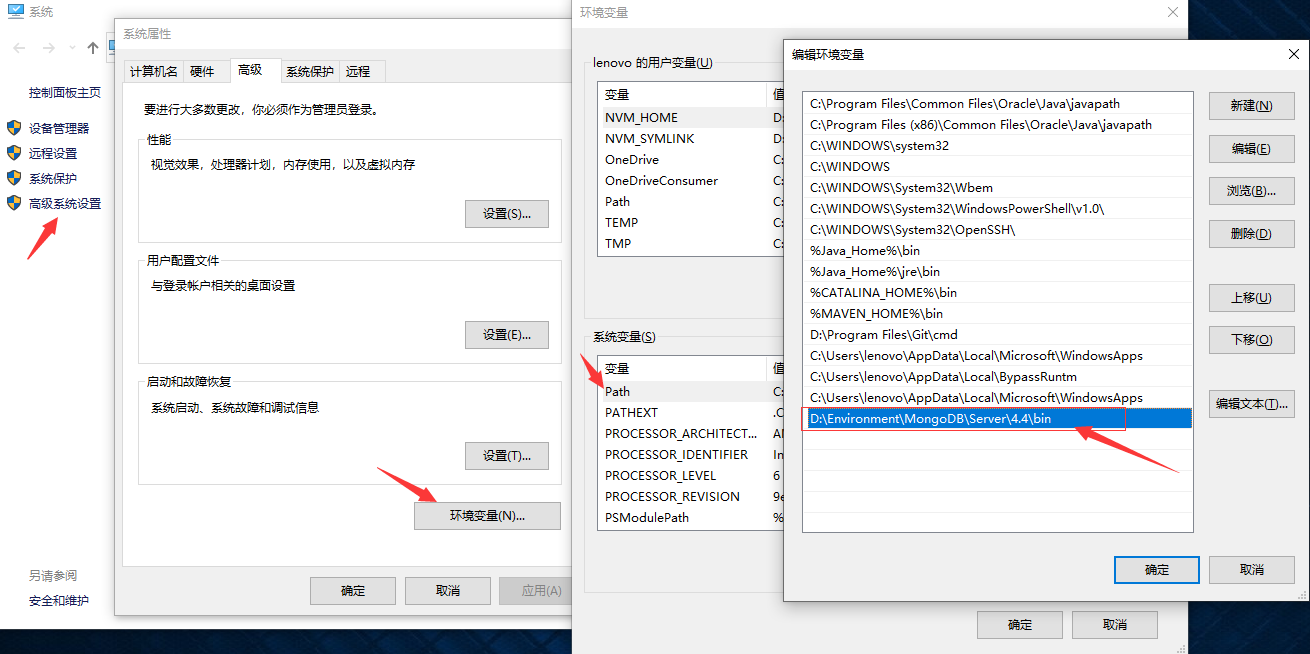
5、配置系统环境变量
如果.msi安装的话默认已经配置好环境变量了
6、目录与配置文件说明
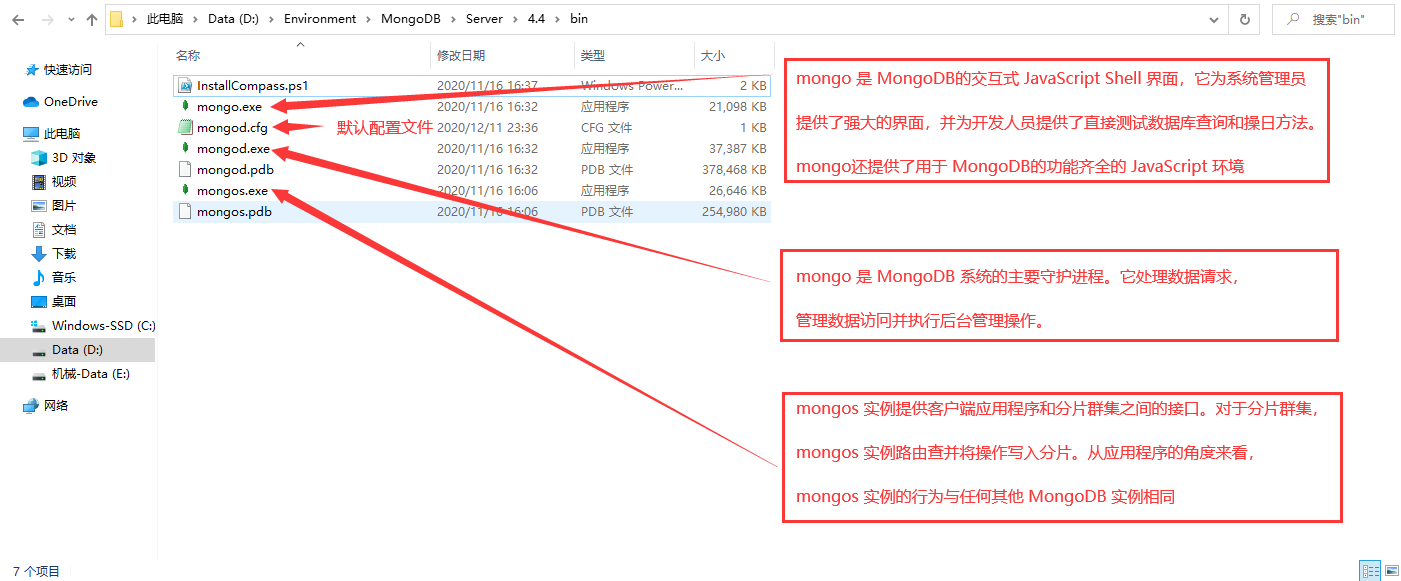
安装成功后默认生成配置文件:bin/mongod.cfg
# http://docs.mongodb.org/manual/reference/configuration-options/
# Where and how to store data.
storage:
dbPath: D:\Environment\MongoDB\Server\4.4\data # 数据存储目录
journal:
enabled: true
# where to write logging data.
systemLog:
destination: file
logAppend: true # 日志采用追加模式
path: D:\Environment\MongoDB\Server\4.4\log\mongod.log # 日志文件地址
# network interfaces
net:
port: 27017
bindIp: 127.0.0.1 # 数据库端口号
# 开启数据库访问权限验证(注意:换行、缩进格式哦!!)默认是没有这个的
#security:
# authorization: enabled
7、mongod 与 mongo 命令
一定要以管理员身份启动CMD!一定要以管理员身份启动CMD!一定要以管理员身份启动CMD!
这两个命令的作用分别是:
- mongod 启动 MongoDB 服务器
- mongo 在启动服务器后,帮助我们连接到 MongoDB 实例,也就是进入 Mongo shell(相当于让我们进入后台操作数据库)
mongod 命令启动参数:
| 参数 | 描述 |
|---|---|
| -f、–config | 指定配置文件路径 |
| –bind_ip | 绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP(0.0.0.0) |
| –dbpath | 指定数据库路径 |
| –logpath | 指定MongoDB日志文件,注意是指定文件不是目录 |
| –logappend | 使用追加的方式写日志 |
| –port | 指定服务端口号,默认端口27017 |
| –serviceName | 指定服务名称 |
| –serviceDisplayName | 指定服务名称,有多个mongodb服务时执行。 |
| –install | 指定作为一个Windows服务安装。 |
| –remove | 移除MongoDB服务(Windows上使用) |
| –auth | 表示加载认证功能 |
MongoDB Windows 服务安装:
######################## MongoDB方式创建win服务:########################
# 安装 MongoDB 服务,指定配置文件安装(没有指定服务名的话默认服务名为:MongoDB)
mongod --config "D:\Environment\MongoDB\Server\4.4\bin\mongod.cfg" --install
# 命令行参数指定安装 MongoDB 服务
mongod --bind_ip 0.0.0.0 --dbpath "D:\Environment\MongoDB\Server\4.4\data\db" --logpath "D:\Environment\MongoDB\Server\4.4\log\mongod.log" --logappend --serviceName "MongoDB" --install
# 移除 MongoDB 服务,必须先关闭 MongoDB 服务
mongod --remove
# 启动和关闭 MongoDB 服务,该名称为--serviceName设置的名称
net start MongoDB
net stop MongoDB
######################## windows自带创建win服务方式:########################
# 创建 MongoDB 服务(中间几个引号很关键)
sc.exe create MongoDB binPath= "\"D:\Environment\MongoDB\bin\mongod.exe\" --service --config= \"E:\Environment\MongoDB\mongo.config"" DisplayName= "MongoDB" start= "auto"
# 删除 MongoDB 服务
sc delete MongoDB
mongo 命令:进入 MongoDB Shell界面(登录)
# 1、直接进入
mongo
# 2、连接到config(任何)数据库
mongo 127.0.0.1:27017/config
# 3、不连接到任何数据库
mongo --nodb
# 4、启动之后,在需要时运行new Mongo(hostname)命令就可以连接到想要的mongod了:
> conn=new Mongo('127.0.0.1:27017')
connection to 127.0.0.1:27017
> db=conn.getDB('admin')
admin
# 4、help查看帮助
# mongo -u admin -p password # 连接本地数据库,使用了--auth启动,输入账号密码
# 连接运程MongoDB数据库:(必须指定 绑定IP 和 端口号)
# 格式:mongo 绑定IP:端口号/数据库名 -u 用户名 -p 密码
mongo 127.0.0.1:27017/test -u admin -p password
或者
mongo --host 127.0.0.1 --port 27017
# 也可以登录shell后输入用户名和密码登录
db.auth("admin", "password")
02、Linux 安装
MongoDB官网下载地址:https://www.mongodb.com/try/download/community
1、MongoDB 安装步骤
# 1.切换opt目录
$ cd /opt/
# 2.wget下载安装包
$ wget -P /opt/ https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-amazon-4.4.2.tgz
# 3.解压
$ tar -xzvf /opt/mongodb-linux-x86_64-amazon-4.4.2.tgz
# 4.移动目录并且重命名
$ mv /opt/mongodb-linux-x86_64-amazon-4.4.2 /usr/local/mongodb
# 5.新建data和logs目录
$ mkdir -p /usr/local/mongodb/{data,logs}
# 6.授权目录
$ chmod 777 /usr/local/mongodb/{data,logs}
# 7.profile配置文件中增加环境变量,然后刷新配置
$ echo "export PATH=\$PATH:/usr/local/mongodb/bin" >> /etc/profile && source /etc/profile
2、启动 MongoDB
MongoDB 的启动方式分为两种:前置启动、后置启动
无论哪种启动方式都需要执行 bin 目录中的 mongod 命令。MongoDB 在启动时默认的查找数据库的路径为/data/db。如果我们数据库路径有变化,需要在该命令中通过–dbpath 参数来指定 db 目录的路径(该路径可以是绝对路径,也可是相对路径)
2.1、前置启动(配置参数)
# data 目录需要提前创建
mongod --dbpath /usr/local/mongodb/data
2.2、后置启动(配置参数)
所谓后置启动就是以守护进程的方式启动 MongoDB。
我们需要在执行 mongod 命令中添加 –fork 参数。需要注意的是,–fork 参数需要配合着–logpath 或者是–syslog 参数使用。–logpath 与–syslog 参数是指定 MongoDB 的日志文件。MongoDB 的日志文件可以在系统中*的任意位置,本文章中我们在 mongodb 目录下创建 log 目录,在该目录中创建一个名为mongodb.log 的日志文件。
# data和logs目录需要提交创建,mongodb.log文件可不创建。--fork后台启动
mongod --dbpath /usr/local/mongodb/data --logpath /usr/local/mongodb/logs/mongodb.log --fork
2.3、配置文件方式启动
如果觉得在启动 MongoDB 时给定的参数项太多,那么我们也可以通过配置文件来配置启动参数,配置文件可以在任意目录中,配置文件的扩展名应为.conf,配置文件中使用key=value 结构。在执行 MongoDB 时通过–config 参数来指定需要加载的配置文件。我们在 /bin 目录中创建一个名为 mongodb.conf 配置文件
# 1.创建配置文件 mongodb.conf
$ sudo tee /usr/local/mongodb/bin/mongodb.conf <<-'EOF'
dbpath=/usr/local/mongodb/data
logpath=/usr/local/mongodb/logs/mongodb.log
port=27017
fork=true
bind_ip=0.0.0.0
#auth=true
EOF
# 1.或vim 编辑
$ vim /usr/local/mongodb/bin/mongodb.conf
# 增加如下配置
dbpath=/usr/local/mongodb/data # 指定 db 路径
logpath=/usr/local/mongodb/logs/mongodb.log # 指定日志文件
logappend=true # 使用追加的方式写日志
port=27017 # 配置端口
fork=true # 配置后端启动
bind_ip=0.0.0.0 # 设置所有ip都可以访问
journal=true # 每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。
directoryperdb=true
quiet=true
bind_ip_all=true
auth=true # 启动验证
#noauth=true # 不启用验证
# 2.通过加载配置文件启动MongoDB。-f --config.效果一样
$ mongod -f /usr/local/mongodb/bin/mongodb.conf
$ mongod --config /usr/local/mongodb/bin/mongodb.conf
3、关闭 MongoDB
Ctrl + C 关闭(安全关闭):前置启动的话可以直接使用快捷键 Ctrl + C 就可以关闭 MongoDB
kill 命令关闭(非安全关闭):kill -9 PID、kill -2 PID、kill -4 PID
MongoDB 函数关闭(安全关闭,要在admin库执行):db.shutdownServer()、db.runCommand(“shutdown”)
mongod 命令关闭(安全关闭):./mongod –shutdown –dbpath<数据库路径>
示例:
## 方式一
> use admin
switched to db admin
> db.shutdownServer()
server should be down...
>
## 方式二
$ mongod --shutdown --dbpath /usr/local/mongodb/data/db
03、Docker 安装
1、docker 安装
# 1.下载MongoDB Docker镜像
$ docker pull mongo:4.4.2
$ docker pull mongo:latest
# 2.启动MongoDB服务
$ docker run -itd -p 27017:27017 --name mongodb mongo:4.4.2
$ docker run -itd -p 27017:27017 --name mongodb -v /mydata/mongo/db:/data/db mongo:4.4.2
# 3.启动MongoDB服务并设置账号
$ docker run -itd -p 27017:27017 --name mongodb mongo:4.4.2 --auth
$ docker run -itd -p 27017:27017 --name mongodb -v /mydata/mongo/db:/data/db mongo:4.4.2 --auth
# 4.进入容器中的MongoDB客户端
$ docker exec -it mongodb mongo
# 5.在admin数据库中创建超级管理员账号
> use admin
> db.createUser({
user: 'admin',
pwd: 'password',
roles: [{ role: "userAdminAnyDatabase", db: "admin" }]
});
>
# 6.创建完成后验证是否可以登录
> db.auth("admin","password")
2、docker-compose 安装
- docker-compose.yml
version: '3'
services:
mongodb:
image: mongo:4.4.2 # 镜像:版本
container_name: mongo_db # 容器名
environment:
- MONGO_INITDB_ROOT_USERNAME=admin # root管理员账户
- MONGO_INITDB_ROOT_PASSWORD=password # root管理员密码
- MONGO_INITDB_DATABASE=admin # 默认的数据库
volumes:
- ./mongo/init-mongo.js:/docker-entrypoint-initdb.d/init-mongo.js:ro
- ./mongo/mongo-volume:/data/db
ports:
- "27017-27019:27017-27019"
restart: always
- init-mongo.js
// db.getSiblingDB("admin") 相当于 use admin;
db.getSiblingDB('admin').createUser({
user: 'user',
pwd: 'user',
roles: ['readWrite']
});
- 执行启动命令即可
docker-compose up -d
账户及权限管理
注意:安装好MongoDB数据库后,默认是【非授权模式】(也就是不需要任何权限验证、不需要验证账户,直接输入 mongo 命令就可以进行相关操作)
所以:为了数据的安全,我们都应该去配置数据库的访问权限 和 修改默认(mongodb://127.0.0.1:27017)连接绑定IP 和 端口号!
MongoDB是基于角色的访问控制,所以创建用户需要指定用户的角色,在创建用户之前需要满足:
- 先在admin数据库中创建角色为 userAdmin 或 userAdminAnyDatabase 的用户作为管理用户的用户
- 启用访问控制,进行登录用户验证,这样创建用户才有意义
00、用户角色介绍
数据库角色分类(Built-In Roles—内置角色):
- 数据库用户角色:read、readWrite
- 数据库管理角色:dbAdmin、dbOwner、userAdmin
- 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager
- 备份恢复角色:backup、restore
- 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
- 超级用户角色:root
- 内部角色:__system
- 这几个角色直接或间接提供系统超级用户的访问权限:dbOwner 、userAdmin、userAdminAnyDatabase
各角色说明:
read:允许用户读取指定数据库
readWrite:允许用户读写指定数据库
dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问 system.profile
userAdmin:允许用户向 system.users 集合写入,可以找指定数据库里创建、删除和管理用户
clusterAdmin:只在 admin 数据库中可用,赋予用户所有分片和复制集相关函数的管理权限
readAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的读权限
readWriteAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的读写权限
userAdminAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的 userAdmin 权限
dbAdminAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的 dbAdmin 权限
root:只在 admin 数据库中可用。超级账号,超级权限
MongoDB数据库中的内置角色:
(1)、【数据库用户角色】针对每一个数据库进行控制。
read:提供了读取所有非系统集合,以及系统集合中的system.indexes, system.js, system.namespaces
readWrite:包含了所有read权限,以及修改所有非系统集合的和系统集合中的system.js的权限.
(2)、【数据库管理角色】每一个数据库包含了下面的数据库管理角色。
dbOwner:该数据库的所有者,具有该数据库的全部权限。
dbAdmin:一些数据库对象的管理操作,但是没有数据库的读写权限。(参考:http://docs.mongodb.org/manual/reference/built-in-roles/#dbAdmin)
userAdmin:为当前用户创建、修改用户和角色。拥有userAdmin权限的用户可以将该数据库的任意权限赋予任意的用户。
(3)、【集群管理权限】admin数据库包含了下面的角色,用户管理整个系统,而非单个数据库。这些权限包含了复制集和共享集群的管理函数。
clusterAdmin:提供了最大的集群管理功能。相当于clusterManager, clusterMonitor, and hostManager和dropDatabase的权限组合。
clusterManager:提供了集群和复制集管理和监控操作。拥有该权限的用户可以操作config和local数据库(即分片和复制功能)
clusterMonitor:仅仅监控集群和复制集。
hostManager:提供了监控和管理服务器的权限,包括shutdown节点,logrotate, repairDatabase等。
备份恢复权限:admin数据库中包含了备份恢复数据的角色。包括backup、restore等等。
(4)、【所有数据库角色】
admin:数据库提供了一个mongod实例中所有数据库的权限角色:
readAnyDatabase:具有read每一个数据库权限。但是不包括应用到集群中的数据库。
readWriteAnyDatabase:具有readWrite每一个数据库权限。但是不包括应用到集群中的数据库。
userAdminAnyDatabase:具有userAdmin每一个数据库权限,但是不包括应用到集群中的数据库。
dbAdminAnyDatabase:提供了dbAdmin每一个数据库权限,但是不包括应用到集群中的数据库。
(5)、【超级管理员权限】
root: dbadmin到admin数据库、useradmin到admin数据库以及UserAdminAnyDatabase。但它不具有备份恢复、直接操作system.*集合的权限,但是拥有root权限的超级用户可以自己给自己赋予这些权限。
(6)、【备份恢复角色】
backup:数据库备份
restore:数据库恢复
(7)、【内部角色】
__system
01、创建管理员用户
启用访问控制登录之前,首先需要在admin数据库中创建角色为 userAdmin 或 userAdminAnyDatabase 作为用户管理的用户,之后才能通过这个用户创建其它角色的用户,这个用户作为其它所有用户的管理者。
> # 1.切换admin数据库
> use admin
> # 2.添加管理员用户:user/pwd 分别代表用户名和密码,role 代表角色,db 代表要设置的数据库。
> db.createUser({user:"admin", pwd:"password", roles:[{role: "userAdminAnyDatabase", db: "admin" }]})
> db.createUser({
user: "admin",
pwd: "password",
roles: [{ role: "userAdminAnyDatabase", db: "admin" }]
}
)
Successfully added user: {
"user" : "admin",
"roles" : [
{
"role" : "userAdminAnyDatabase",
"db" : "admin"
}
]
}
02、开启授权访问控制
要开启访问控制,则需要在mongod进程启动时加上选项--auth或在启动配置文件加入选项auth=true,并重启mongodb实例。
Windows 环境下
方式一:配置文件方式启动
MongoDB数据库的相关配置信息,是存储在mongodb安装目录bin目录中的mongod.cfg文件中,
- 找到
mongod.cfg文件,然后增加如下配置:
# 开启数据库访问权限验证(注意:换行、缩进格式哦!!)
security:
authorization: enabled
- 然后重新启动MongoDB服务.
方式二:启动时添加授权参数(以管理员身份启动CMD)
# 先关闭MongoDB服务,然后移除,最后重新安装MongoDB服务,带上--auth参数
net stop MongoDB
mongod --remove
mongod --config "D:\Environment\MongoDB\Server\4.4\bin\mongod.cfg" --install --auth
net start MongoDB
Linux 环境下
方式一:配置文件方式启动
# 1.mongod配置文件追加如下配置:
$ echo "auth=true" >> /usr/local/mongodb/bin/mongodb.conf
# 2.启动mongodb实例
$ mongod --conf mongodb.cnf
# 3.使用mongo shell登录mongodb实例:
$ mongo 127.0.0.1:27017
MongoDB shell version v4.4.2
connecting to: mongodb://192.168.58.2:27017/test?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("428c215c-2927-49ee-8507-573efc4a1185") }
MongoDB server version: 4.0.9
>
# 如果没有开启访问控制,则在登录时会提示如下警告信息
** WARNING: Access control is not enabled for the database.
** Read and write access to data and configuration is unrestricted.
方式二:启动时添加授权参数
# 前台启动
mongod --dbpath /usr/local/mongodb/data --auth
# 后台启动
mongod --dbpath /usr/local/mongodb/data --logpath /usr/local/mongodb/logs/mongodb.log --fork --auth
03、用户认证登陆
注:重新启动mongodb服务后,用一个新的命令窗口来做操作,在配置账户权限后,直接在命令窗口中用 mongo 命令,运行相关的操作是没有响应的,只有在正确的输入账户和密码后才进行相关操作!!
可以在使用mongo shell登录时添加选项--authenticationDatabase或登录完后在admin数据库下进行验证。
- 在mongo shell登录时同时进行验证:
$ mongo 127.0.0.1:27017 -uuser_admin -p --authenticationDatabase admin
MongoDB shell version v4.0.9
Enter password: # 输入密码admin
connecting to: mongodb://192.168.58.2:27017/test?authSource=admin&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("94663b8d-7d88-4c97-ad1c-c3c24262ad39") }
MongoDB server version: 4.0.9
>
- mongo shell 登录完成之后进行验证:
$ mongo 127.0.0.1:27017
MongoDB shell version v4.0.9
connecting to: mongodb://192.168.58.2:27017/test?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("531e75df-3a5d-4f35-9e18-d7a6e090df63") }
MongoDB server version: 4.0.9
> use admin
switched to db admin
> # 登录认证,返回1,代表登录成功
> db.auth('user_admin','admin')
1
- 连接本地MongoDB数据库(不指定IP 和端口号):
mongo -u admin -p password - 连接远程MongoDB数据库(指定IP 和 端口号):
- 不指定数据库名(没有输入账号登录):
mongo --host 127.0.0.1 --port 27017 - 不指定数据库名(输入账号登录):
mongo --host 127.0.0.1 --port 27017 -u admin -p password - 指定登录数据库(输入账号登录):
mongo 127.0.0.1:27017/admin -u admin -p password
- 不指定数据库名(没有输入账号登录):
04、创建普通用户
注:各个不同的数据库之间,可以创建有一个 或 多个账户,各数据库之间账户、密码都是独立的,不能互相访问!
- 使用admin用户在admin数据库中创建基于角色dbOwner的用户test
# 方式一:
# customData 内可以设置任何描述该用户的信息
> use admin
> db.createUser({
user: "test",
pwd: "password",
roles: [{role: "dbOwner", db: "test"}],
customData: {info: "user for dbOwner"}
}
)
# 方式二:
> db.getSiblingDB("admin").runCommand({
createUser: "test",
pwd: "password",
roles: [{role: "dbOwner", db: "test"}],
customData: { info: "user for dbOwner"}
}
)
{ "ok" : 1 }
- 登录test数据库给创建test用户,并且赋予该用户权限
> use test
> db.createUser({
user: "test_admin",
pwd: "password",
roles: [
{role: "read", db: "test"},
{role: "readWrite", db: "test"}]
})
05、查看用户信息
1、查询当前数据库的指定用户:db.getUser(‘用户名’, args)
2、查看当前数据库的所有用户:db.getUsers()、show users
参数说明:
| Field | Type | Description |
|---|---|---|
showCredentials |
boolean | 可选的。将字段设置为 true 以显示用户的密码哈希。默认情况下,此字段为false。 |
showPrivileges |
boolean | 可选的。将字段设置为 true 以显示用户的完整特权集,包括继承角色的扩展信息。默认情况下,此字段为false。如果查看所有用户,则不能指定此字段。 |
showAuthenticationRestrictions |
boolean | 可选的。将字段设置为 true 以显示用户的身份验证限制。默认情况下,此字段为false。如果查看所有用户,则不能指定此字段。 |
- 查询指定用户
# 方式一:
> use admin
> db.getUser("admin", { showPrivileges: true })
# 方式二:
> db.getSiblingDB("admin").runCommand({
usersInfo: "admin",
showPrivileges: true
}
)
- 查询所有用户:
> show users
{
"_id" : "admin.admin",
"userId" : UUID("f4000321-33d7-43bd-b791-a42294c4a004"),
"user" : "admin",
"db" : "admin",
"roles" : [
{
"role" : "root",
"db" : "admin"
}
],
"mechanisms" : [
"SCRAM-SHA-1",
"SCRAM-SHA-256"
]
}
{
"_id" : "admin.test",
"userId" : UUID("c6788e01-a812-4bb8-8d57-0553731e27c4"),
"user" : "test",
"db" : "admin",
"roles" : [
{
"role" : "dbOwner",
"db" : "test"
}
],
"mechanisms" : [
"SCRAM-SHA-1",
"SCRAM-SHA-256"
]
}
06、更新用户信息
updateuser()它是完全替换之前的值:
如果要新增或添加roles而不是代替它 则使用方法: db.grantRolesToUser() 和 db.revokeRolesFromUser()
如果只是更新密码也可以只用此方式:db.changeUserPassword()
更新用户 test 具有 admin 数据库 readWrite 角色为read角色。
> use admin
> db.updateUser("test",{
customData: { info: "user for test" },
roles: [{role: "read", db: "test" }]
})
> use admin
> db.runCommand({
updateUser: "test",
roles: [{ role: "read", db: "test" }],
customData: { info: "user for test" }
})
07、更新用户角色
1、db.grantRolesToUser():为用户增加角色
2、db.revokeRolesFromUser():为用户回收角色
- 为用户test添加admin数据库的readWrite角色。
# 方式一:
> use admin
> db.grantRolesToUser("test",
[
{role: "readWrite", db: "admin"},
{role: "dbOwner", db: "admin"}
]
)
# 方式二:
> use admin
> db.runCommand({
grantRolesToUser: "test",
roles:
[
{role: "readWrite", db: "admin" },
{role: "dbOwner", db: "admin" }
]
}
)
- 用户dbabd_user回收admin数据库的read角色。
# 方式一:
> use admin
> db.revokeRolesFromUser("test", [{ role: "dbOwner", db: "test"}])
# 方式二:
> use admin
> db.runCommand({
revokeRolesFromUser: "test",
roles:[{ role: "dbOwner", db: "test"}]
})
08、更改用户密码
db.updateUser('username',{'pwd':'newpassword'})。必须有用户管理权限才能使用。这个方式不止可以更新密码。db.changeUserPassword('username','newpassword')。必须有用户管理全出现才能使用
use admin
db.changeUserPassword("addmin", "admin123")
>
use admin
db.updateUser('addmin',{'pwd':'admin123'})
09、删除用户
use admin
db.dropUser("test")
>
use admin
db.runCommand({ dropUser: "test" })
数据库操作-Database
01、数据库命名规则
MongoDB 数据库的命名要符合 UTF-8 标准的字符串,同时要遵循下表所示的注意事项。
| 序号 | 注意事项 |
|---|---|
| 1 | 不能是空串 |
| 2 | 不得含有 /、\、?、$、空格、空字符等,基本只能使用 ASCII 中的字母和数字 |
| 3 | 区分大小写,建议全部小写 |
| 4 | 名称最多为 64 字节 |
| 5 | 不得使用保留的数据库名,如:admin、local、config |
注意:数据库最终会成为文件,数据库名就是文件的名称。
- 由于数据库名称在 MongoDB 中不区分大小写,因此数据库名称不能仅仅区别于字符。
- 对于在 Windows 上运行的 MongoDB,数据库名称不能包含以下字符:/、\、“、$、*、< >、:、|、? 。
- 对于在 UNIX 和 Linux 系统上运行的 MongoDB,数据库名称不能包含以下字符:/、\、。、”、$。
- 虽然 UTF-8 可以提供很多国家的语言的命名格式,在 MongoDB 数据库命名时也可以使用汉字作为数据库名,但是最好尽量采用英文字母、数字、字符等为主的命名格式。
示例:
正确的命名格式:myDB、my_NewDB、myDB12
错误的命名格式:.myDB、/123
保留数据库:MongoDB 系统保留的数据库如下:
| 库名 | 作用 |
|---|---|
| admin | 权限数据库,添加用户到该数据库中,该用户会自动继承数据库的所有权限 |
| local | 数据库中的数据永远不会被复制 |
| config | 分片时,config 数据库在内部使用,保存分子信息 |
| test | 默认数据库,可以用来做各种测试等 |
02、创建切换数据库
创建、打开、切换 数据库命令:use dbname
use
> use mydb
switched to db mydb
注意:
- 如果打开的这个数据库存在就是打开这个数据库。
- 如果打开的是一个不存在的数据库(没有这个数据库名字),那么就会创建一个同名的数据库。
- 创建一个新的数据库时,需要向数据库中创建集合并且插入一条数据,这个数据库才能创建成功!否则show dbs查询不到此数据库
示例:往集合中插入一条数据。可以不用先创建集合,直接往里添加数据即可:
# user 就是集合(表)名
db.user.insert({"name": "xiaoming"})
当命令执行后,数据库系统发现 user 是一个数据集合不存的,就自动创建一个集合,并随着数据的插入,数据库和集合也就真正的创建成功了。
要在不切换当前数据库访问其他的数据库使用 db.getSiblingDB(“db_name”) .xxx方法。
03、查看数据库
查看当前所在数据库(默认为test):db
查看所有数据库:show dbs
查看当前数据库相关信息(名称、文档个数、视图、索引、大小等):db.stats()
示例:
> db
test
> show dbs # 可以在任意当前数据库上执行该命令
admin 0.000GB # 保留数据库,admin
config 0.000GB # 保留数据库,config
local 0.000GB # 保留数据库,local
备注:为什么查询所有数据库时没有看到当前默认的test数据库呢?因为test数据库内没有数据,实际上不算真正意义上的存在
> db.stats() # 统计数据信息
{
"db" : "test", # 数据库名
"collections" : 0, # 集合数量
"views" : 0,
"objects" : 0, # 文档数量
"avgObjSize" : 0, # 平均每个文档的大小
"dataSize" : 0, # 数据占用空间大小,不包括索引,单位为字节
"storageSize" : 0, # 分配的存储空间
"totalSize" : 0, # 总共空间大小
"indexes" : 0, # 索引个数
"indexSize" : 0, # 索引占用空间大小
"scaleFactor" : 1,
"fileSize" : 0, # 物理存储文件的大小
"fsUsedSize" : 0,
"fsTotalSize" : 0,
"ok" : 1
}
04、删除数据库
删除当前所在的数据库:db.dropDatabase()
> db.dropDatabase()
{ "ok" : 1 }
注:删除后集合中的所以文档、以及相关的索引等都会被删除!!
05、查看帮助文档
数据库帮助命令
导入工具所有操作方法:
mongoexport --help导出工具所有操作方法:
mongoimport --help备份工具所有操作方法:
mongodump --help恢复工具所有操作方法:
mongorestore --help列出MongoDB数据库所有的操作方法:
db.help()列出MongoDB文档(表)所有的操作方法:
db.collection.help()
集合操作-Collection
01、集合命名规则
MongoDB 的集合就相当于 MySQL 的一个表 Table,集合是一组文档,是无模式的,集合名称要求符合 UTF-8 标准的字符串,同时要遵循下表所示的注意事项。
| 序号 | 注意事项 |
|---|---|
| 1 | 集合名不能是空串 |
| 2 | 不能含有空字符 \0 |
| 3 | 不能以“system.”开头,这是系统集合保留的前缀 |
| 4 | 集合名不能含保留字符“$” |
对于分别部署在 Windows、Linux、UNIX 系统上的 MongoDB,集合的命名方式与数据库命名方式一致。
02、集合创建
MongoDB 集合的创建有显式和隐式(推荐)两种方法。
1、显示创建集合函数:db.createCollection(name, options)
语法格式:db.createCollection(name, options)
name:要创建的集合名称
options:可选参数,指定有关内存大小及索引的选项
- options 可以是如下参数:
| 参数 | 类型 | 描述 |
|---|---|---|
| capped | Boolean | (可选)如果为 true,则启用封闭的集合。上限集合是固定大小的集合,它在达到其最大时自动覆盖其最旧的条目。如果指定 true,则还需要指定 size 参数 |
| autoindexid | Boolean | (可选)如果为 true,自动在 _id 字段创建索引。默认为false。 |
| size | 数字 | (可选)指定上限集合的最大大小(以字节为单位)如果 capped 为 true,那么还需要指定此字段的值 |
| max | 数字 | (可选)指定上限集合中允许的最大文档数 |
- 创建无参数的集合:
db.createCollection('day1')
- 创建带参数的集合:
# 创建名为 day2 的固定集合,集合空间大小为:2000000kb(大约1.9g),文档最大个数为:1000
db.createCollection('day2',{ capped:true, autoIndexId:true, size:2000000, max:1000 })
- 示例:
> db.createCollection('day1')
{ "ok" : 1 }
>
> db.createCollection('day2',{capped:true,autoIndexId:true,size:2000000,max:1000})
{
"note" : "The autoIndexId option is deprecated and will be removed in a future release",
"ok" : 1
}
> show collections
day1
day2
2、隐式创建集合(推荐):
当插入文档时,如果集合不存在,则 MongoDB会隐式地自动创建集合:
db.myDB.insert({"name": "tom"})
03、集合查询
MySQL 列出的所有表都可以使用 show tables。MongoDB 列出所有集合可以使用如下三种方式:
- show tables
- show collections
- db.getCollectionNames()
> db
test
>
> show tables
day1
day2
>
> show collections
day1
day2
>
> db.getCollectionNames()
[ "day1", "day2" ]
04、集合删除
集合删除(当前集合):db.collection.drop();
> db.day1.drop()
true
05、集合修改
集合重新命名:db.collection.renameCollection();
> db.students.renameCollection("student")
{ "ok" : 1 }
文档操作-Document
01、文档命名规则
文档是 MongoDB 中存储的基本单元,是一组有序的键值对集合。文档中存储的文档键的格式必须是符合 UTF-8 标准的字符串,同时要遵循以下注意事项:
- 不能包含
\0字符(空字符),因为这个字符表示键的结束; - 不能包含
$和.,因为.和$是被保留的,只能在特定环境下使用; - 键名区分大小写;
- 键的值区分类型(如字符串和整数等);
- 键不能重复,在一条文档里起唯一的作用。
注意:以上所有命名规范必须符合 UTF-8 标准的字符串,文档的键值对是有顺序的,相同的键值对如果有不同顺序,也是不同的文档。
示例:
- 例1:以下两组文档是不同的,因为值的类型不同。
{ "recommend" : "5" }
{ "recommend" : 5 }
-
例2:以下两组文档也是不同的,因为键名是区分大小写的。
{ "Recommend" : " 5 "}
{ "recommend" : "5" }
02、数据插入
注:插入数据时不需要专门去创建集合(表),因为插入数据时会自动创建集合!!!
save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,已使用 insertOne() 或 replaceOne() 来代替。
insert():若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据.
- db.collection.insert():在指定集合中插入一个或者多个文档
- db.collection.insertOne():在指定集合插入一个新文档
- db.collection.insertMany():在指定集合插入一个多个文档
1、insert() 方法
db.collection.insert()
在平时的使用当中,**db.collection.insert()**是我用得最多的文档插入方式,具体的语法格式如下:
db.collection.insert(
<document or array of documents>,
{
writeConcern: <document>,
ordered: <boolean>
}
)
参数说明:
- document:指定写入的文档,可以一个或多个
- writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求
- ordered:指定是否按顺序写入(可选),默认 true
- 当指定为true时,插入多个文档时将文档排序保存在一个数组中进行插入,如果其中有一个文档插入失败,则会导致数组中余下的文档不进行插入操作;
- 当指定为false时,插入多个文档时将文档不进行排序保存在一个数组中进行插入,如果其中有一个文档插入失败,则不影响数组中余下的文档进行插入操作。
如果插入的文档当中没有指定_id字段,则MongoDB会自动为文档生成具有唯一ObjectId值的字段_id。
示例:
// insert 插入一条数据
db.student.insert({"name": "zhangsan", "age": 28, addr: "ShenZhen"});
// insert 插入一条数据,并指定_id
db.student.insert({_id: 1, "name": "zhangsan", "age": 28, addr: "ShenZhen"});
// insert 插入多条数据,不进行排序
db.student.insert([
{"name": "zhangsan", "age": 32, addr: "GuangZhou"},
{"name": "wangwu", "age": 16, addr: "ShangHai"}
]);
// insert 插入多条数据,并进行排序
db.student.insert(
[
{"name": "zhangsan", "age": 32, addr: "GuangZhou"},
{"name": "wangwu", "age": 16, addr: "ShangHai"}
],
{ordered: false}
);
2、insertXxx() 方法
db.collection.insertOne() 与 db.collection.insertMany()
语法格式如下:
// 单行插入
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)
// 多行插入
db.collection.insertMany(
[ <document1> , <document2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
- 参数说明:
- document:要写入的文档。
- writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
- ordered:指定是否按顺序写入,默认 true,按顺序写入。
使用示例:
// 单行插入文档,关于_id字段指定与否也与db.collection.insert()一致
db.student.insertOne({"name": "zhangsan", "age": 28, addr: "ShenZhen"});
// 插入多条数据
db.student.insertMany([
{"name": "zhangsan", "age": 32, addr: "GuangZhou"},
{"name": "wangwu", "age": 16, addr: "ShangHai"}
]);
测试:关于返回确认信息
> # insert 插入一条数据
> db.student.insert({"name": "zhangsan", "age": 28, addr: "ShenZhen"});
WriteResult({ "nInserted" : 1 })
>
> # insert 插入多条数据
> db.student.insert([
... {"name": "zhangsan", "age": 32, addr: "GuangZhou"},
... {"name": "wangwu", "age": 16, addr: "ShangHai"}
... ]);
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 2,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
>
> # 插入1条数据
> db.student.insertOne({"name": "zhangsan", "age": 28, addr: "ShenZhen"});
{
"acknowledged" : true,
"insertedId" : ObjectId("5fd4c7676817e7a0fa646b85")
}
>
> # 插入多条数据
> db.student.insertMany([
... {"name": "zhangsan", "age": 32, addr: "GuangZhou"},
... {"name": "wangwu", "age": 16, addr: "ShangHai"}
... ]);
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5fd4c7706817e7a0fa646b86"),
ObjectId("5fd4c7706817e7a0fa646b87")
]
}
>
03、数据更新
- **db.collection.update()**:更新或替换集合中符合条件的一个或多个文档;
- **db.collection.updateOne()**:只更新集合中符合条件的第一个文档,即使有多个文档(版本3.2新增)
- **db.collection.updateMany()**:更新集合中所有符合条件的文档(版本3.2新增)
- **db.collection.replaceOne()**:替换除
_id字段以外的文档的所有内容
1、update() 方法
db.collection.update()
根据update指定的表达式可以修改文档中符合条件的字段或代替整个文档。具体的语法格式如下:
db.collection.update(
<query>, //查询表达式
<update>, //更新表达式
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // 版本4.2新增
}
)
参数说明:
query:更新文档的查询表达式;如果指定了参数
upsert: true并且集合中没有符合查询条件的文档,查询条件中有关于字段_id指定了.分隔符的,并不会插入新的文档;update:主要包含三种格式
- 1.更新文档:只包含更新操作符表达式;
- 2.替换文档:只包含
<field1>: <value1>对; - 3.聚合管道:版本4.2新增,详细参考官方文档。
upsert:当query查询条件没符合更新的文档,就新创建文档(可选),默认值为false;
multi:是否更新多个符合条件的文档(可选),默认值为false,只更新符合条件的第一个文档;
writeConcern:参考**db.collection.insert()**相同参数说明;
collation:指定校对规则(可选,版本3.4新增);
arrayFilters:文档数组更新过滤操作符(可选,版本3.6新增);详细参考:官方文档
hint:采用文档或字符串的形式指定适用于查询表达式的索引,如果索引不存在则报错(可选,版本4.2新增)。
使用示例:
使用示例将通过使用两种场景进行,一是没有使用参数选项upsert,二是使用参数选项upsert。
- 不使用选项upsert
// 测试数据
db.books.remove({});
db.books.insertMany([
{
"_id" : 1,
"item" : "TBD",
"stock" : 0,
"info" : { "publisher" : "1111", "pages" : 430 },
"tags" : [ "technology", "computer" ],
"ratings" : [ { "by" : "ijk", "rating" : 4 }, { "by" : "lmn", "rating" : 5 } ],
"reorder" : false
},
{
"_id" : 2,
"item" : "XYZ123",
"stock" : 15,
"info" : { "publisher" : "5555", "pages" : 150 },
"tags" : [ ],
"ratings" : [ { "by" : "xyz", "rating" : 5 } ],
"reorder" : false
}
]);
/* 使用选项参数 upsert: true
1、如果查询表达式找到匹配的文档,则执行更新操作;
2、如果查询表达式没有找到匹配的文档,则执行插入操作;
*/
db.books.update(
{ item: "ZZZ135" }, // 查询表达式
{ // 更新或替换文档
item: "ZZZ135",
stock: 5,
tags: [ "database" ]
},
{ upsert: true }
);
// 1.使用更新操作表达式
/* $set操作符
1、查询表达式指定需要更新的文档 _id;
2、$inc操作符: stock的字段值+5;
3、$set操作符: 替换item字段值,替换嵌入文档info的publisher字段值,替换tags字段值,替换数组ratings的第二个元素值
*/
db.books.update(
{ _id: 1 },
{
$inc: { stock: 5 },
$set: {
item: "ABC123",
"info.publisher": "2222",
tags: [ "software" ],
"ratings.1": { by: "xyz", rating: 3 }
}
}
);
更新之后的文档:
{
"_id" : 1,
"item" : "ABC123",
"stock" : 5,
"info" : { "publisher" : "2222", "pages" : 430 },
"tags" : [ "software" ],
"ratings" : [ { "by" : "ijk", "rating" : 4 }, { "by" : "xyz", "rating" : 3 } ],
"reorder" : false
}
// 2.为已存在的数组添加元素
// $push操作符: 为指定文档数组ratings添加一个元素
db.books.update(
{ _id: 2 },
{
$push: { ratings: { "by" : "jkl", "rating" : 2 } }
}
);
更新之后的文档:
{
"_id" : 2,
"item" : "XYZ123",
"stock" : 15,
"info" : {
"publisher" : "5555",
"pages" : 150
},
"tags" : [ ],
"ratings" : [
{ "by" : "xyz", "rating" : 5 },
{ "by" : "jkl", "rating" : 2 }
],
"reorder" : false
}
// 3.文档移除字段
// $unset操作符: 移除文档的指定字段,为_id:1文档移除tags字段
db.books.update( { _id: 1 }, { $unset: { tags: 1 } } );
更新后的文档:
{
"_id" : 1,
"item" : "TBD",
"stock" : 0,
"info" : {
"publisher" : "1111",
"pages" : 430
},
"ratings" : [ { "by" : "ijk", "rating" : 4 }, { "by" : "lmn", "rating" : 5 } ],
"reorder" : false
}
// 4.替换整个文档
// 替换_id:2的文档
db.books.update(
{ _id: 2 },
{
item: "XYZ123",
stock: 10,
info: { publisher: "2255", pages: 150 },
tags: [ "baking", "cooking" ]
}
);
更新后的文档:
{
"_id" : 2,
"item" : "XYZ123",
"stock" : 10,
"info" : { "publisher" : "2255", "pages" : 150 },
"tags" : [ "baking", "cooking" ]
}
// 5.更新多个文档
db.books.update(
{ stock: { $lte: 10 } },
{ $set: { reorder: true } },
{ multi: true }
);
更新后的全部文档:
[
{
"_id" : 1,
"item" : "ABC123",
"stock" : 5,
"info" : {
"publisher" : "2222",
"pages" : 430
},
"ratings" : [ { "by" : "ijk", "rating" : 4 }, { "by" : "xyz", "rating" : 3 } ],
"reorder" : true
}
{
"_id" : 2,
"item" : "XYZ123",
"stock" : 10,
"info" : { "publisher" : "2255", "pages" : 150 },
"tags" : [ "baking", "cooking" ],
"reorder" : true
}
]
- 使用upserts选项
/* 使用选项参数 upsert: true
1、如果查询表达式找到匹配的文档,则执行更新操作;
2、如果查询表达式没有找到匹配的文档,则执行插入操作;
*/
// 1.插入未符合更新条件的文档
db.books.update(
{ item: "ZZZ135" },
{
item: "ZZZ135",
stock: 5,
tags: [ "database" ]
},
{ upsert: true }
);
因为集合并未满足条件的文档,则插入的文档为:
{
"_id" : ObjectId("5da78973835b2f1c75347a83"),
"item" : "ZZZ135",
"stock" : 5,
"tags" : [ "database" ]
}
// 2.插入未符合更新条件并且基于更新操作符的文档
// 如果没有符合更新查询条件,并且使用的是更新操作符,则会基于当前的查询条件和更新操作符字段插入新的文档
db.books.update(
{ item: "BLP921" },
{
$set: { reorder: false },
$setOnInsert: { stock: 10 }
},
{ upsert: true }
);
新插入的文档为:
{
"_id" : ObjectId("5da79019835b2f1c75348a0a"),
"item" : "BLP921",
"reorder" : false,
"stock" : 10
}
// 3.插入未符合更新条件并且基于聚合管道的文档
// 关于聚合管道请参考官方文档:https://docs.mongodb.com/manual/reference/method/db.collection.update/#update-with-aggregation-pipeline
// 4.插入未符合更新条件并且同时联合多文档操作符的文档
如果不符合查询条件,则只会插入单个文档
db.books.update(
{ "info.publisher": "Self-Published" },
{
$set: { reorder: false, tags: [ "literature", "hardcover" ], stock: 25 }
},
{ upsert: true, multi: true }
);
新插入的文档:
{
"_id" : ObjectId("5db337934f670d584b6ca8e0"),
"info" : { "publisher" : "Self-Published" },
"reorder" : false,
"stock" : 25,
"tags" : [ "literature", "hardcover" ]
}
2、updateXxx() 方法
db.collection.updateOne() 与 db.collection.updateMany()
根据update指定的参数可以修改文档中符合条件的字段或代替整个文档,与**db.collection.update()**不同的是每次只更新单个文档。
根据update指定的参数可以修改文档中符合条件的字段或代替整个文档,与**db.collection.updateOne()**不同的是更新所有符合条件的文档。
语法格式如下:
// 更新单个文档语法:
db.collection.updateOne(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string>
}
)
// 更新单个或多个文档语法:
db.collection.updateMany(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string>
}
)
参数说明:参考**db.collection.update()**的参数说明。
使用示例:
// 参考db.collection.update()
db.collection.replaceOne( filter , replacement , options )
db.collection.replaceOne(
<filter>,
<replacement>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>
}
)
参数说明:参考**db.collection.update()**的参数说明。
使用示例:
// 使用一个新的文档来替换name为B的文档
db.user.replaceOne(
{ name: "B" },
{ name: "newB", age: 8, addr: "GuangZhou"}
)
04、数据删除
- **db.collection.deleteOne()**:只删除集合中符合条件的一个文档
- **db.collection.deleteMany()**:删除集合中所有符合条件的文档
- **db.collection.remove()**:删除集合中符合条件的一个或多个文档(
已废弃)
1、deleteXxx() 方法
db.collection.deleteOne() 与 db.collection.deleteMany()
根据filter选项条件删除集合中的单个或多个文档,具体语法格式如下:
// 删除单个语法
db.collection.deleteOne(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
// 删除单个或者多个语法
db.collection.deleteMany(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
参数说明:
- filter:指定基于查询表达式的过滤条件,关于查询表达式可以查看
db.collecion.find()中的<query>; - writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
- collation:指定校对规则(可选,版本3.4新增);
使用示例:
// 删除指定条件的单个文档
db.user.deleteOne( { "_id" : 1 } );
{ "acknowledged" : true, "deletedCount" : 1 }
// 删除指定条件的多个文档
db.user.deleteMany( {"addr" : "GuangZhou"} );
{ "acknowledged" : true, "deletedCount" : 2 }
2、remove() 方法
db.collection.remove()
根据filter选项条件删除集合中的单个或多个文档,具体语法格式如下:
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query:必选项,是设置删除的文档的条件。
- justOne:布尔型的可选项,默认为false,删除符合条件的所有文档,如果设为 true,则只删除一个文档。
- writeConcem:可选项,设置抛出异常的级别。
使用示例:
// remove 删除全部
db.day.remove({})
// remove 条件删除
db.day.remove({age:10})
注意:
此方法已经过时,官方推荐使用deleteOne和deleteMany函数来实现删除操作。且remove()函数并不会真正的释放掉存储空间,需要删除后,再用管理员权限的账户执行db.repairDatabase()函数来释放存储空间!
05、数据查询
查询(Read Operations)读操作,是对集合中已存在的文档进行查询,即对应关系型数据库当中的select操作,MongoDB提供以下几种主要查询文档方法:
- db.collection.find():查询指定集合中满足条件的一个或多个文档和视图;
- db.collection.findOne():查询指定集合中满足条件的第一个文档
- db.collection.findXxx.pretty():以格式化方式展现,通过
pretty()方法
1、插入测试数据
插入测试数据
db.user.insert([
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" },
{ "_id" : 2, "name" : "XiaoMing", "age" : 27, "addr" : "GuangZhou" },
{ "_id" : 3, "name" : "LaoWan", "age" : 30, "addr" : "BeiJing" },
{ "_id" : 4, "name" : "WangWu", "age" : 32, "addr" : "ShangHai" },
{ "_id" : 5, "name" : "ZhaoSi", "age" : 28, "addr" : "ShenZhen" },
{ "_id" : 6, "name" : "LiSi", "age" : 20, "addr" : "HangZhou" }
])
此时 user 表中的数据列表如下:
| id | name | age | addr |
|---|---|---|---|
| 1 | ZhangSan | 25 | ShenZhen |
| 2 | XiaoMing | 27 | GuangZhou |
| 3 | LaoWan | 30 | BeiJing |
| 4 | WangWu | 32 | ShangHai |
| 5 | ZhaoSi | 28 | ShenZhen |
| 6 | LiSi | 20 | HangZhou |
2、查询数据方法
db.collection.find() 与 db.collection.findOne()
db.collection.find() :是使用频率最高的方法了,可以用来查询数据库集合当中的文档
**db.collection.findOne()**:方法显示符合条件查询的第一条文档
语法格式如下:
db.collection.find(<query>, <projection>)
db.collection.findOne(<query>, <projection>)
- query:查询表达式;
- projection:指定查询结果集中需要显示的字段。
- Col_name:1|true 代表显示该字段;
- Col_name:0 | false 代表不显示该字段。
_id 字段是默认显示的,如果不想显示,则显式指定 {“_id” : 0}
使用示例:
// 查询全部数据的两种方式
db.collection.find()
db.collection.find({})
// 查询单个文档:
db.collection.findOne()
//============================查询所有文档数据============================
> db.user.find()
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" }
{ "_id" : 2, "name" : "XiaoMing", "age" : 27, "addr" : "GuangZhou" }
{ "_id" : 3, "name" : "LaoWan", "age" : 30, "addr" : "BeiJing" }
{ "_id" : 4, "name" : "WangWu", "age" : 32, "addr" : "ShangHai" }
{ "_id" : 5, "name" : "ZhaoSi", "age" : 28, "addr" : "ShenZhen" }
{ "_id" : 6, "name" : "LiSi", "age" : 20, "addr" : "HangZhou" }
//============================查询单个文档数据============================
> db.user.findOne({addr: "ShenZhen"})
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" }
3、查询指定字段
查询返回指定字段
db.getCollection('user').find(用于过滤记录的字典,用于限定字段的字典)
- 如果值为0,则表示在全部字段中剔除值为0的这些字段并返回。
- 如果值为1,则表示只返回值为1的这些字段。(默认都为1,显示)
使用示例:
// 只显示name字段和age字段
db.user.find({},{ name : 1 , age : 1 }).limit(1)
{ "_id" : 1, "name" : "ZhangSan", "age" : 25 }
// 不显示_id字段和name字段,其他字段都显示
db.user.find({},{ _id : 0 , name : 0 }).limit(1)
{ "age" : 25, "addr" : "ShenZhen" }
注意:不能0(显示字段)和1(剔除字段)在同一个语句中一起使用,不然会报错
4、指定范围查询
范围操作符
| 名称 | 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|---|
| $eq | 等于 | {:} | db.col.find({“by”:”Mongo教程”}) | where by = ‘Mongo教程’ |
| $lt | 小于 | {:{$lt:}} | db.col.find({“likes”:{$lt:50}}) | where likes < 50 |
| $te | 小于或等于 | {:{$lte:}} | db.col.find({“likes”:{$lte:50}}) | where likes <= 50 |
| $gt | 大于 | {:{$gt:}} | db.col.find({“likes”:{$gt:50}}) | where likes > 50 |
| $gte | 大于或等于 | {:{$gte:}} | db.col.find({“likes”:{$gte:50}}) | where likes >= 50 |
| $ne | 不等于 | {:{$ne:}} | db.col.find({“likes”:{$ne:50}}) | where likes != 50 |
| $in | 指定值在数组中 | {:{$in:[]}} | db.col.find({“likes”:{$in:[50]}}) | where likes in (50) |
| $nin | 指定值不在数组中 | {:{$nin:[]}} | db.col.find({“likes”:{$nin:[50]}}) | where likes not in (50) |
使用示例:
// $eq:等值查询 SQL: SELECT * FROM user WHERE name = "XiaoHei";
db.user.find( { name: "ZhangSan" } )
// $ne:等值查询 SQL: SELECT * FROM user WHERE name != "XiaoHei";
db.user.find( { name: {$ne: "XiaoHei"} } )
// $gt:范围查询(以大于为例) SQL: SELECT * FROM user WHERE age > 30;
db.user.find( { age: {$gt: 30} } )
// $gte、$lt、$lte 同$gt
// $in:或查询,可使用or代替 SQL: SELECT * FROM user WHERE addr in ("ShenZhen", "GuangZhou")
db.user.find( { addr: { $in: [ "ShenZhen", "GuangZhou" ] } } )
// $nin:SQL: SELECT * FROM user addr not in ("BeiJing")
db.user.find( { addr: { $nin: [ "BeiJing"] } } )
5、逻辑判断查询
逻辑操作符
| 名称 | 说明 |
|---|---|
| $and | 指定查询同时满足多个条件查询子句(默认) |
| $not | 指定查询不满足条件查询子句 |
| $or | 指定查询满足其中某个条件查询子句 |
| $nor | 指定查询无法满足多个条件查询子句 |
使用实例:
// $and: 逻辑与查询 SQL: SELECT * FROM user WHERE addr = "ShenZhen" AND age < 30;
db.user.find( { $and: [ { addr: { $eq: "ShenZhen" }, age: { $lt: 30 } } ] } )
// $and: 或者(一般这种形式更加常用,$and 和 $eq 默认可以省略)
db.user.find( { addr: "ShenZhen", age: { $lt: 30 } } )
// $not: 不符合查询 SQL: SELECT * FROM user WHERE addr <> "GuangZhou";
db.user.find( { addr: { $not: { $eq: "GuangZhou" } } } )
// $or: 逻辑或查询 SQL: SELECT * FROM user WHERE addr = "GuangZhou" OR age < 30;
db.user.find( { $or: [ { addr: "GuangZhou" }, { age: { $lt: 30 } } ] } )
/*
$nor: 无法同时满足多个条件查询,字段不存在时也符合
SQL: SELECT * FROM user WHERE addr <> "GuangZhou" AND age > 30;
符合以下条件之一都会出现在结果集中:
1.文档包含addr和age字段并且符合条件;
2.文档包含addr字段并且符合条件,不包含age字段;
3.文档不包含addr字段,包含age字段并且符合条件;
4.文档不包含addr字段和age字段。
*/
db.user.find( { $nor: [ { addr: { $ne: "GuangZhou" } }, { age: { $gt: 30 } } ] } )
6、元素操作符查询
元素操作符
| 名称 | 说明 |
|---|---|
| $exists | 指定查询文档是否有对应的字段 |
| $type | 指定查询文档的某个字段是否是对应类型 |
使用示例:
// $exists: 是否存在指定字段查询,返回所有存在该字段的数据
db.user.find( { name: { $exists: true } } )
// $type: 字段是否是指定类型查询,返回所有age字段为double的数据
db.user.find( { "age": { $type: "double" } } )
$type 可以用来根据数据类型查找数据,比如我想要查找x类型为数字的文档,如下:
db.user.find( { "age": { $type: 1 } } )
1表示数字,其他数据类型对应的数字参见下表。
| 类型 | 对应数字 | 别名 |
|---|---|---|
| Double1 | 1 | double |
| String | 2 | string |
| Object | 3 | object |
| Array | 4 | array |
| Binary data | 5 | binData |
| Undefined | 6 | undefined(弃用) |
| ObjectId | 7 | objectId |
| Boolean | 8 | bool |
| Date | 9 | date |
| Null | 10 | null |
| Regular Expression | 11 | regex |
| DBPointer | 12 | dbPointer |
| JavaScript | 13 | javascript |
| Symbol | 14 | symbol |
| JavaScript(with scope) | 15 | javascriptWithScope |
| 32-bit integer | 16 | int |
| Timestamp | 17 | timestamp |
| 64-bit integer | 18 | long |
| Min key | -1 | minKey |
| Max key | 127 | maxKey |
7、特定类型查询
null 类型查询
null的查询稍微有点不同,假如我想查询age为null的数据,如下:
db.user.find({age:null})
这样不仅会查出age为null的文档,也会查出所有没有age字段的文档,如果只想查询z为null的字段,那就再多加一个条件,判断一下z这个字段存在不,如下:
db.user.find({age:{$in:[null],$exists:true}})
正则表达式查询
这里的正则表达式语法和JavaScript中的正则表达式语法一致,比如查询所有key为name,value以Li开始的文档且不区分大小写:
db.user.find({name:/^(Li)(.[a-zA-Z0-9])+/i})
数组查询
假设我有一个数据集如下:
db.books.insert([
{"_id" : 1, "books" : ["三国演义", "红楼梦", "水浒传"]},
{"_id" : 2, "books" : ["三国演义", "西游记", "水浒传"]},
{"_id" : 3, "books" : [ "西游记", "水浒传"]},
])
> db.books.find()
{ "_id" : 1, "books" : [ "三国演义", "红楼梦", "水浒传" ] }
{ "_id" : 2, "books" : [ "三国演义", "西游记", "水浒传" ] }
{ "_id" : 3, "books" : [ "西游记", "水浒传" ] }
查询books中含有三国演义的所有文档,如下:
db.books.find({books:"三国演义"})
{ "_id" : 1, "books" : [ "三国演义", "红楼梦", "水浒传" ] }
{ "_id" : 2, "books" : [ "三国演义", "西游记", "水浒传" ] }
如果要查询既有三国演义又有红楼梦的文档,可以使用$all,如下:
db.books.find({books:{$all:["三国演义","红楼梦"]}})
{ "_id" : 1, "books" : [ "三国演义", "红楼梦", "水浒传" ] }
当然我们也可以使用精确匹配,比如查询books为"三国演义","红楼梦", "水浒传"的数据,如下:
db.books.find({books:["三国演义","红楼梦", "水浒传"]})
{ "_id" : 1, "books" : [ "三国演义", "红楼梦", "水浒传" ] }
不过这种就会一对一的精确匹配。也可以按照下标匹配,比如我想查询数组中下标为2的项的为"水浒传"的文档,如下:
db.books.find({"books.2":"水浒传"})
{ "_id" : 1, "books" : [ "三国演义", "红楼梦", "水浒传" ] }
{ "_id" : 2, "books" : [ "三国演义", "西游记", "水浒传" ] }
也可以按照数组长度来查询,比如我想查询数组长度为3的文档:
db.books.find({books:{$size:2}})
{ "_id" : 3, "books" : [ "西游记", "水浒传" ] }
如果想查询数组中的前两条数据,可以使用$slice,如下:
db.books.find({},{books:{$slice:2}})
{ "_id" : 1, "books" : [ "三国演义", "红楼梦" ] }
{ "_id" : 2, "books" : [ "三国演义", "西游记" ] }
{ "_id" : 3, "books" : [ "西游记", "水浒传" ] }
注意这里要写在find的第二个参数的位置。2表示数组中前两个元素,-2表示从后往前数两个元素。也可以截取数组中间的元素,比如查询数组的第二个到第四个元素:
db.books.find({},{books:{$slice:[1,3]}})
{ "_id" : 1, "books" : [ "红楼梦", "水浒传" ] }
{ "_id" : 2, "books" : [ "西游记", "水浒传" ] }
{ "_id" : 3, "books" : [ "水浒传" ] }
数组中的与的问题也值得说一下,假设我有如下数据:
{
"_id" : ObjectId("59f208bc7b00f982986c669c"),
"x" : [
5.0,
25.0
]
}
我想将数组中value取值在(10,20)之间的文档获取到,如下操作:
db.sang_collect.find({x:{$lt:20,$gt:10}})
此时上面这个文档虽然不满足条件却依然被查找出来了,因为5<20,而25>10,要解决这个问题,我们可以使用$elemMatch,如下:
db.sang_collect.find({x:{$elemMatch:{$lt:20,$gt:10}}})
$elemMatch要求MongoDB同时使用查询条件中的两个语句与一个数组元素进行比较。
嵌套文档查询
嵌套文档有两种查询方式,比如我的数据如下:
{
"_id" : ObjectId("59f20c9b7b00f982986c669f"),
"x" : 1.0,
"y" : {
"z" : 2.0,
"k" : 3.0
}
}
想要查询上面这个文档,我的查询语句如下:
db.sang_collect.find({y:{z:2,k:3}})
但是这种写法要求严格匹配,顺序都不能变,假如写成了db.sang_collect.find({y:{k:3,z:2}}),就匹配不到了,因此这种方法不够灵活,我们一般推荐的是下面这种写法:
db.sang_collect.find({"y.z":2,"y.k":3})
这种写法可以任意颠倒顺序。
8、评估操作符查询
评估操作符:参考官方文档:https://docs.mongodb.com/manual/reference/operator/query-evaluation/
| 名称 | 说明 |
|---|---|
| $expr | 为同一个文档中的字段指定表达式并且符合条件的查询,比如比较同一文档当中两个字段的值 |
| $mod | 为字段值取模并且符合条件的查询 |
为了更好的使用这两个主要的操作符,额外创建测试文档数据:
db.monthlyBudget.insertMany([
{ "_id" : 1, "category" : "food", "budget": 400, "spent": 450 },
{ "_id" : 2, "category" : "drinks", "budget": 100, "spent": 150 },
{ "_id" : 3, "category" : "clothes", "budget": 100, "spent": 50 },
{ "_id" : 4, "category" : "misc", "budget": 500, "spent": 300 },
{ "_id" : 5, "category" : "travel", "budget": 200, "spent": 650 }
]);
使用示例:
// $expr: 允许使用聚合表达式,这里以$gt为例,更多表达式参考:
// https://docs.mongodb.com/manual/meta/aggregation-quick-reference/#aggregation-expressions
db.monthlyBudget.find( { $expr: { $gt: [ "$spent" , "$budget" ] } } )
// $mod: 对字段所在值进行取模运算,显示符合条件的查询,如qty字段值对4取模,并且余数为0
db.inventory.find( { qty: { $mod: [ 4, 0 ] } } )
9、游标方法查询
游标这个概念在很多地方都有,Java中JDBC里的ResultSet,Android中的Cursor等等都是,MongoDB中也有类似的概念。当我们调用find方法时,就可以返回一个游标。MongoDB 游标的使用:
| 方法名 | 作用 |
|---|---|
| hasNext | 判断是否有更多的文档 |
| next | 用来获取下一条文档 |
| count | 查询的结果为文档的总数量 |
| limit | 限制查询结果返回数量 |
| skip | 跳过指定数目的文档 |
| sort | 对查询结果进行排序 |
| distinct | 对查询结果进行去重 |
| toArray | 将查询结构放到数组中 |
| objsLeftlnBatch | 查看当前批次剩余的未被迭代的文档数量 |
| addOption | 为游标设置辅助选项,修改游标的默认行为 |
| hint | 为查询强制使用指定索引 |
| explain | 用于获取查询执行过程报告 |
| snapshot | 对查询结果使用快照 |
查询结果修饰
// 1.查询当前集合数据量
db.collection.find().count()
// 2.查询集合前几条数据
db.collection.find().limit(number)
// 3.限定跳过前几条结果
db.collection.find().skip(number)
// 4.对查询结果进行排序,1为升序,-1为降序
db.collection.find().sort({key, 1或-1})
// 5.对查询结果进行去重
db.collection.find().distinct()
// 6.将查询结构放到数组中
db.collection.find().toArray()
使用示例:
// 相当于select count(1) from user
> db.user.find().count()
6
// 查询前 1 条数据
// 相当于:SELECT * FROM user limit 10
> db.user.find().limit(1)
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" }
// 查询第 5 条以后的数据
> db.user.find().skip(5)
{ "_id" : 6, "name" : "LiSi", "age" : 20, "addr" : "HangZhou" }
/*
* 查询 10 到 20 之间的数据
* 列表分页
* limit:就是 pageSize
* skip :就是第几页 * pageSize
*/
> db.user.find().limit(20).skip(10);
// 查询某个结果集的记录条数(统计数量)
// 相当于:select count(*) from user where age >= 18;
db.user.find({age: {$gte: 18}}).count();
// 如果要返回限制之后的记录数量,要使用 count(true)或者 count(非 0)
db.user.find().limit(20).skip(10).count(true);
// 1为升序,-1为降序
> db.user.find().sort({"age": -1});
{ "_id" : 4, "name" : "WangWu", "age" : 32, "addr" : "ShangHai" }
{ "_id" : 3, "name" : "LaoWan", "age" : 30, "addr" : "BeiJing" }
{ "_id" : 5, "name" : "ZhaoSi", "age" : 28, "addr" : "ShenZhen" }
{ "_id" : 2, "name" : "XiaoMing", "age" : 27, "addr" : "GuangZhou" }
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" }
{ "_id" : 6, "name" : "LiSi", "age" : 20, "addr" : "HangZhou" }
> db.user.distinct('age', { 'age':{'$gte':25 } } )
[ 25, 27, 28, 30, 32 ]
// 将查询结构放到数组中
> db.user.find().toArray();
[
{
"_id" : 1,
"name" : "ZhangSan",
"age" : 25,
"addr" : "ShenZhen"
},
{
"_id" : 2,
"name" : "XiaoMing",
"age" : 27,
"addr" : "GuangZhou"
},
{
"_id" : 3,
"name" : "LaoWan",
"age" : 30,
"addr" : "BeiJing"
},
{
"_id" : 4,
"name" : "WangWu",
"age" : 32,
"addr" : "ShangHai"
},
{
"_id" : 5,
"name" : "ZhaoSi",
"age" : 28,
"addr" : "ShenZhen"
},
{
"_id" : 6,
"name" : "LiSi",
"age" : 20,
"addr" : "HangZhou"
}
]
06、聚合查询
MongoDB聚合框架(Aggregation Framework)是一个计算框架,它可以:
- 可作用在一个 或 几个集合上
- 对集合中的数据进行一系列的运算
- 可将数据转化为所期望数据形式,如(数学计算,统计,类型,格式处理等)
对效果而言,聚合查询相录于传统SQL查询中的,ORDER BY,GROUP BY,LIMIT,LEFT OUTER JOIN,AS等!
- 聚合查询对照:(MongoDB 与 传统数据库 比对)
| 步骤 | 作用 | SQL等价运算符 |
|---|---|---|
| $match | 过滤 | where / having |
| $group | 分组 | group by |
| $project | 投影(别名) | as |
| $limit | 结果限制 | limit |
| $skip | 结果限制 | skip |
| $sort | 排序 | order by |
| $lookup | 左外连接(多表操作) | left outer join |
| $graphLookup | 图搜索 | N/A |
| $facet | 分面搜索 | N/A |
| $bucket | 分面搜索 | N/A |
| $unwind | 展开数组 | N/A |
Aggregate简介
db.collection.aggregate() 是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
通过这张图,可以了解Aggregate处理的过程:
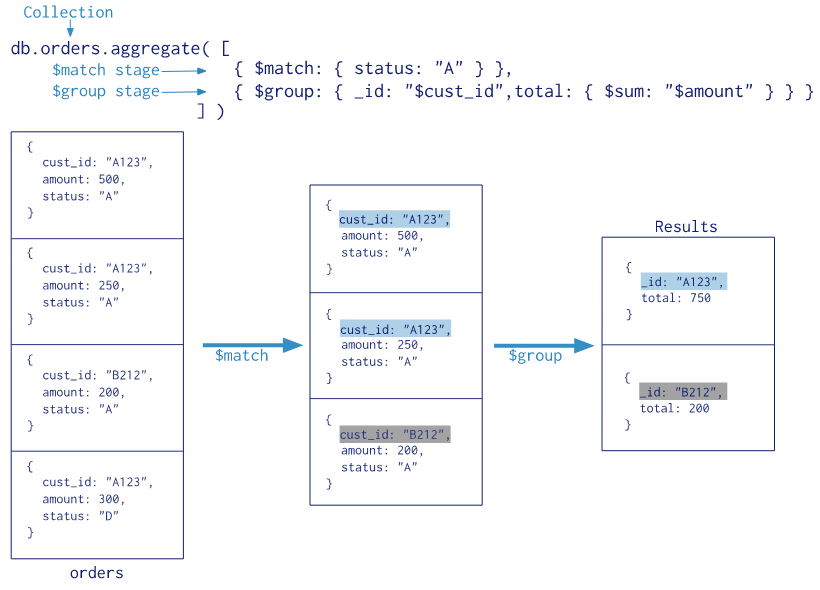
db.user.aggregate([
{ $match : { age : 20 } }, ==》$match stage
{ $group: { _id: '$addr', total: { $sum: '$age' } } } ==》$group stage
])
====================================================================
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" }
{ "_id" : 2, "name" : "XiaoMing", "age" : 27, "addr" : "ShenZhen" }
{ "_id" : 3, "name" : "LaoWan", "age" : 30, "addr" : "BeiJing" }
{ "_id" : 4, "name" : "WangWu", "age" : 32, "addr" : "ShangHai" }
{ "_id" : 5, "name" : "ZhaoSi", "age" : 28, "addr" : "GuangZhou" }
{ "_id" : 6, "name" : "LiSi", "age" : 30, "addr" : "HangZhou" }
{ "_id" : 7, "name" : "KaiFa", "age" : 20, "addr" : "HangZhou" }
{ "_id" : 8, "name" : "QianDuan", "age" : 40, "addr" : "HangZhou" }
{ "_id" : 9, "name" : "YunWei", "age" : 20, "addr" : "GuangZhou" }
{ "_id" : 10, "name" : "CeSi", "age" : 20, "addr" : "GuangZhou" }
===================================================================
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
$match
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
====================================================================
{ "_id" : 7, "name" : "KaiFa", "age" : 20, "addr" : "HangZhou" }
{ "_id" : 9, "name" : "YunWei", "age" : 20, "addr" : "GuangZhou" }
{ "_id" : 10, "name" : "CeSi", "age" : 20, "addr" : "GuangZhou" }
====================================================================
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
$group
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
===========================Results==================================
{ "_id" : "HangZhou", "total" : 20 }
{ "_id" : "GuangZhou", "total" : 40 }
===========================Results==================================
1、db.collection.aggregate() 可以用多个构件创建一个管道,对于一连串的文档进行处理。这些构件包括:筛选操作的match、映射操作的project、分组操作的group、排序操作的sort、限制操作的limit、和跳过操作的skip。
2、db.collection.aggregate()使用了MongoDB内置的原生操作,聚合效率非常高,支持类似于SQL Group By操作的功能,而不再需要用户编写自定义的JavaScript例程。
3、 每个阶段管道限制为100MB的内存。如果一个节点管道超过这个极限,MongoDB将产生一个错误。为了能够在处理大型数据集,可以设置allowDiskUse为true来在聚合管道节点把数据写入临时文件。这样就可以解决100MB的内存的限制。
4、db.collection.aggregate()可以作用在分片集合,但结果不能输在分片集合,MapReduce可以 作用在分片集合,结果也可以输在分片集合。
5、db.collection.aggregate()方法可以返回一个指针(cursor),数据放在内存中,直接操作。跟Mongo shell 一样指针操作。
6、db.collection.aggregate()输出的结果只能保存在一个文档中,BSON Document大小限制为16M。可以通过返回指针解决,版本2.6中后面:DB.collect.aggregate()方法返回一个指针,可以返回任何结果集的大小。
Aggregate语法
db.collection.aggregate(pipeline, options)
参数说明:
| 参数 | 类型 | 描述 |
|---|---|---|
| pipeline | array | 一系列数据聚合操作或阶段。详见聚合管道操作符 在版本2.6中更改:该方法仍然可以将流水线阶段作为单独的参数接受,而不是作为数组中的元素;但是,如果不将管道指定为数组,则不能指定options参数 |
| options | document | 可选。 aggregate()传递给聚合命令的其他选项。 2.6版中的新增功能:仅当将管道指定为数组时才可用。 |
注意:使用db.collection.aggregate()直接查询会提示错误,但是传一个空数组如db.collection.aggregate([])则不会报错,且会和find一样返回所有文档。
pipeline有很多stage,但这里我只记录我经常用到的几个,如果后续用到再补充。stage详见官网。
接下来介绍这几个常用的stage
aggregate常用pipeline stage介绍
准备测试数据:
db.getCollection("user").drop()
db.getCollection("user").insert([
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" },
{ "_id" : 2, "name" : "XiaoMing", "age" : 27, "addr" : "ShenZhen" },
{ "_id" : 3, "name" : "LaoWan", "age" : 30, "addr" : "BeiJing" },
{ "_id" : 4, "name" : "WangWu", "age" : 32, "addr" : "ShangHai" },
{ "_id" : 5, "name" : "ZhaoSi", "age" : 28, "addr" : "GuangZhou" },
{ "_id" : 6, "name" : "LiSi", "age" : 30, "addr" : "HangZhou" },
{ "_id" : 7, "name" : "KaiFa", "age" : 20, "addr" : "HangZhou" },
{ "_id" : 8, "name" : "QianDuan", "age" : 40, "addr" : "HangZhou" },
{ "_id" : 9, "name" : "YunWei", "age" : 20, "addr" : "GuangZhou" },
{ "_id" : 10, "name" : "CeSi", "age" : 20, "addr" : "GuangZhou" }
])
操作示例:**$match、$count、$limit、$skip、$sort、$project**
// 执行:
// 1)$match 阶段排除age小于等于80的文档,将大于80的文档传到下个阶段
// 2)$count阶段返回聚合管道中剩余文档的计数,并将该值分配给名为age_count的字段。
> db.getCollection("user").aggregate([
{ $match : { age : { $gt: 25} } },
{ $count : "age_count" }
])
{ "age_count" : 6 }
// 1.$skip和$limit 查询6-10条数据
// 2.首先按照age降序排序,然后按照_id降序排序
// 3.给name、age、addr 字段取别名
> db.getCollection("user").aggregate([
{ $skip : 5 },
{ $limit : 9 },
{ $sort : { age : -1 , _id : -1}},
{ $project : {
'姓名': '$name',
'年龄': '$age',
'地址': '$addr'
}}
])
{ "_id" : 8, "姓名" : "QianDuan", "年龄" : 40, "地址" : "HangZhou" }
{ "_id" : 6, "姓名" : "LiSi", "年龄" : 30, "地址" : "HangZhou" }
{ "_id" : 10, "姓名" : "CeSi", "年龄" : 20, "地址" : "GuangZhou" }
{ "_id" : 9, "姓名" : "YunWei", "年龄" : 20, "地址" : "GuangZhou" }
{ "_id" : 7, "姓名" : "KaiFa", "年龄" : 20, "地址" : "HangZhou" }
聚合分组(**$group**)的表达式:
语法:
{
$group:
{
_id: <expression>,
<field1>: {
<accumulator1> : <expression1>
},
<field2>: {
<accumulator2> : <expression2>
},
...
}
}
- _id字段是必填的,但是可以指定_id值为null来为整个输入文档计算累计值。
- 剩余的计算字段是可选的,并使用<accumulator>运算符进行计算。
- _id和<accumulator>\表达式可以接受任何有效的表达式。
示例:
[
{
$group: {
_id: {
addr: '$addr'
},
totalCount: {
$sum: 1
}
}
}
]
$group是固定的,表示这里一个分组聚合操作。_id表示需要根据哪一些列进行聚合,其实一个JSON对象,其key/value对分别表示结果列的别名以及需要聚合的的数据库列。totaoCount表示聚合列的列名。$sum表示要进行的聚合操作,后面的1表示每次加1。
accumulator操作符
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.col.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$sum : “$likes”}}}]) |
| $avg | 计算平均值 | db.col.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$avg : “$likes”}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.col.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$min : “$likes”}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.col.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$max : “$likes”}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.col.aggregate([{$group : {_id : “$by_user”, url : {$push: “$url”}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.col.aggregate([{$group : {_id : “$by_user”, url : {$addToSet : “$url”}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.col.aggregate([{$group : {_id : “$by_user”, first_url : {$first : “$url”}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.col.aggregate([{$group : {_id : “$by_user”, last_url : {$last : “$url”}}}]) |
使用示例:**$sum、$avg、$max、$min、$first、$last**
// 地址分组统计:个数、总和、平均数、最大、最小、首个、最后一个
db.getCollection("user").aggregate([{
$group: {
_id: { userAddr: '$addr' },
totalCount: { $sum: 1 },
ageSum: { $sum: '$age' },
ageAvg: { $avg: '$age' },
ageMax: { $max: '$age' },
ageMin: { $min: '$age' },
ageFirst: { $first: '$age' },
ageLast: { $last: '$age' }
}
}])
// 返回结果
{ "_id" : { "userAddr" : "HangZhou" }, "totalCount" : 3, "ageSum" : 90, "ageAvg" : 30, "ageMax" : 40, "ageMin" : 20, "ageFirst" : 30, "ageLast" : 40 }
{ "_id" : { "userAddr" : "BeiJing" }, "totalCount" : 1, "ageSum" : 30, "ageAvg" : 30, "ageMax" : 30, "ageMin" : 30, "ageFirst" : 30, "ageLast" : 30 }
{ "_id" : { "userAddr" : "ShenZhen" }, "totalCount" : 2, "ageSum" : 52, "ageAvg" : 26, "ageMax" : 27, "ageMin" : 25, "ageFirst" : 25, "ageLast" : 27 }
{ "_id" : { "userAddr" : "ShangHai" }, "totalCount" : 1, "ageSum" : 32, "ageAvg" : 32, "ageMax" : 32, "ageMin" : 32, "ageFirst" : 32, "ageLast" : 32 }
{ "_id" : { "userAddr" : "GuangZhou" }, "totalCount" : 3, "ageSum" : 68, "ageAvg" : 22.666666666666668, "ageMax" : 28, "ageMin" : 20, "ageFirst" : 28, "ageLast" : 20 }
>
// 指定组_id为null,计算集合中所有文档的总价格和平均数量以及计数:
db.getCollection("user").aggregate([{
$group: {
_id: null,
totalCount: { $sum: 1 },
ageSum: { $sum: '$age' },
ageAvg: { $avg: '$age' },
ageMax: { $max: '$age' },
ageMin: { $min: '$age' },
ageFirst: { $first: '$age' },
ageLast: { $last: '$age' }
}
}])
// 返回结果
{ "_id" : null, "totalCount" : 10, "ageSum" : 272, "ageAvg" : 27.2, "ageMax" : 40, "ageMin" : 20, "ageFirst" : 25, "ageLast" : 20 }
数据转换:将集合中的数据按addr分组,然后把所有age转换成数组,ages可以自定义,是分组后的列表
使用示例:**$push**
db.getCollection("user").aggregate([{
$group: {
_id: { userAddr: '$addr' },
totalCount: { $sum: 1 },
ages: { $push: '$age' }
}
}])
// 返回结果
{ "_id" : { "userAddr" : "HangZhou" }, "totalCount" : 3, "ages" : [ 30, 20, 40 ] }
{ "_id" : { "userAddr" : "BeiJing" }, "totalCount" : 1, "ages" : [ 30 ] }
{ "_id" : { "userAddr" : "ShenZhen" }, "totalCount" : 2, "ages" : [ 25, 27 ] }
{ "_id" : { "userAddr" : "ShangHai" }, "totalCount" : 1, "ages" : [ 32 ] }
{ "_id" : { "userAddr" : "GuangZhou" }, "totalCount" : 3, "ages" : [ 28, 20, 20 ] }
// 用系统变量$$ROOT按addr对文档进行分组,生成的文档不得超过BSON文档大小限制。
// $$ROOT代表文档本身或者说文档所有字段
db.getCollection("user").aggregate([{
$group: {
_id: { userAddr: '$addr' },
users: { $push: '$$ROOT' }
}
}])
// 返回结果
{ "_id" : { "userAddr" : "HangZhou" }, "users" : [ { "_id" : 6, "name" : "LiSi", "age" : 30, "addr" : "HangZhou" }, { "_id" : 7, "name" : "KaiFa", "age" : 20, "addr" : "HangZhou" }, { "_id" : 8, "name" : "QianDuan", "age" : 40, "addr" : "HangZhou" } ] }
{ "_id" : { "userAddr" : "BeiJing" }, "users" : [ { "_id" : 3, "name" : "LaoWan", "age" : 30, "addr" : "BeiJing" } ] }
{ "_id" : { "userAddr" : "ShenZhen" }, "users" : [ { "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" }, { "_id" : 2, "name" : "XiaoMing", "age" : 27, "addr" : "ShenZhen" } ] }
{ "_id" : { "userAddr" : "ShangHai" }, "users" : [ { "_id" : 4, "name" : "WangWu", "age" : 32, "addr" : "ShangHai" } ] }
{ "_id" : { "userAddr" : "GuangZhou" }, "users" : [ { "_id" : 5, "name" : "ZhaoSi", "age" : 28, "addr" : "GuangZhou" }, { "_id" : 9, "name" : "YunWei", "age" : 20, "addr" : "GuangZhou" }, { "_id" : 10, "name" : "CeSi", "age" : 20, "addr" : "GuangZhou" } ] }
$match + $group
使用示例:
// 单独使用 $match
db.getCollection("user").aggregate([
{ $match : { age : { $gt: 20, $lt: 30} } }
])
{ "_id" : 1, "name" : "ZhangSan", "age" : 25, "addr" : "ShenZhen" }
{ "_id" : 2, "name" : "XiaoMing", "age" : 27, "addr" : "ShenZhen" }
{ "_id" : 5, "name" : "ZhaoSi", "age" : 28, "addr" : "GuangZhou" }
// 使用 $match + $group
db.getCollection("user").aggregate([
{ $match : { age : { $gt: 20, $lt: 30} } },
{
$group: {
_id: { userAddr: '$addr' },
totalCount: { $sum: 1 }
}
}
])
{ "_id" : { "userAddr" : "ShenZhen" }, "totalCount" : 2 }
{ "_id" : { "userAddr" : "GuangZhou" }, "totalCount" : 1 }
注意:$match 必须使用在 $group 之前
索引操作-Index
01、索引介绍
索引的作用是为了提升查询效率,在查询操作中,如果没有索引,MongoDB会扫描集合中的每个文档,以选择与查询语句匹配的文档。如果查询条件带有索引,MongoDB 将扫描索引, 通过索引确定要查询的部分文档,而非直接对全部文档进行扫描。
索引可以提升文档的查询速度,但建立索引的过程需要使用计算与存储资源,在已经建立索引的前提下,插入新的文档会引起索引顺序的重排。
索引就像图书的目录一样,可以让我们快速定位到需要的内容,关系型数据库中有索引,NoSQL 中当然也有,本文我们就先来简单介绍下 MongoDB 中的索引。
MongoDB 的索引是基于 B-tree 数据结构及对应算法形成的。树索引存储特定字段或字段集的值,按字段值排序。索引条目的排序支持有效的等式匹配和基于范围的查询操作。
02、创建索引
- **db.collection.createIndex(keys, options)**:创建集合索引
参数说明:
keys:对象参数为 1 表示正序建立索引,-1 表示逆序建立索引。如果添加多个属性为联合索引
options:可选属性如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
使用示例:
// 唯一索引
> db.user.createIndex({name:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
// 复合索引
> db.user.createIndex({name:1, addr:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
03、查看索引
- **db.collection.getIndexes()**:查看集合索引
- **db.collection.totalIndexSize()**:查看集合索引大小
// 查看user集合索引大小
> db.user.totalIndexSize()
61440
// 查看user集合索引
> db.user.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"name" : 1,
"addr" : 1
},
"name" : "name_1_addr_1"
},
{
"v" : 2,
"key" : {
"name" : 1
},
"name" : "name_1"
}
]
04、删除索引
**db.collection.dropIndexes()**:删除集合中所有索引(除了_id字段外)
**db.collection.dropIndex({‘索引名称’})**:删除集合指定索引(升序降序不能错)
// 删除所有索引,只会删除除了_id以外的所有索引
> db.user.dropIndexes()
{
"nIndexesWas" : 3,
"msg" : "non-_id indexes dropped for collection",
"ok" : 1
}
// 删除name字段的索引,升序降序不能错,如果为-1,则提示无索引
> db.user.dropIndex({name:1})
{ "nIndexesWas" : 3, "ok" : 1 }
05、索引的类型
MongoDB主要支持以下几种索引类型:
MongoDB的索引使用,首先准备数据:
db.userinfos.insertMany([
{_id:1, name: "张三", age: 23,level:10, ename: { firstname: "san", lastname: "zhang"}, roles: ["vip","gen" ]},
{_id:2, name: "李四", age: 24,level:20, ename: { firstname: "si", lastname: "li"}, roles:[ "vip" ]},
{_id:3, name: "王五", age: 25,level:30, ename: { firstname: "wu", lastname: "wang"}, roles: ["gen","vip" ]},
{_id:4, name: "赵六", age: 26,level:40, ename: { firstname: "liu", lastname: "zhao"}, roles: ["gen"] },
{_id:5, name: "田七", age: 27, ename: { firstname: "qi", lastname: "tian"}, address:'北京' },
{_id:6, name: "周八", age: 28,roles:["gen"], address:'上海' }
]);
1、单键索引
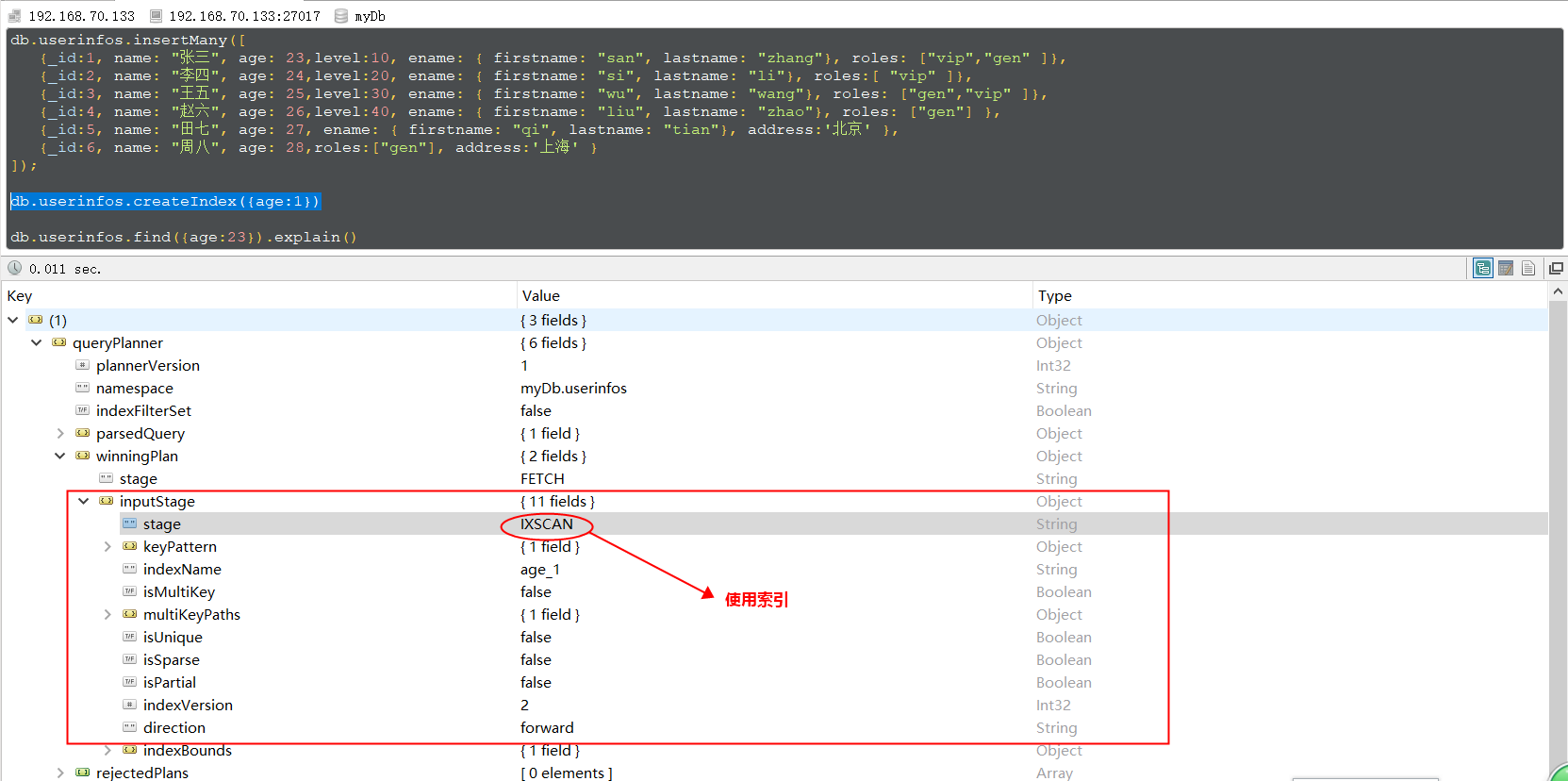
单键索引(Single Field Indexes)顾名思义就是单个字段作为索引列,默认情况下MongoDB都会帮助我们创建一个名为_id的字段,这个字段就是一个索引,我们也可以对一些经常作为过滤条件的字段设置索引,如:给age字段添加一个索引
// 给age字段添加升序索引
db.userinfos.createIndex({age:1})
其中 {age:1} 中的1表示升序,如果想设置倒序索引的话使用:db.userinfos.createIndex({age:-1}) 即可。我们通过explain()方法查看查询计划,如下图,看到查询:age=23的document时使用了索引,如果没有使用索引的话stage=COLLSCAN。
因为document的存储是bson格式的,我们也可以给内置对象的字段添加索引,或者将整个内置对象作为一个索引,语法如下:
//1.内嵌对象的某一字段作为索引
//在ename.firstname字段上添加索引
db.userinfos.createIndex({"ename.firstname":1})
//使用ename.firstname字段的索引查询
db.userinfos.find({"ename.firstname":"san"})
//2.整个内嵌对象作为索引
//给整个ename字段添加索引
db.userinfos.dropIndexes()
//使用ename字段的索引查询
db.userinfos.createIndex({"ename":1})
2、复合索引
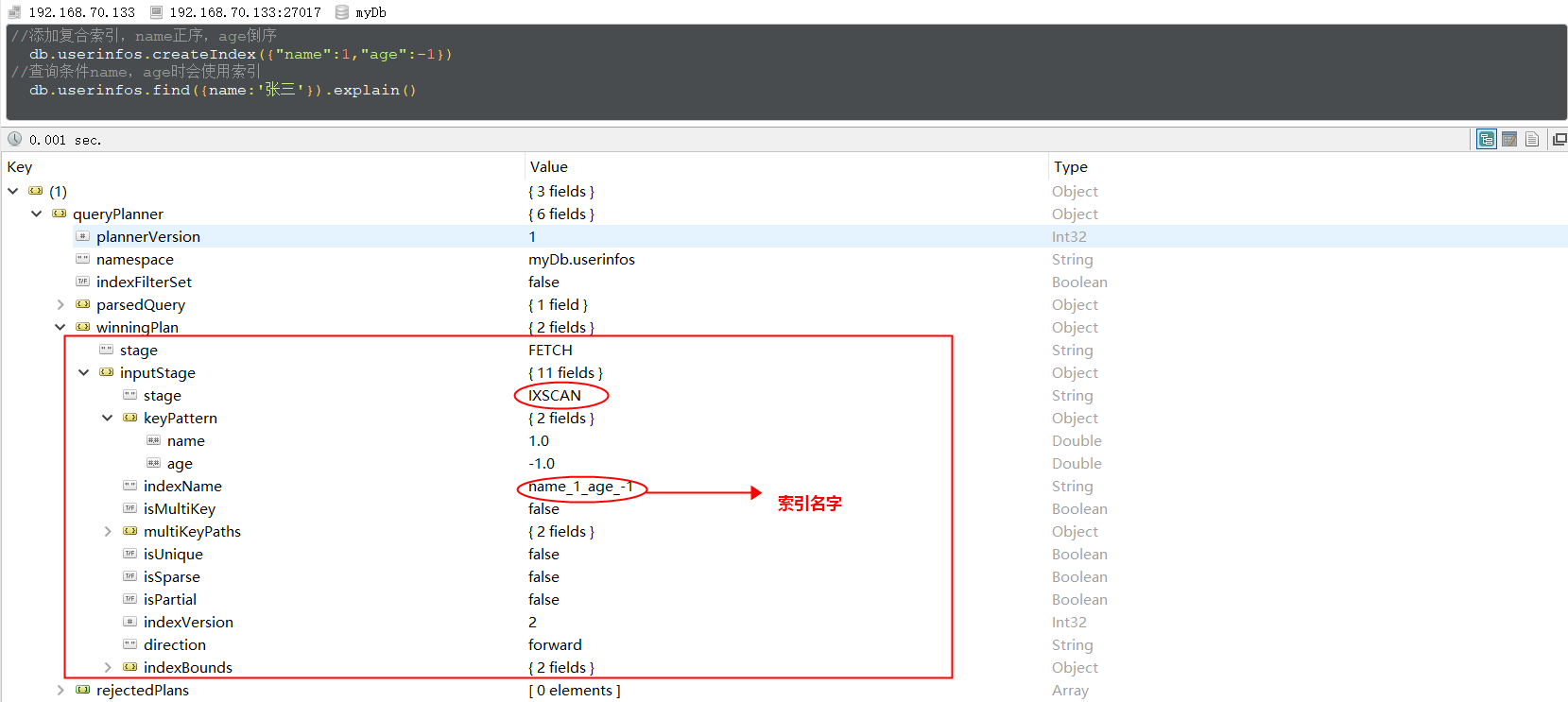
复合索引(Compound Indexes)指一个索引包含多个字段,用法和单键索引基本一致。使用复合索引时要注意字段的顺序,如下添加一个name和age的复合索引,name正序,age倒序,document首先按照name正序排序,然后name相同的document按age进行倒序排序。mongoDB中一个复合索引最多可以包含32个字段。
// 添加复合索引,name正序,age倒序
db.userinfos.createIndex({"name":1,"age":-1})
// 过滤条件为name,或包含name的查询会使用索引(索引的第一个字段)
db.userinfos.find({name:'张三'}).explain()
db.userinfos.find({name:"张三",level:10}).explain()
db.userinfos.find({name:"张三",age:23}).explain()
// 查询条件为age时,不会使用上边创建的索引,而是使用的全表扫描
db.userinfos.find({age:23}).explain()
执行查询时查询计划如下:
3、多键索引
多键索引(mutiKey Indexes)是建在数组上的索引,在MongoDB的ocument中,有些字段的值为数组,多键索引就是为了提高查询这些数组的效率。看一个栗子:准备测试数据,classes集合中添加两个班级,每个班级都有一个students数组,如下:
db.classes.insertMany([
{
"classname":"class1",
"students":[{name:'jack',age:20},
{name:'tom',age:22},
{name:'lilei',age:25}]
},
{
"classname":"class2",
"students":[{name:'lucy',age:20},
{name:'jim',age:23},
{name:'jarry',age:26}]
}]
)
为了提高查询students的效率,我们给students的age字段添加索引
// 给students数组中的age字段添加索引
db.classes.createIndex({'students.age':1})
// 查询条件时student.age时,使用索引
db.classes.find({'students.age':20}).explain()
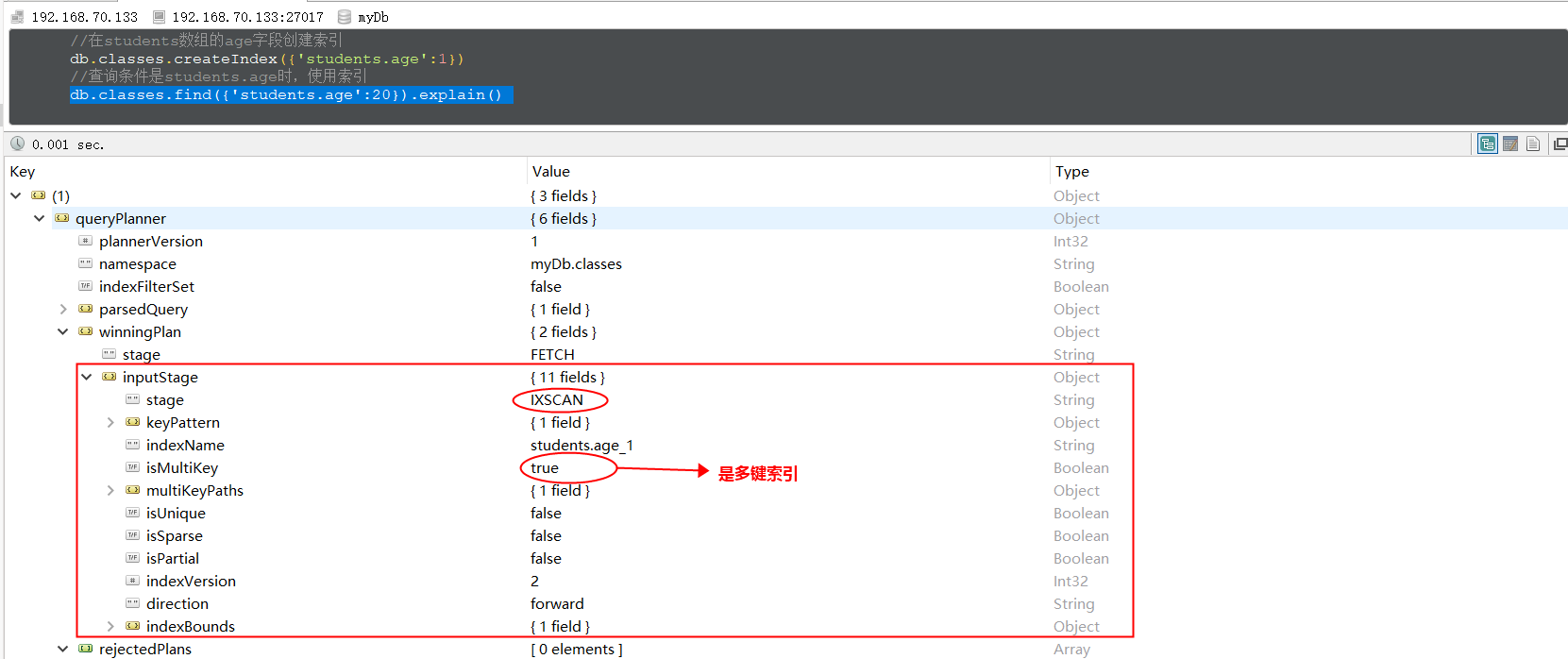
4、哈希索引
哈希索引(hashed Indexes)就是将 field 的值进行 hash 计算后作为索引,散列索引只能用于字段完全匹配的查询,不能用于范围查询等,对于经常需要排序或查询范围查询的集合不要使用哈希索引。
// 再userinfos的name字段创建哈希索引
db.collection.createlndex( { _id : "hashed" })
// 查询条件时name时,使用索引
db.userinfos.find({'name':'张三'}).explain()
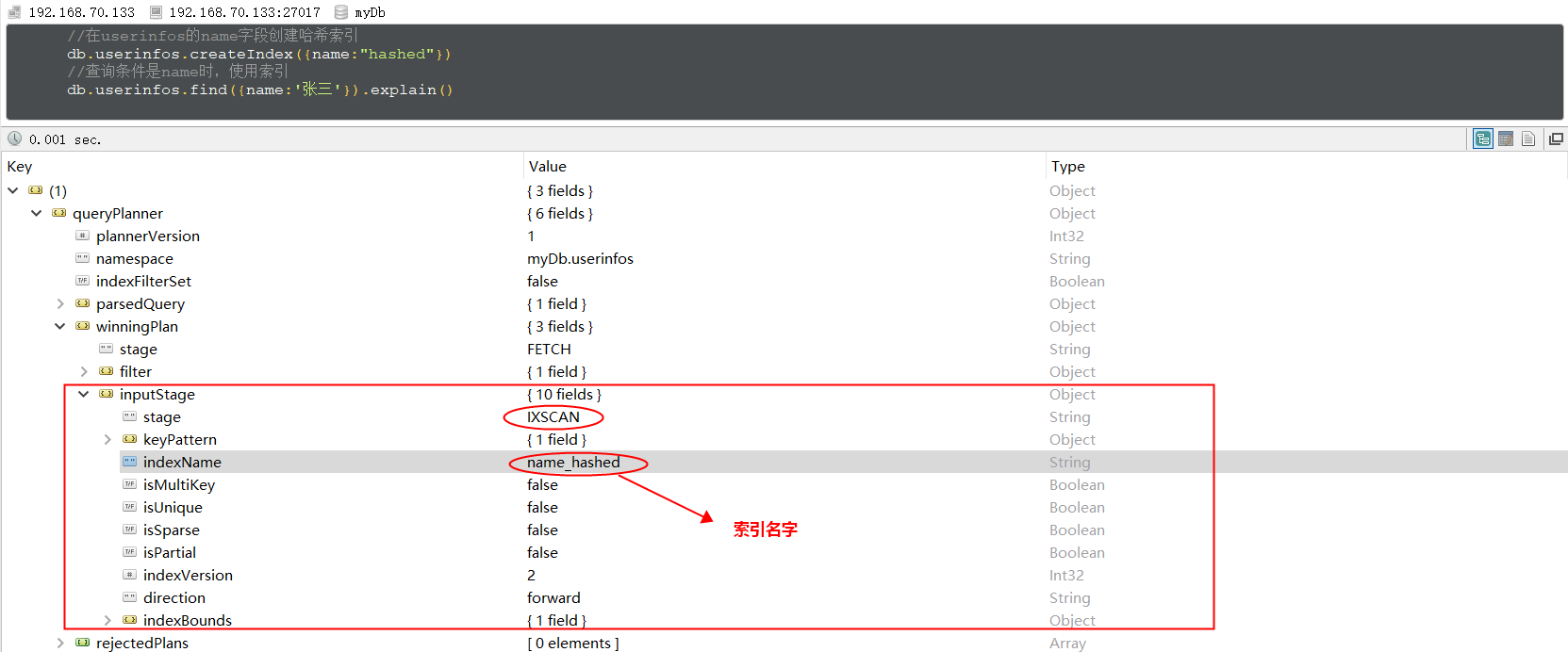
MongoDB 支持散列任何单个字段的索引,但是不支持多键(即数组)索引。需要说明的是,MongoDB 在进行散列索引之前,需要将浮点数截断为 64 位整数。例如,散列将对 2.3、2.2 和 2.9 这些值产生同样的返回值。
5、全文索引
参考:https://www.cnblogs.com/xibuhaohao/p/12049143.html
一般全文索引可以用:elasticsearch、solr、lucene
6、地理空间索引
地理空间索引类型:地理空间索引可以分为两类:
1、2d索引,可以用来存储和查找平面上的点。
2、2d sphere索引,可以用来存储和查找球面上的点。
06、索引的属性
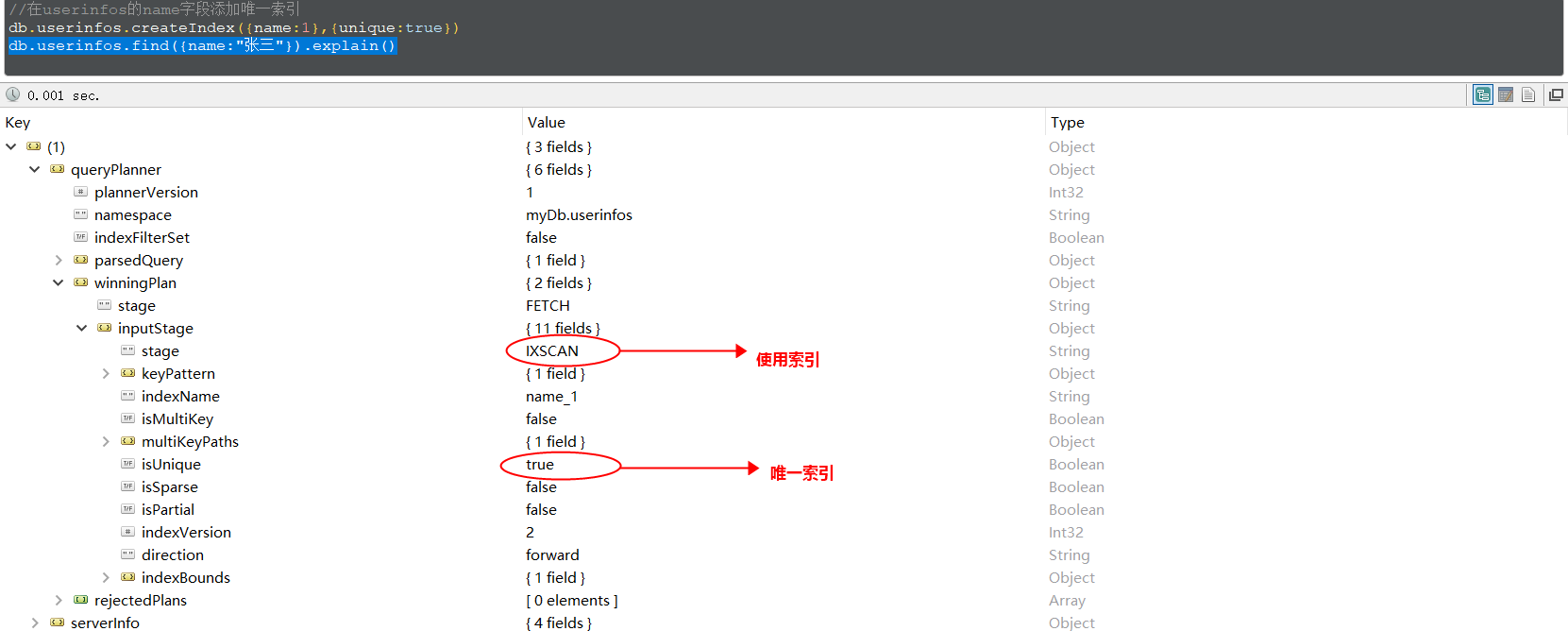
1、唯一索引
唯一索引(unique indexes)用于为 Collection 添加唯一约束,即强制要求 Collection中 的索引字段没有重复值。
添加唯一索引的语法:
// 在userinfos的name字段添加唯一索引
db.userinfos.createIndex({name:1},{unique:true})
看一个使用唯一索引的栗子:
2、局部索引
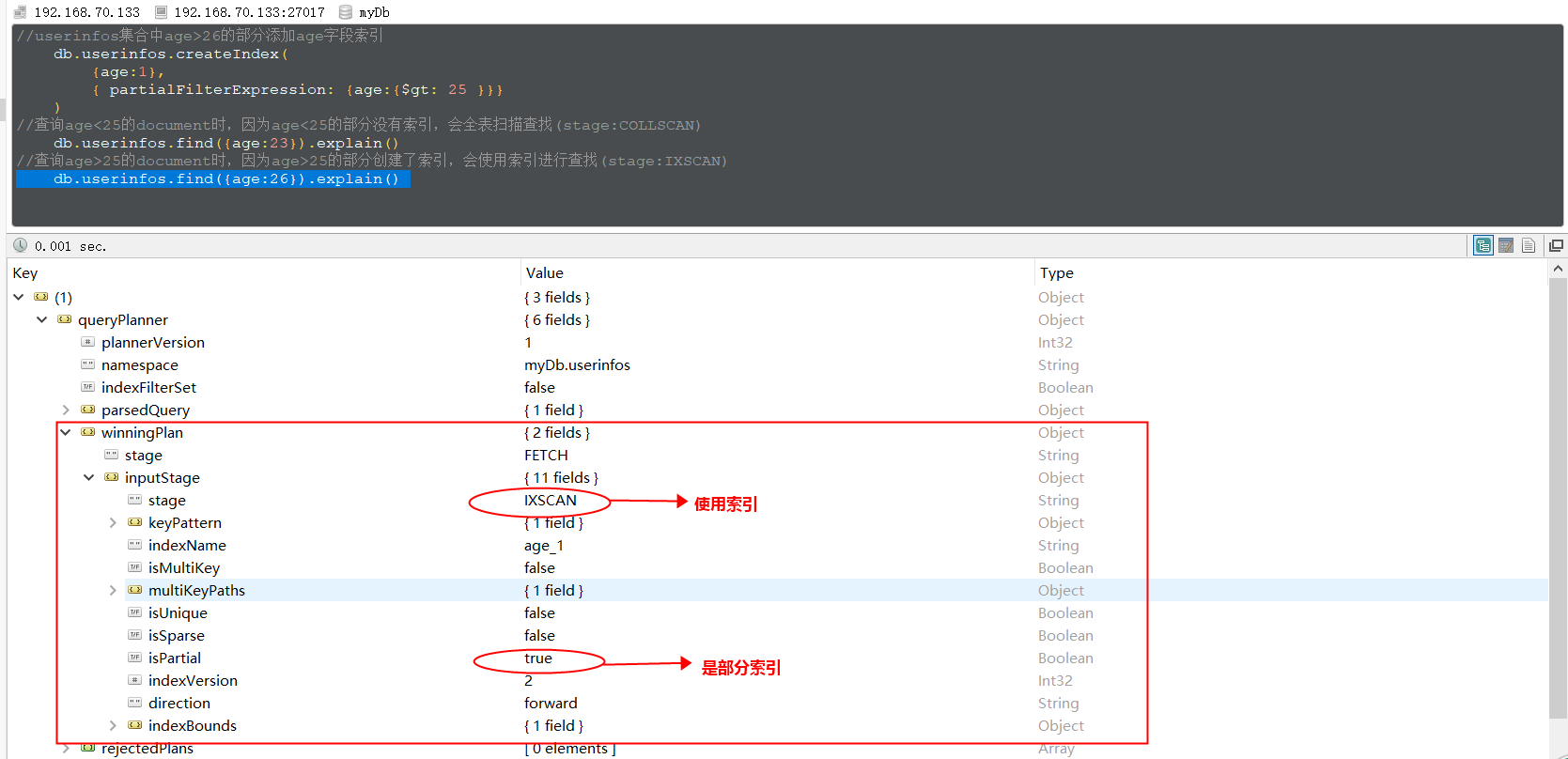
局部索引(Partial Indexes)顾名思义,只对 Collection 的一部分添加索引。创建索引的时候,根据过滤条件判断是否对 Document 添加索引,对于没有添加索引的文档查找时采用的全表扫描,对添加了索引的文档查找时使用索引。使用方法也比较简单:
//userinfos集合中age>25的部分添加age字段索引
db.userinfos.createIndex(
{ age:1 },
{ partialFilterExpression: {age:{$gt: 25 }}}
)
//查询age<25的document时,因为age<25的部分没有索引,会全表扫描查找(stage:COLLSCAN)
db.userinfos.find({age:23})
//查询age>25的document时,因为age>25的部分创建了索引,会使用索引进行查找(stage:IXSCAN)
db.userinfos.find({age:26})
当查询 age=23 的记录时,stage=COLLSCAN,当查询age=26的记录时,使用了索引,如下:
3、稀疏索引
稀疏索引(sparse indexes)在有索引字段的 Document 上添加索引,如在 address 字段上添加稀疏索引时,只有 Document 有address 字段时才会添加索引。而普通索引则是为所有的 Document 添加索引,使用普通索引时如果 Document 没有索引字段的话,设置索引字段的值为null。
稀疏索引的创建方式如下,当Document包含address字段时才会创建索引:
// 创建在address上创建稀疏索引
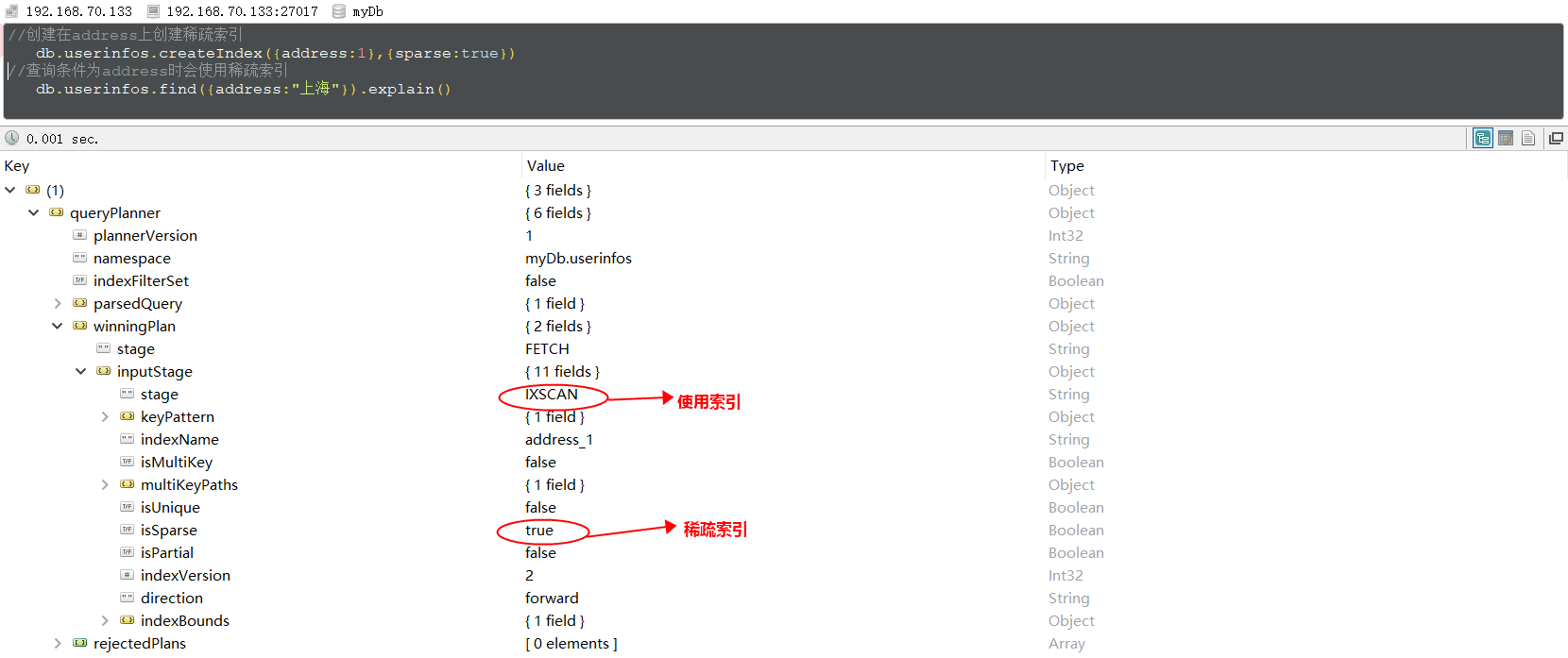
db.userinfos.createIndex({address:1},{sparse:true})
看一个使用稀疏索引的栗子:
4、过期索引-TTL
TTL索引(TTL indexes)是一种特殊的单键索引,用于设置 Document 的过期时间,MongoDB 会在 Document 过期后将其删除,TTL非常容易实现类似缓存过期策略的功能。我们看一个使用TTL索引的栗子:
// 添加测试数据
db.logs.insertMany([
{_id:1,createtime:new Date(),msg:"log1"},
{_id:2,createtime:new Date(),msg:"log2"},
{_id:3,createtime:new Date(),msg:"log3"},
{_id:4,createtime:new Date(),msg:"log4"}
])
// 在createtime字段添加TTL索引,过期时间是120s
db.logs.createIndex({createtime:1}, { expireAfterSeconds: 120 })
// logs中的document在创建后的120s后过期,会被mongoDB自动删除
db.logs.insert( { _id: 5, createtime: new Date(), msg:"log5" } )
注意:TTL索引只能设置在date类型字段(或者包含date类型的数组)上,过期时间为字段值 + exprireAfterSeconds;document过期时不一定就会被立即删除,因为MongoDB执行删除任务的时间间隔是60s;capped Collection不能设置TTL索引,因为MongoDB不能主动删除capped Collection中的document。
5、案例实战-TTL
实现定时删除任务:参考:https://www.cnblogs.com/jiangqw/p/12174746.html
利用 TTL 集合对存储的数据进行失效时间设置:经过指定的时间段后或在指定的时间点过期,MongoDB 独立线程去清除数据。
在指定秒数后使文档过期
1、首先创建索引,设置过期时间为180秒,然后存储数据入库
// 创建 TTL 索引,过期实践为180秒
db.col.createIndex( { createDate: 1 }, { expireAfterSeconds: 180 } )
// 然后插入数据测试
db.col.insert( { _id: 1, createDate: new Date() } )
3、mongodb 会在大于 expireAfterSeconds 指定值的秒数后,过期
// 180 秒后查看数据是否过期
db.col.find();
在特定时钟时间使文档过期
1、首先建立索引,设置 expireAfterSeconds 为 0
// 创建索引,设置过期时间参数为0
db.col.createIndex( { createDate: 1 }, { expireAfterSeconds: 0 } )
// 然后插入数据,增加的索引字段给定指定的时间
db.col.insert( { _id: 1, "createDate": new Date('July 22, 2020 12:00:00') } )
2、createDate 的值为特定的时间值,等时间到达expireAt的值时,这个文档就 失效了。
其他注意事项:
- 索引关键字段必须是 Date 类型。
- 非立即执行:扫描 Document 过期数据并删除是独立线程执行,默认 60s 扫描一次,删除也不一定是立即删除成功。
- 单字段索引,混合索引不支持
备份恢复及导入导出
MongoDB 4.4版本 之后 MongoDB数据库工具现在与MongoDB服务 分开发布 需要单独安装
- 下载地址:https://docs.mongodb.com/database-tools/
- 下载安装或解压,配置到环境变量 path 中,然后可以使用 mongodump、 mongorestore、 mongoimport、 mongoexport 命令
- 在导入其他人的数据库前,应该清空 –>该库下的用户 –>再创建用户后再连接
数据导出与导入:mongoexport、mongoimport
01、导出:mongoexport
1、概念:
mongoDB 中的 mongoexport 工具可以把一个 collection(集合) 导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。
2、语法:
mongoexport -d dbname -c cname -o file --type json/csv -f field
参数说明:
-d、–db:数据库名
-c 、–collection:集合名
-o、–out :输出的文件名
–type: 输出的格式,默认为json。可以为json/csv
-f:输出的字段,如果-type为csv,则需要加上-f “字段名”
-h:指明数据库宿主机的IP。如是本机可以去除该参数
-u:指明数据库的用户名
-p:指明数据库的密码
示例:
# 导出dbname数据库的cname集合中所有 _id,user_id,user_name,age,status 字段到 /mongoBack/cname.json文件中
mongoexport -d dbname -c cname -o /mongoBack/cname.json -f "_id,user_id,user_name,age,status"
02、导入:mongoimport
当要插入的数据太多时,一条一条的insert在繁琐了。所以,我们可以在代码编辑器中以JSON格式编辑好要插入的数据,以 *.json 文件格式保存,然后导入数据库:下面就是将mydata.json文件,导入到test数据库的student集合中。
1、语法:
mongoimport -d dbname -c cname --file filename --headerline -f field
参数说明:
-d :数据库名
-c :collection名
–type :导入的格式默认json。可以为json/csv
-f :导入的字段名
–headerline :如果导入的格式是csv,则可以使用第一行的标题作为导入的字段
–file :要导入的文件
–drop:导入前把集合中的数据清空
-h:指明数据库宿主机的IP。如是本机可以去除该参数
-u:指明数据库的用户名
-p:指明数据库的密码
示例:
# 把/mongoBack/cname.json中的数据导入dbname数据中的cname集合中,并且只导入_id,user_id,user_name,age,status字段
mongoimport -d dbname -c cname --file /mongoBack/cname.json -f "_id,user_id,user_name,age,status" --drop
MongoDB备份与恢复:mongodump、mongorestore
03、备份:mongodump
1、语法:
mongodump -h host -u user -d dname -o dbdirectory
参数说明:
-d: 需要备份的数据库实例,例如:test
-o: 备份的数据存放位置,该路径需要提前创建。例:/home/mongodump/
-h:指明数据库宿主机的IP。如是本机可以去除该参数
-u:指明数据库的用户名
-p:指明数据库的密码
–port:端口号。如是默认可以去除该参数
示例:
# 备份单个表
mongodump -u user -p 123 --authenticationDatabase admin -d dname -c cname -o /backup/mongodb/dname_d_bak_201507021701.bak
# 备份单个库
mongodump -u user -p 123 --authenticationDatabase admin -d dname -o /backup/mongodb/
# 备份所有库
mongodump -u user -p 123 --authenticationDatabase admin -o /backup/allbak
# 备份所有库推荐使用添加--oplog参数的命令,这样的备份是基于某一时间点的快照,只能用于备份全部库时才可用,单库和单表不适用:
mongodump -h 127.0.0.1 --port 27017 --oplog -o /backup/allbak
04、恢复:mongorestore
1、语法:
mongorestore -h host -u user -d dname --dir dbdirectory
参数或名:
-d: 需要恢复的数据库实例,当然这个名称也可以和备份时候的不一样,比如test2
–dir: 备份数据所在位置,例如:/home/mongodump/itcast/
–drop: 恢复前把集合中的数据清空。
-h: MongoDB所在服务器地址。如是本机可以去除该参数
-u:指明数据库的用户名
-p:指明数据库的密码
–port:端口号。如是默认可以去除该参数
示例:
# 恢复单表
mongorestore -u user -p 123 --authenticationDatabase admin -d dname -c cname /backup/mongodb/dname_d_bak_201507021701.bak/myTest/d.bson
# 恢复单个库:
mongorestore -u user -p 123 --authenticationDatabase admin -d dname /backup/mongodb/
# 恢复所有库:
mongorestore -u user -p 123 --authenticationDatabase admin /backup/allbak
# 备份时如果加了--oplogReplay参数,恢复时也要加上--oplogReplay参数,具体命令如下(下面是恢复单库的命令):
mongorestore -d dname --oplogReplay /home/mongo/swrdbak/swrd/
注意:
1、mongorestore恢复数据默认是追加,如打算先删除后导入,可以加上–drop参数,不过添加–drop参数后,会将数据库数据清空后再导入,如果数据库备份后又新加入了数据,也会将新加的数据删除,它不像mysql有一个存在的判断
2、mongodump在mongo关闭时,也是可以备份的,不过需要指定数据目录,命令为:mongodump –dbpath /data/db
使用MongoDB其他命令行工具远程操作连接时,尽量加上如下参数.
--authenticationDatabase admin
Java操作MongoDB
参考:https://mongodb.github.io/mongo-java-driver/4.2/driver/getting-started/installation/
http://c.biancheng.net/view/6571.html
https://www.jianshu.com/p/6d0238719919
https://blog.csdn.net/zhangliangzi/article/details/51730194
SpringBoot整合MongoDB
Spring Boo与MongoDB集成,并通过MongoRepository以及MongoTemplate来执行CRUD操作。
1、准备工作
1.1、依赖包版本号:
Spring Boot:2.3.0.RELEASE
Spring Boot Data MongoDB:2.3.0.RELEASE
MongoDB:4.2.6
MongoDB Driver:4.0.3
1.2、要操作集合数据结构(即model)
Department:
| 字段名 | 类型 |
|---|---|
| id | String |
| name | String |
| description | String |
| employees | Arrays |
Employee:
| 字段名 | 类型 |
|---|---|
| empId | String |
| name | String |
| age | int |
| address | String |
2、创建项目
2.1、创建SpringBoot项目,并添加依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
2.2、配置文件增加MongoDB配置,application.properties
spring.data.mongodb.host=127.0.0.1
spring.data.mongodb.port=27017
spring.data.mongodb.database=test
spring.data.mongodb.username=admin
spring.data.mongodb.password=password
# 简写,其中name是用户名,pwd是密码,test是数据库
# spring.data.mongodb.uri=mongodb://127.0.0.1:27017/test
# spring.data.mongodb.uri=mongodb://name:pwd@127.0.0.1:27017/test
# 如果要配置多个数据库,则中间用","分割
# spring.data.mongodb.uri=mongodb://127.0.0.1:27017,127.0.0.1:27018,127.0.0.1:27019/test
备注:username不能是admin管理员用户。必须是当前database的用户才可以
2.3、测试项目能否正常启动,然后查看项目结构:
├─src
│ ├─main
│ │ ├─java
│ │ │ └─com
│ │ │ └─example
│ │ │ └─mongodb
│ │ │ │ MongodbApplication.java
│ │ │ │
│ │ │ ├─controller
│ │ │ │ DepartmentController.java
│ │ │ │ EmployeeController.java
│ │ │ │
│ │ │ ├─model
│ │ │ │ Department.java
│ │ │ │ Employee.java
│ │ │ │
│ │ │ └─repository
│ │ │ DeptRepository.java
│ │ │ DeptTemplate.java
│ │ │ EmpRepository.java
│ │ │ EmpTemplate.java
│ │ │
│ │ └─resources
│ │ │ application.properties
│ │ │
│ │ ├─static
│ │ └─templates
│ └─test
│
└─target
2.4、创建Model Bean(Department.class、Employee.clss)
package com.example.mongodb.model;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.index.Indexed;
import org.springframework.data.mongodb.core.mapping.DBRef;
import org.springframework.data.mongodb.core.mapping.Document;
import java.io.Serializable;
import java.util.List;
@Data
@Document("Department")
public class Department implements Serializable {
@Id
private String id;
@Indexed(name = "deptName")
private String name;
private String description;
@DBRef
private List<Employee> employees;
}
package com.example.mongodb.model;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import java.io.Serializable;
@Data
@Document("Employee")
public class Employee implements Serializable {
@Id
private String empId;
private String name;
private int age;
private String address;
}
2.5、两种操作数据的方式:MongoRepository、MongoTemplate
MongoRepository
DeptRepository.class、EmpRepository.class
package com.example.mongodb.repository;
import com.example.mongodb.model.Department;
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.data.mongodb.repository.Query;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface DeptRepository extends MongoRepository<Department,String> {
@Query(value = "{'Employee.name': ?0}", fields = "{'employees' : 0}")
Department findDepartmentByEmployeeName(String empName);
List<Department> findDepartmentByName(String name);
}
package com.example.mongodb.repository;
import com.example.mongodb.model.Employee;
import org.springframework.data.mongodb.repository.MongoRepository;
public interface EmpRepository extends MongoRepository<Employee,String> {
}
MongoTemplate
DeptTemplate.class、EmpTemplate.class
package com.example.mongodb.repository;
import com.example.mongodb.model.Department;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public class DeptTemplate {
@Autowired
private MongoTemplate mongoTemplate;
public List<Department> findAll() {
return mongoTemplate.findAll(Department.class);
}
public List<Department> findDepartmentByName(String deptName){
Query query = new Query();
query.addCriteria(Criteria.where("name").is(deptName));
return mongoTemplate.find(query, Department.class);
}
public Department save(Department department) {
mongoTemplate.save(department);
return department;
}
public Department update(Department department){
Query query = new Query();
query.addCriteria(Criteria.where("id").is(department.getId()));
Update update = new Update();
update.set("name", department.getName());
update.set("description", department.getDescription());
return mongoTemplate.findAndModify(query, update, Department.class);
}
public void deleteById(String deptId) {
Query query = new Query();
query.addCriteria(Criteria.where("id").is(deptId));
mongoTemplate.remove(query, Department.class);
}
}
package com.example.mongodb.repository;
import com.example.mongodb.model.Employee;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public class EmpTemplate {
@Autowired
private MongoTemplate mongoTemplate;
public List<Employee> findAll() {
return mongoTemplate.findAll(Employee.class);
}
public Employee save(Employee employee) {
mongoTemplate.save(employee);
return employee;
}
public Employee update(Employee employee){
Query query = new Query();
query.addCriteria(Criteria.where("empId").is(employee.getEmpId()));
Update update = new Update();
update.set("name", employee.getName());
update.set("description", employee.getAddress());
return mongoTemplate.findAndModify(query, update, Employee.class);
}
public void deleteById(String empId) {
Query query = new Query();
query.addCriteria(Criteria.where("empId").is(empId));
mongoTemplate.remove(query, Employee.class);
}
}
2.6、创建Controller(DepartmentController.class、EmployeeController.class)
package com.example.mongodb.controller;
import com.example.mongodb.model.Department;
import com.example.mongodb.model.Employee;
import com.example.mongodb.repository.DeptRepository;
import com.example.mongodb.repository.DeptTemplate;
import com.example.mongodb.repository.EmpRepository;
import com.example.mongodb.repository.EmpTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.Collections;
import java.util.List;
import java.util.Optional;
@RestController
public class DepartmentController {
// v1的接口使用 MongoRepository 方式操作数据
@Autowired DeptRepository deptRepository;
@Autowired EmpRepository empRepository;
// v2的接口使用 MonoTemplate 方式操作数据
@Autowired DeptTemplate deptTemplate;
@Autowired EmpTemplate empTemplate;
/********************* MongoRepository方式 *********************/
@PostMapping("/v1/dept/save")
public Department v1save(@RequestBody Department department) {
// 添加部门信息前首先保存员工信息
List<Employee> employees = Optional.ofNullable(department.getEmployees()).orElse(Collections.emptyList());
employees.forEach(employee -> empRepository.save(employee));
return deptRepository.save(department);
}
@GetMapping("/v1/dept/list")
public List<Department> v1list(){
return deptRepository.findAll();
}
@PutMapping("/v1/dept/update/{deptId}")
public Department v1update(@RequestBody Department department, @PathVariable String deptId) {
department.setId(deptId);
List<Employee> employees = Optional.ofNullable(department.getEmployees()).orElse(Collections.emptyList());
employees.forEach(Employee -> empRepository.save(Employee));
return deptRepository.save(department);
}
@DeleteMapping("/v1/dept/delete/{deptId}")
public String v1delete(@PathVariable String deptId) {
deptRepository.deleteById(deptId);
return deptId;
}
@GetMapping("/v1/dept/get/{deptName}")
public List<Department> v1getByName(@PathVariable String deptName) {
return deptRepository.findDepartmentByName(deptName);
}
@GetMapping("/v1/dept/get/emp/{empName}")
public Department v1getByEmpName(@PathVariable String empName) {
return deptRepository.findDepartmentByEmployeeName(empName);
}
/********************* MonoTemplate方式 *********************/
@PostMapping("/v2/dept/save")
public Department v2save(Department department) {
List<Employee> employees = Optional.ofNullable(department.getEmployees()).orElse(Collections.emptyList());
employees.forEach(Employee -> empRepository.save(Employee));
return deptTemplate.save(department);
}
@GetMapping("/v2/dept/list")
public List<Department> v2list() {
return deptTemplate.findAll();
}
@PutMapping("/v2/dept/update")
public Department v2update(Department department){
List<Employee> employees = Optional.ofNullable(department.getEmployees()).orElse(Collections.emptyList());
employees.forEach(emp -> empRepository.save(emp));
return deptTemplate.update(department);
}
@DeleteMapping("/v2/dept/delete/{deptId}")
public void v2delete(@PathVariable String deptId) {
deptTemplate.deleteById(deptId);
}
@GetMapping("/v2/dept/get/{deptName}")
public List<Department> v2getByName(@PathVariable String deptName){
return deptTemplate.findDepartmentByName(deptName);
}
}
package com.example.mongodb.controller;
import com.example.mongodb.model.Department;
import com.example.mongodb.model.Employee;
import com.example.mongodb.repository.DeptRepository;
import com.example.mongodb.repository.DeptTemplate;
import com.example.mongodb.repository.EmpRepository;
import com.example.mongodb.repository.EmpTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.Collections;
import java.util.List;
import java.util.Optional;
@RestController
public class EmployeeController {
// v1的接口使用 MongoRepository 方式操作数据,v2的接口使用 MonoTemplate 方式操作数据
@Autowired EmpRepository empRepository;
@Autowired EmpTemplate empTemplate;
/********************* MongoRepository方式 *********************/
@PostMapping("/v1/emp/save")
public Employee v1save(@RequestBody Employee employee) {
return empRepository.save(employee);
}
@GetMapping("/v1/emp/list")
public List<Employee> v1list(){
return empRepository.findAll();
}
@PutMapping("/v1/emp/update/{empId}")
public Employee v1update(@RequestBody Employee employee, @PathVariable String empId) {
//employee.setEmpId(empId);
return empRepository.save(employee);
}
@DeleteMapping("/v1/emp/delete/{empId}")
public String v1delete(@PathVariable String empId) {
empRepository.deleteById(empId);
return empId;
}
}
3、测试接口
v1的接口使用MongoRepository方式操作数据,v2的接口使用MonoTemplate方式操作数据。
###新增
POST http://localhost:8080/v1/dept/save
Content-Type: application/json
{
"id": "007",
"name": "阿里巴巴",
"description": "阿里巴巴Java开发",
"employees": [{
"empId": "1",
"name": "Sam Liu",
"age": 28,
"address": "深圳"
}]
}
###更新
PUT http://localhost:8080/v1/dept/update/007
Content-Type: application/json
{
"id": "007",
"name": "阿里巴巴-new",
"description": "阿里巴巴Web开发",
"employees": [
{
"empId": "1",
"name": "Sam Liu",
"age": 28,
"address": "深圳"
},
{
"empId": "2",
"name": "Tom",
"age": 38,
"address": "杭州"
}
]
}
###删除
DELETE http://localhost:8080/v1/dept/delete/007
###查询
GET http://localhost:8080/v1/dept/list
##############################################################
###新增
POST http://localhost:8080/v1/emp/save
Content-Type: application/json
{
"empId": "1",
"name": "Sam Liu",
"age": 28,
"address": "深圳"
}
###更新
PUT http://localhost:8080/v1/emp/update/1
Content-Type: application/json
{
"empId": "1",
"name": "Sam Liu-update",
"age": 28,
"address": "深圳-update"
}
###删除
DELETE http://localhost:8080/v1/emp/delete/007
###查询
GET http://localhost:8080/v1/emp/list
参考资料 & 鸣谢
- MongoDB安装教程(Win10&Linux)
- MongoDb 快速入门教程
- MongoDB安装和入门
- MongoDB的简单认识及基本操作
- MongoDB 使用教程–基本增删改查语法
- Spring Boot 集成 MongoDB 小白篇
- SpringBoot学习笔记(十一:使用MongoDB存储文件 )
- mongodb.conf配置文件详解
- mongodb配置文件config.conf详解
- MongoDB系列—用户及权限管理02、MongoDB系列—集合与文档操作03
- 乾子大大、KG、H_Johnny
- mongodb高级聚合查询
- 快速掌握mongoDB(三)——mongoDB的索引详解
- MongoDB可视化管理工具adminMongo:http://www.fairysoftware.com/admin_mongo.html
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 8629303@qq.com

