SpringData JPA 快速入门
1、SpringData JPA 简介
1、Spring Data JPA 认识,官网:https://spring.io/projects/spring-data-jpa
SpringData:其实SpringData就是Spring提供了一个操作数据的框架。而SpringData JPA 只是 SpringData 框架下的一个基于JPA标准操作数据的模块,简化操作持久层的代码。只需要编写接口就可以。
Spring Data JPA:是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:Hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
2、Spring Data JPA 特性
Features:
- Sophisticated support to build repositories based on Spring and JPA
- Support for Querydsl predicates and thus type-safe JPA queries
- Transparent auditing of domain class
- Pagination support, dynamic query execution, ability to integrate custom data access code
- Validation of @Query annotated queries at bootstrap time
- Support for XML based entity mapping
- JavaConfig based repository configuration by introducing @EnableJpaRepositories.
SpringDataJPA 极大简化了数据库访问层代码。 使用SpringDataJpa,我们的DAO层中只需要写接口,就自动具有了增删改查、分页查询等方法。
3、Hibernate 与 JPA 和 Spring Data JPA 的关系
Java代码-----》Spring Data JPA-----》JPA 规范-----》Hibernate库-----》封装JDBC操作-----》数据库
- JPA 是一套规范,内部是有接口和抽象类组成的
- Hibernate 是一套成熟的ORM框架,而且 Hibernate 实现了JPA规范,所以也可以称 hibernate 为 JPA 的一种实现方式,我们使用 JPA 的 API 编程,意味着站在更高的角度上看待问题(面向接口编程)
- Spring Data JPA 是 Spring 提供的一套对JPA操作更加高级的封装,是在JPA规范下的专门用来进行数据持久化的解决方案
2、SpringBoot 集成 JPA
1、pom.xml导入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2、application.properties配置数据源信息
# 数据库配置信息
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/springdata_jpa?useSSL=false&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=password
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
# 控制台打印SQL
spring.jpa.show-sql=true
# 格式化SQL
spring.jpa.properties.hibernate.format_sql=true
# 自动建表模式:create-drop,create,update,validate,none
spring.jpa.hibernate.ddl-auto=update
# 建表使用MyISAM引擎,默认是InnoDB
# spring.jpa.database-platform=org.hibernate.dialect.MySQL5Dialect
3、新建User实体类
@Data
@Entity
@Table(name = "sys_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String password;
}
4、编写Dao接口
// 接口内可以什么也不写
public interface UserRepository extends JpaRepository<User, Long> {
}
5、测试
@SpringBootTest
public class JpaApplicationTests {
@Autowired
private UserRepository userRepository;
/**
* @Transactional: 开启事物(事务提交方式默认的是回滚)
* @Rollback(false): 取消自动回滚
* 为什么加@Rollback(false),可以参考SpringData JPA 之疑难杂症=》SpringBoot Junit事物自动回滚
*/
@Test
@Transactional
@Rollback(false)
public void save() {
User user = new User();
user.setUsername("admin");
user.setPassword("password");
userRepository.save(user);
}
@Test
public void find(){
System.out.println(userRepository.findAll());
System.out.println(userRepository.findById(1L));
}
}
查看日志:
Hibernate:
insert
into
sys_user
(age, password, username)
values
(?, ?, ?)
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
[User(id=1, username=admin, password=password, age=18)]
Hibernate:
select
user0_.id as id1_1_0_,
user0_.age as age2_1_0_,
user0_.password as password3_1_0_,
user0_.username as username4_1_0_
from
sys_user user0_
where
user0_.id=?
User(id=1, username=admin, password=password, age=18)
PS:SpringBoot启动类默认可以不加@EnableJpaRepositories(basePackages=”com.xxx”)扫描JPA包,与SpringBoot扫描包类似。
3、SpringDataJPA 整合 H2
1、使用IDEA创建SpringBoot项目
2、导入依赖 pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- 可以不配置版本号,默认就是最新版本 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
<!--<version>1.4.200</version>-->
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2、application.properties配置
#################### H2 数据库配置 ####################
# 文件数据库
# spring.datasource.url = jdbc:h2:file:./dbh2/dbc2m;AUTO_SERVER=TRUE
# 内存数据库,platform #表明使用的数据库平台是 h2
spring.datasource.url = jdbc:h2:mem:test_jpa
spring.datasource.driverClassName = org.h2.Driver
spring.datasource.username = sa
spring.datasource.password = sa
spring.datasource.platform = h2
#################### H2 Web Console设置 ####################
# enabled:程序开启时就会启动 H2 Web Console, 默认就是启动的
# path:配置访问地址为:/h2,访问 H2 Web Console,默认:/h2-console
# settings.web-allow-others:开启H2 Web Console远程访问,默认为false不开启只能在本机访问
spring.h2.console.enabled = true
spring.h2.console.path = /h2
spring.h2.console.settings.web-allow-others = true
#################### JPA 配置 ####################
# 控制台打印SQL、格式化SQL、设置ddl模式(如果数据库是内存模式,ddl-auto配置没有什么作用)、设置方言
spring.jpa.show-sql = true
spring.jpa.properties.hibernate.format_sql = true
spring.jpa.hibernate.ddl-auto = update
spring.jpa.database-platform = org.hibernate.dialect.H2Dialect
3、其他启动和测试一样的
SpringData JPA 接口查询
1、SpringData 核心接口
Repository:最顶层的接口,是一个空的接口,目的是为了统一所有Repository的类型,且能让组件扫描的时候自动识别
CrudRepository:是Repository的子接口,提供CRUD的功能
PagingAndSortingRepository:是CrudRepository的子接口,添加分页和排序的功能
JpaRepository:是PagingAndSortingRepository的子接口,增加了一些实用的功能,比如:批量操作等
JpaSpecificationExecutor:用来做负责查询的接口
Specification:是 SpringData JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件
SpringData JPA接口继承结构:
Repository
⬇
CrudRepository
⬇
PagingAndSortingRepository QueryByExampleExecutor
⬇ ⬇
JpaRepository JpaRepository JpaSpecificationExecutor
- Repository(org.springframework.data.repository):没有暴露任何方法
- CrudRepository(org.springframework.data.repository):简单的 Curd 方法
- PagingAndSortingRepository(org.springframework.data.repository):带分页和排序的方法
- QueryByExampleExecutor(org.springframework.data.repository.query))简单 Example 查询
- JpaRepository(org.springframework.data.jpa.repository):JPA 的扩展方法
- JpaSpecificationExecutor(org.springframework.data.jpa.repository)):JpaSpecification 扩展查询
- QueryDslPredicateExecutor(org.springframework.data.querydsl):QueryDsl 的封装
- SimpleJpaRepository(org.springframework.data.jpa.repository.support)):JPA 所有接口的默认实现类
- QueryDslJpaRepository(org.springframework.data.jpa.repository.support):QueryDsl 的实现类
2、SpringData Repository 接口
Repository 接口自带了如下两种查询方式:
- 1)提供了方法名称命名查询方式、
- 2)提供了@Query注解查询与更新
作用主要是把当前接口加入SpringDataJPA中,使其拥有SpringDataJPA的功能。后面会介绍如上2种查询方式。
持久层接口继承 Repository 并不是唯一选择。Repository 接口是 SpringData 的一个核心接口,它不提供任何方法,开发者需要在自己定义的接口中声明需要的方法。
与继承 Repository 等价的一种方式,就是在持久层接口上使用 @RepositoryDefinition 注解,并为其指定 domainClass 和 idClass 属性。如下两种方式是完全等价的:
public interface UserRepository extends Repository<User, Long> {} @RepositoryDefinition(domainClass = User.class, idClass = Long.class) public interface UserRepository {}
1、CrudRepository
CrudRepository 接口主要是完成一些增删改查的操作。CrudRepository 继承了 Repository 。查看 CrudRepository 源码,该接口提供了11个常用操作方法
// T 是要操作的实体类,ID 是实体类主键的类型
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
// 单个保存
<S extends T> S save(S entity);
// 批量保存
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
// 根据id查询一个Optional
Optional<T> findById(ID id);
// 根据id判断对象是否存在
boolean exists(ID id);
// 查询所有的对象
Iterable<T> findAll();
// 根据id列表查询所有的对象
Iterable<T> findAllById(Iterable<ID> ids);
// 计算对象的总个数
long count();
// 根据id删除
void delete(ID id);
// 删除一个对象
void delete(T entity);
// 批量删除,集合对象(后台执行时,一条一条删除)
void delete(Iterable<? extends T> entities);
// 删除所有 (后台执行时,一条一条删除)
void deleteAll();
}
1、创建Repository层接口,并且继承 CrudRepository 接口
/**
* CrudRepository 接口
* 主要是完成一些增删改查的操作。注意:CrudRepository接口继承了Repository接口
*/
public interface UserCrudRepository extends CrudRepository<User,Long> {
}
2、测试代码
package com.example.jpa;
import com.example.jpa.entity.User;
import com.example.jpa.repository.UserCrudRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.annotation.Rollback;
import javax.transaction.Transactional;
import java.util.Arrays;
import java.util.Optional;
@SpringBootTest
public class UserCrudRepositoryTests {
@Autowired
private UserCrudRepository userCrudRepository;
/**
* 数据保存:
* 1.添加单条数据
* 2.批量添加数据
*/
@Test
public void testSave(){
// 保存单个数据
User user = new User();
user.setUsername("隔壁小王");
user.setPassword("password");
user.setAge(18);
User save = this.userCrudRepository.save(user);
System.out.println(save);
// 保存多条数据
User userA = new User();
userA.setUsername("赵小丽");
userA.setPassword("666666");
userA.setAge(21);
User userB = new User();
userB.setUsername("王小虎");
userB.setPassword("123456");
userB.setAge(25);
Iterable<User> saveAll = this.userCrudRepository.saveAll(Arrays.asList(userA, userB));
saveAll.forEach(System.out::println);
}
/**
* 数据查询:
* 1.根据ID查询单条数据
* 2.查询全部数据
* 3.根据多个id查询多条数据
* 4.根据ID判断数据是否存在
* 5.查询该表(实体类)有多少数据
*/
@Test
public void testFind(){
// 1.根据ID查询单条数据
Optional<User> user = this.userCrudRepository.findById(1L);
System.out.println(user.get());
System.err.println("--------------华丽的分割线-------------------");
// 2.查询全部数据
Iterable<User> userIterableA = this.userCrudRepository.findAll();
userIterableA.forEach(System.out::println);
System.err.println("--------------华丽的分割线-------------------");
// 3.根据多个id查询多条数据
Iterable<User> userIterableB = this.userCrudRepository.findAllById(Arrays.asList(1L, 2L));
userIterableB.forEach(System.out::println);
System.err.println("--------------华丽的分割线-------------------");
// 4.根据ID判断数据是否存在
System.out.println(this.userCrudRepository.existsById(1L));
System.err.println("--------------华丽的分割线-------------------");
// 5.查询该表(实体类)有多少数据
System.out.println(this.userCrudRepository.count());
}
/**
* 更新数据方式一: save()方法
*/
@Test
public void testUpdate1(){
// 持久化状态的
User user = this.userCrudRepository.findById(1L).get();
user.setUsername("王小红");
this.userCrudRepository.save(user);
}
/**
* 更新数据方式二: 设置对象属性自动更新数据库
* 【持久态对象的属性被修改后,,在数据库事物提交的时候,会更新数据库】
*/
@Test
@Transactional
@Rollback(false)
public void testUpdate2(){
// 持久化状态,当前方法加了事物,SpringDataJPA在事物完成的时候,会自动提交修改
User user = this.userCrudRepository.findById(1L).get();
user.setUsername("王小小");
}
/**
* 删除数据
* 1.根据id删除
* 2.根据实体类删除单个数据
* 3.根据实体类数组删除多调数据
* 4.删除全部数据
*/
@Test
public void testDelete(){
// 1.根据id删除
this.userCrudRepository.deleteById(1L);
// 2.根据实体类删除单个数据
User user = this.userCrudRepository.findById(2L).get();
this.userCrudRepository.delete(user);
// 3.根据实体类数组删除多调数据
this.userCrudRepository.deleteAll(this.userCrudRepository.findAllById(Arrays.asList(1L, 2L)));
// 4.删除全部数据
this.userCrudRepository.deleteAll();
}
}
3、查看日志:数据保存 testSave()
Hibernate:
insert
into
sys_user
(age, password, username)
values
(?, ?, ?)
User(id=2, username=隔壁小王, password=password, age=18)
Hibernate:
insert
into
sys_user
(age, password, username)
values
(?, ?, ?)
Hibernate:
insert
into
sys_user
(age, password, username)
values
(?, ?, ?)
User(id=3, username=赵小丽, password=666666, age=21)
User(id=4, username=王小虎, password=123456, age=25)
4、查看日志:数据查询 testFind()
Hibernate:
select
user0_.id as id1_1_0_,
user0_.age as age2_1_0_,
user0_.password as password3_1_0_,
user0_.username as username4_1_0_
from
sys_user user0_
where
user0_.id=?
User(id=1, username=admin, password=password, age=18)
--------------华丽的分割线-------------------
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
User(id=1, username=admin, password=password, age=18)
User(id=2, username=隔壁小王, password=password, age=18)
User(id=3, username=赵小丽, password=666666, age=21)
User(id=4, username=王小虎, password=123456, age=25)
--------------华丽的分割线-------------------
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.id in (
? , ?
)
User(id=1, username=admin, password=password, age=18)
User(id=2, username=隔壁小王, password=password, age=18)
--------------华丽的分割线-------------------
Hibernate:
select
count(*) as col_0_0_
from
sys_user user0_
where
user0_.id=?
true
--------------华丽的分割线-------------------
Hibernate:
select
count(*) as col_0_0_
from
sys_user user0_
5、查看日志:数据更新方式一 testUpdate1(),可以发现查询了2次Select(第二次select是save()方法查询的)
Hibernate:
select
user0_.id as id1_1_0_,
user0_.age as age2_1_0_,
user0_.password as password3_1_0_,
user0_.username as username4_1_0_
from
sys_user user0_
where
user0_.id=?
Hibernate:
select
user0_.id as id1_1_0_,
user0_.age as age2_1_0_,
user0_.password as password3_1_0_,
user0_.username as username4_1_0_
from
sys_user user0_
where
user0_.id=?
Hibernate:
update
sys_user
set
age=?,
password=?,
username=?
where
id=?
6、查看日志:数据更新方式二 testUpdate2(),可以发现只查询了1次Select
Hibernate:
select
user0_.id as id1_1_0_,
user0_.age as age2_1_0_,
user0_.password as password3_1_0_,
user0_.username as username4_1_0_
from
sys_user user0_
where
user0_.id=?
Hibernate:
update
sys_user
set
age=?,
password=?,
username=?
where
id=?
2、PagingAndSortingRepository
该接口提供了两个方法,实现了分页和排序的功能了,该接口继承了 CrudRepository 接口。查看 PagingAndSortingRepository 接口源码:
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort); // 仅排序
Page<T> findAll(Pageable pageable); // 分页和排序
}
1、创建Repository层接口,并且继承 PagingAndSortingRepository 接口
/**
* PagingAndSortingRepository 接口:
* 该接口提供了分页与排序的操作,注意:该接口继承了CrudRepository接口
*/
public interface UserPagingAndSortingRepository extends PagingAndSortingRepository<User,Integer> {
}
2、测试代码
package com.example.jpa;
import com.example.jpa.entity.User;
import com.example.jpa.repository.UserPagingAndSortingRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
@SpringBootTest
public class UserPagingAndSortingTests {
@Autowired
private UserPagingAndSortingRepository userPagingAndSortingRepository;
/**
* 分页操作
*/
@Test
public void test1(){
/**
* Pageable:封装了分页的参数,当前页,每页显示的条数。注意:当前页是从0开始
* PageRequest(page, size):page表示当前页,size表示每页显示多少条
*/
Pageable pageable = PageRequest.of(0, 2);
Page<User> page = this.userPagingAndSortingRepository.findAll(pageable);
System.out.println("总记录数: " + page.getTotalElements());
System.out.println("当前第几页: " + (page.getNumber() + 1));
System.out.println("总页数: " + page.getTotalPages());
System.out.println("当前页面的 List: " + page.getContent());
System.out.println("当前页面的记录数: " + page.getNumberOfElements());
page.getContent().forEach(System.out::println);
}
/**
* 排序操作:
* 1.对单列做排序处理
* 2.多列的排序处理
*/
@Test
public void test2(){
/**
* Sort:该对象封装了排序规则以及指定的排序字段(对象的属性来表示)
* direction:排序规则(Sort.Direction.DESC)
* properties:指定做排序的属性(id)
*/
// 1.对单列做排序处理,对id做降序排序
Sort sortOne = Sort.by(Sort.Direction.DESC,"id");
Iterable iterable = this.userPagingAndSortingRepository.findAll(sortOne);
iterable.forEach(System.out::println);
System.err.println("--------------华丽的分割线-------------------");
/**
* 可以用如下两种方式得到Order
* 1.new Sort.Order()
* 2.Sort.Order.desc()/asc()/by()
*/
// 2.多列的排序处理,先对age列做降序处理,然后对id字段做升序处理
Sort.Order age = Sort.Order.desc("age");
Sort.Order id = new Sort.Order(Sort.Direction.ASC,"id");
Sort sortMany = Sort.by(age,id);
this.userPagingAndSortingRepository.findAll(sortMany).forEach(System.out::println);
}
/**
* 分页 + 排序 处理
*
*/
@Test
public void test3(){
// 排序操作对象
Sort.Order age = Sort.Order.desc("age");
Sort.Order id = Sort.Order.asc("id");
Sort sort = Sort.by(age,id);
// 排序操作还是没变化,只需要在PageRequest.of内多加一个Sort参数
Pageable pageable = PageRequest.of(0, 2 ,sort);
Page<User> page = this.userPagingAndSortingRepository.findAll(pageable);
System.out.println("总记录数: " + page.getTotalElements());
System.out.println("当前第几页: " + (page.getNumber() + 1));
System.out.println("总页数: " + page.getTotalPages());
System.out.println("当前页面的记录数: " + page.getNumberOfElements());
System.out.println("当前页面的 List: " + page.getContent());
System.err.println("--------------华丽的分割线-------------------");
page.getContent().forEach(System.out::println);
}
}
查看日志:分页操作 test1()
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_ limit ?
Hibernate:
select
count(user0_.id) as col_0_0_
from
sys_user user0_
总记录数: 4
当前第几页: 1
总页数: 2
当前页面的 List: [User(id=1, username=王小小, password=password, age=18), User(id=2, username=隔壁小王, password=password, age=18)]
当前页面的记录数: 2
User(id=1, username=王小小, password=password, age=18)
User(id=2, username=隔壁小王, password=password, age=18)
查看日志:排序操作 test2()
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
order by
user0_.id desc
User(id=4, username=王小虎, password=123456, age=25)
User(id=3, username=赵小丽, password=666666, age=21)
User(id=2, username=隔壁小王, password=password, age=18)
User(id=1, username=王小小, password=password, age=18)
--------------华丽的分割线-------------------
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
order by
user0_.age desc,
user0_.id asc
User(id=4, username=王小虎, password=123456, age=25)
User(id=3, username=赵小丽, password=666666, age=21)
User(id=1, username=王小小, password=password, age=18)
User(id=2, username=隔壁小王, password=password, age=18)
查看日志:分页 + 排序操作 test3()
Hibernate:
select
user0_.id as id1_0_,
user0_.age as age2_0_,
user0_.password as password3_0_,
user0_.username as username4_0_
from
sys_user user0_
order by
user0_.age desc,
user0_.id asc limit ?
Hibernate:
select
count(user0_.id) as col_0_0_
from
sys_user user0_
总记录数: 3
当前第几页: 1
总页数: 2
当前页面的记录数: 2
当前页面的 List: [User(id=6, username=王小虎, password=123456, age=25), User(id=5, username=赵小丽, password=666666, age=21)]
--------------华丽的分割线-------------------
User(id=6, username=王小虎, password=123456, age=25)
User(id=5, username=赵小丽, password=666666, age=21)
3、JpaRepository
该接口继承了PagingAndSortingRepository。是我们开发时使用的最多的接口。其特点是可以帮助我们将其他接口的方法的返回值做适配处理。可以使得我们在开发时更方便的使用这些方法。同时也继承QueryByExampleExecutor接口,这是个用“实例”进行查询的接口,后续再写文章详细说明。
查看 JpaRepository 接口源码(这个接口的几个方法跟之前的接口内的方法虽然一样,但是最返回值做了自适应):
@NoRepositoryBean
public interface JpaRepository<T, ID extends Serializable>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
@Override
List<T> findAll(); // 查询所有对象,返回List
@Override
List<T> findAll(Sort sort); // 查询所有对象,并排序,返回List
@Override
List<T> findAllById(Iterable<ID> ids); // 根据id列表 查询所有的对象,返回List
@Override
<S extends T> List<S> saveAll(Iterable<S> entities); // 批量保存,并返回对象List
<S extends T> S saveAndFlush(S entity); // 保存并强制同步数据库
void flush(); // 强制缓存与数据库同步
void deleteInBatch(Iterable<T> entities); // 批量删除 集合对象(后台执行时,生成一条语句执行,用多个or条件)
void deleteAllInBatch(); // 删除所有 (执行一条语句,如:delete from user)
T getOne(ID id); // 根据id查询对象,返回对象的引用(区别于findOne)。当对象不存时,返回引用不是null,但各个属性值是null
@Override
<S extends T> List<S> findAll(Example<S> example); // 根据实例查询
@Override
<S extends T> List<S> findAll(Example<S> example, Sort sort);// 根据实例查询并排序
}
1、创建Repository层接口,并且继承 JpaRepository 接口
/**
* JpaRepository 接口
* 该接口继承了PagingAndSortingRepository。是我们开发时使用的最多的接口。
* 接口其特点是可以帮助我们将其他接口的方法的返回值做适配处理。可以使得我们在开发时更方便的使用这些方法。
*/
public interface UserJpaRepository extends JpaRepository<User,Long> {
}
2、测试代码
package com.example.jpa;
import com.example.jpa.entity.User;
import com.example.jpa.repository.UserJpaRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Sort;
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
@SpringBootTest
public class UserJpaRepositoryTests {
@Autowired
private UserJpaRepository userJpaRepository;
/**
* 这几个方法跟之前的接口内的方法虽然一样,但是最返回值做了自适应
* 返回值都由 Iterable 变成了 List
*/
@Test
public void test1(){
List<User> usersA = this.userJpaRepository.findAll();
usersA.forEach(System.out::println);
System.err.println("--------------华丽的分割线-------------------");
List<User> usersB = this.userJpaRepository.findAll(Sort.by("age"));
usersB.forEach(System.out::println);
System.err.println("--------------华丽的分割线-------------------");
List<User> usersC = this.userJpaRepository.findAllById(Arrays.asList(1L, 2L));
usersC.forEach(System.out::println);
System.err.println("--------------华丽的分割线-------------------");
User user = new User();
user.setUsername("隔壁小王");
user.setPassword("password");
user.setAge(18);
List<User> users = this.userJpaRepository.saveAll(Arrays.asList(user));
System.out.println(users);
}
/**
* JpaRepository 接口内还新增了一方法
* flush():强制写入数据库
* saveAndFlush:保存并且立马写入数据库(不需要等事务走完就写入数据库)
*/
@Test
public void test2(){
User user = new User();
user.setUsername("隔壁小王");
user.setPassword("password");
user.setAge(18);
// 立马写入数据库
User saveAndFlush = this.userJpaRepository.saveAndFlush(user);
System.out.println(saveAndFlush);
}
/**
* 批量删除方法:deleteInBatch(Iterable<T> var1) 和 deleteAllInBatch()
* 之前CrudRepository 接口内也有删除方法:delete、deleteById、deleteAll
* 对比:deleteAll() 和 deleteAllInBatch() 区别:
* deleteAll()是删除全部,先findALL查找出来,再一条一条删除,最后提交事务
* deleteAllInBatch()是删除全部,一条sql。显然:deleteAllInBatch()方法效率更高
*
* 分别执行批量删除方法,查看日志对比.可以得出结论:
* 在进行批量删除操作时尽量使用JpaRepository自带的批量删除方法deleteInBatch()及deleteAllInBatch()
*
* 可参考:https://jingyan.baidu.com/article/597a06431601fb312b52431c.html
*/
@Test
public void test3(){
// 不推荐使用
this.userJpaRepository.deleteAll();
}
@Test
public void test4(){
// 推荐使用
this.userJpaRepository.deleteAllInBatch();
}
/**
* getOne()与findById()方法总结与区别:
* 1、getOne() 是延迟加载。findById() 是立马加载
* 2、getOne()返回一个实体的引用,无结果会抛出异常。findById()返回一个Optional对象
* 3、getOne()属于JpaRepository,底层调用getReference()方法,懒加载的模式,当调用对象时才会发送SQL
* 4、findById()属于CrudRepository,底层调用了find()方法,当调用该方法的时就直接发送SQL
*/
@Test
public void test5(){
// getOne()返回一个实体的引用,无结果会抛出异常
User user = this.userJpaRepository.getOne(1L);
System.out.println(user);
// findById()返回一个Optional对象,如果Optional为空get()会抛异常
Optional<User> optional = this.userJpaRepository.findById(1L);
System.out.println(optional.orElse(null));
}
}
查看日志:查询操作 test1() 方法
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
User(id=1, username=王小小, password=password, age=18)
--------------华丽的分割线-------------------
User(id=2, username=隔壁小王, password=password, age=18)
User(id=3, username=赵小丽, password=666666, age=21)
User(id=4, username=王小虎, password=123456, age=25)
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
order by
user0_.age asc
User(id=1, username=王小小, password=password, age=18)
User(id=2, username=隔壁小王, password=password, age=18)
User(id=3, username=赵小丽, password=666666, age=21)
User(id=4, username=王小虎, password=123456, age=25)
--------------华丽的分割线-------------------
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.id in (
? , ?
)
User(id=1, username=王小小, password=password, age=18)
User(id=2, username=隔壁小王, password=password, age=18)
--------------华丽的分割线-------------------
Hibernate:
insert
into
sys_user
(age, password, username)
values
(?, ?, ?)
[User(id=5, username=隔壁小王, password=password, age=18)]
查看日志:新增操作 test2() 方法
Hibernate:
insert
into
sys_user
(age, password, username)
values
(?, ?, ?)
User(id=6, username=隔壁小王, password=password, age=18)
查看日志:批量删除操作 test3() 方法
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
Hibernate:
delete
from
sys_user
where
id=?
Hibernate:
delete
from
sys_user
where
id=?
Hibernate:
delete
from
sys_user
where
id=?
...
查看日志:批量删除操作 test4() 方法(推荐使用)
Hibernate:
delete
from
sys_user
总结对比:deleteAll() 和 deleteAllInBatch() 方法的区别:
- deleteAll():是删除全部,先findAll()查找出来,再一条一条删除,最后提交事务
- deleteAllInBatch():是删除全部,不过一条sql。显然:deleteAllInBatch() 方法效率更高
- 在进行批量删除操作时尽量使用JpaRepository自带的批量删除方法:deleteInBatch() 及 deleteAllInBatch()
- 可参考:https://jingyan.baidu.com/article/597a06431601fb312b52431c.html
查看日志:test5(),getOne() 可能会报错:org.hibernate.LazyInitializationException: could not initialize proxy XXX - no Session
org.hibernate.LazyInitializationException: could not initialize proxy [com.example.jpa.entity.User#4] - no Session
at org.hibernate.proxy.AbstractLazyInitializer.initialize(AbstractLazyInitializer.java:170)
at org.hibernate.proxy.AbstractLazyInitializer.getImplementation(AbstractLazyInitializer.java:310)
at org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor.intercept(ByteBuddyInterceptor.java:45)
at org.hibernate.proxy.ProxyConfiguration$InterceptorDispatcher.intercept(ProxyConfiguration.java:95)
at com.example.jpa.entity.User$HibernateProxy$7rZgySgi.toString(Unknown Source)
at java.lang.String.valueOf(String.java:2994)
at java.io.PrintStream.println(PrintStream.java:821)
at com.example.jpa.UserJpaRepositoryTests.test5(UserJpaRepositoryTests.java:95)
原因:没有开启懒加载。解决方案如下:问题解决参考:https://www.gaoyaxuan.net/blog/229.html
方案一:在出问题的实体类上加:@Proxy(lazy = false)
// 默认懒加载,false为急加载
@Proxy(lazy = false)
public class User {}
方案二:、application.properties 文件中开启延迟加载的配置
# 开启延迟加载,这个配置的意思就是在没有事务的情况下允许懒加载
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
3、SpringData 规定方法名查询
支持的查询方法主题关键字(前缀)(只有查询和删除)
1、方法名称命名规则查询
按照 SpringData 定义的规则,查询方法以 find | read | get 开头(比如 find、findBy、read、readBy、get、getBy),涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。如果方法的最后一个参数是 Sort 或者 Pageable 类型,也会提取相关的信息,以便按规则进行排序或者分页查询。【PS:方法名命名规则不能对其增加(insert)和修改(update),但是可以删除(delete)】
查询主题关键字:
| 关键字 | 描述 |
|---|---|
| find..By、read..By、get..By、query..By、search..By、stream..By | 通过查询方法通常返回存储类型、Collection或Streamable子类型或结果包装器,例如:page、GeoResults或任何其他特定于商店的结果包装器,可用作:findBy..、findByMyDomainTypeBy..或其他关键字结合使用 |
| exists..By | 存在投影,通常返回Boolean结果 |
| count..By | 计数投影返回数据结果 |
| delete..By、remove..By | 删除查询方法,返回void或者删除计数 |
| first<bumber>By、Top<bumber>By | 将查询结果限制为第一个<bumber>结果,此关键字可以出现在find(和其他关键字)之间的任何位置by |
| ..Distinct.. | 使用不同的查询仅返回唯一的结果,关此键字可以出现在find(和其他关键字)之间的任何位置by |
谓语关键字和修饰符,常用规则速查:
| 关键字 | SQL符号 | 方法命名 | sql where 子句 |
|---|---|---|---|
| And | and | findByNameAndPwd | where name= ? and pwd =? |
| Or | or | findByNameOrSex | where name= ? or sex=? |
| Is、Equals | = | findById、findByIdEquals | where id = ? |
| Between | between xx and xx | findByIdBetween | where id between ? and ? |
| LessThan | < | findByIdLessThan | where id < ? |
| LessThanEqual | <= | findByIdLessThanEqual | where id <= ? |
| GreaterThan | > | findByIdGreaterThan | where id > ? |
| GreaterThanEqual | >= | findByIdGreaterThanEqual | where id > = ? |
| After | > | findByIdAfter | where id > ? |
| Before | < | findByIdBefore | where id < ? |
| IsNull | is null | findByNameIsNull | where name is null |
| isNotNull,NotNull | is not null | findByNameNotNull | where name is not null |
| Like | like | findByNameLike | where name like ? |
| NotLike | not like | findByNameNotLike | where name not like ? |
| StartingWith | like ‘xx%’ | findByNameStartingWith | where name like ‘?%’ |
| EndingWith | like ‘%xx’ | findByNameEndingWith | where name like ‘%?’ |
| Containing | like ‘%xx%’ | findByNameContaining | where name like ‘%?%’ |
| OrderBy | order by | findByIdOrderByXDesc | where id=? order by x desc |
| Not | <>、!= | findByNameNot | where name <> ? |
| In | in() | findByIdIn(Collection<?> c) | where id in (?) |
| NotIn | not in() | findByNameNot | where name <> ? |
| True | =true | findByAaaTue | where aaa = true |
| False | =false | findByAaaFalse | where aaa = false |
| IgnoreCase | upper(x)=upper(y) | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
| top | top、rownum<=x | findTop10 | top 10 / where ROWNUM <=10 |
规则: findBy(主题关键字) + 属性名称(属性名称的首字母大写) + 查询条件(首字母大写)
规则: existsBy(主题关键字) + 属性名称(属性名称的首字母大写) + 查询条件(首字母大写)
规则: findFirstBy(主题关键字) + 属性名称(属性名称的首字母大写) + 查询条件(首字母大写)
规则: deleteBy(主题关键字) + 属性名称(属性名称的首字母大写) + 查询条件(首字母大写)
举例说明:
例如:findByUserAddressZip()。框架在解析该方法时,首先剔除 findBy,然后对剩下的属性进行解析,详细规则如下(此处假设该方法针对的域对象为 AccountInfo 类型):
- 先判断 userAddressZip (根据POJO规范,首字母变为小写)是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步
- 从右往左截取第一个大写字母开头的字符串(此处为 Zip),然后检查剩下的字符串是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设 user 为 AccountInfo 的一个属性;
- 接着处理剩下部分(AddressZip )先判断 user 所对应的类型是否有 addressZip 属性,如果有,则表示该方法最终是根据 “AccountInfo.user.addressZip” 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 “AccountInfo.user.address.zip” 的值进行查询。
可能会存在一种特殊情况,比如 AccountInfo 包含一个 user 的属性,也有一个 userAddress 属性,此时会存在混淆。读者可以明确在属性之间加上 “_“ 以显式表达意图,比如 “findByUser_AddressZip()” 或者 “findByUserAddress_Zip()”(强烈建议:无论是否存在混淆,都要在不同类层级之间加上”_” ,增加代码可读性)
2、方法名查询:条件为空
举例说明如下:
- 实体定义:对于一个客户实体 User,包含字段:username、password,均是 String 类型。
- 查询方法定义:
List<User> findByUsernameAndPassword(String username,String password); - 使用时:
repository.findByUsernameAndPassword(null, "123456"); - 后台生成SQL片断:
where (user0_.username is null) and user0_.password=? - 结论:当查询时传值是 null 时,数据库中只有该字段是 null 的记录才符合条件,并不是说忽略这个条件。也就是说,这种查询方式,只适合于明确查询条件必须传的业务,对于动态查询,这种简单查询是不能满足要求的。
3、方法名查询:排序功能
/**
* 假如你需要所有的数据而不需要按照条件查询,就要按照这样来写:
* findBy/getBy/queryBy.. + OrderBy + 排序字段 + 排序方式
* 按照 username 默认正序排序
* ..order by username
*/
List<User> findByOrderByUsername();
/**
* 查询全部数据:先按age字段倒序再按照id字段正序排序
* ..order by age desc, id asc
*/
List<User> findByOrderByAgeDescIdAsc();
/**
* 查询名称结果集按正序排序:
* ...where username = ? order by age asc
*/
List<User> findByUsernameOrderByAgeAsc(String username);
/**
* 查询名称结果集按倒序排序:
* ...where username = ? order by id desc
*/
List<User> findByUsernameOrderByIdDesc(String username);
4、方法名查询:限定结果集大小
/**
* 说明:对表的全部数据根据age进行Asc(升序)排序后再选择第一条数据返回
* SQL:...order by age asc limit 1
* 注意:findFirst3ByOrderByAgeAsc()/findTop3ByOrderByAgeAsc()则每次返回3条 limit 3
*/
User findFirstByOrderByAgeAsc();
User findTopByOrderByAgeAsc();
/**
* 说明:首先进行数据查询并通过Sort进行排序后 再筛选数据列表中最前面的2行数据返回 limit 2
* SQL:where username = ? order by field asc/desc
*/
List<User> findFirst2ByUsername(String username, Sort sort);
List<User> findTop2ByUsername(String username,Sort sort);
/**
* 说明:首先进行数据查询,查询全部指定的username后进行分页,分页完后进行数据控制
* 控制说明:
* 关于带分页的控制是,假设分页过后查询的数据id为3,4,5 查询出这三条数据后进行数据控制,
* 本案例是控制为2条,那返回的id数据就是3,4两条记录,id为5的就舍弃,
* 那么如果数据控制是5条(Top5),那么就会打印3,4,5另外再去添加6,7补充数据长度
*/
Page<User> queryFirst2ByUsername(String username, Pageable pageable);
List<User> queryTop2ByUsername(String username, Pageable pageable);
总结:这里的 First 和 Top 意思相同都是最前面,query 也和 find 一样
5、方法名查询:计数
/**
* 计数 返回总数
* countBy()等同于countAllBy()
* SQL:
* select count(id) from sys_user where username = ?
* select count(id) from sys_user
*/
Long countByUsername(String username);
Long countAllBy();
6、方法名查询:删除数据
/**
* 说明:必须添加事务和回滚,这样根据条件找到几条就删几条
* 对应的SQL语句:
* Hibernate: select * from sys_user where username = ?
* Hibernate: delete from sys_user where id=?
* Hibernate: delete from sys_user where id=?
* ....
* 关于removeBy和deleteBy方法区别:
* 他们是一样的 .选择哪一个取决于您的个人偏好.
*/
void deleteByUsername(String username);
void removeByUsername(String username);
4、JPQL与SQL查询(注解)
1、@Query查询与更新(JPQL)
@Query:通过 JPQL 语句查询与更新(JPQL:通过 Hibernate 的 HQL 演变过来的。他和 HQL 语法及其相似)
1、创建Repository接口:
/**
* Repository接口:使用@Query注解查询JPQL
* JPQL查询 和原生 SQL 查询,区别在于nativeQuery属性。
* nativeQuery:默认的是false,false为JPQL查询。true为开启SQL查询。
* 更新删除操作需要加上 @Modifying 注解(注意:不支持新增)
*/
public interface UserRepositoryJPQL extends Repository<User, Long> {
/**
* ? 展示位置参数绑定:?1
* 必须使用?1形式,如果有多个参数以此类推,如: ?1,?2..
* JPQL如果只输入?查询会报错,SQL查询不会
*/
@Query("from User where username = ?1")
List<User> queryUserByUsernameUseJPQL(String username);
/**
* : 展示名字参数绑定::username
* 注意:使用 :username 绑定,必须在参数前加@Param("username")
*/
@Query("from User where username like :username")
List<User> queryUserByLikeUsernameUseJPQL(@Param("username")String username);
@Query("from User where username = :username and age > :age")
List<User> queryUserByUsernameAndAgeUserJPQL(@Param("username")String username, @Param("age")Integer age);
/**
* JPQL 动态查询
*/
@Query("from User " +
"where (username = :username or :username is null) " +
"and (age > :age or :age is null)")
List<User> queryUserByUsernameAndAgeDynamicJPQL(@Param("username")String username, @Param("age")Integer age);
@Query("update User set username = ?1 where id = ?2")
@Modifying // 需要执行一个更新操作
Integer updateUsernameById(String username,Long id);
}
2、测试类:
@SpringBootTest
public class UserRepositoryJPQLTests {
@Autowired
private UserRepositoryJPQL userRepositoryJPQL;
/**
* 测试@Query查询 JPQL
*/
@Test
public void test1(){
List<User> listA = userRepositoryJPQL.queryUserByUsernameUseJPQL("王五");
listA.forEach(System.out::println);
}
@Test
public void test2(){
List<User> list = userRepositoryJPQL.queryUserByLikeUsernameUseJPQL("%王%");
list.forEach(System.out::println);
}
@Test
public void test3(){
List<User> list = userRepositoryJPQL.queryUserByUsernameAndAgeUserJPQL("隔壁小王", 15);
list.forEach(System.out::println);
}
/**
* 更新删除操作记得加上事务操作,不然会报错:
* Caused by: javax.persistence.TransactionRequiredException: Executing an update/delete query
*/
@Test
@Transactional // @Transactional与@Test 一起使用时 事务是自动回滚的。
@Rollback(false) // 取消自动回滚
public void test4(){
Integer integer = userRepositoryJPQL.updateUsernameById("隔壁小王", 5L);
System.out.println("更新数据行数:" + integer);
}
}
3、查看日志(更新操作)
Hibernate:
update
sys_user
set
username=?
where
id=?
更新数据行数:1
2、@Query查询与更新(SQL)
@Query:通过原生 SQL 语句查询与更新
1、创建Repository接口:
/**
* Repository接口:使用@Query注解查询SQL
* JPQL查询 和 SQL查询,区别在于nativeQuery属性。
* nativeQuery:默认的是false.表示不开启sql查询。是否对value中的语句做转义
* 更新删除操作需要加上 @Modifying 注解(注意:不支持新增)
*/
public interface UserRepositorySQL extends Repository<User, Long> {
/**
* ? 展示位置参数绑定:? 或者 ?1
*/
@Query(value = "select * from sys_user where username = ?1",nativeQuery=true)
List<User> queryUserByUsernameUseSQL(String username);
/**
* 如果有多个参数以此类推,如: ?1,?2..或者 ? ?....
* 如果只用?的话,方法中的参数必须按顺序填写,如果 ?1 则不用
* JPQL查询如果只输入?查询会报错,SQL查询不会
*/
@Query(value = "select * from sys_user where username = ?1 and age >= ?2",nativeQuery=true)
List<User> queryUserByUsernameAndAgeUseSQL(String name, Integer age);
/**
* : 展示名字参数绑定::username
* 注意:使用 :username 绑定,必须在参数前加@Param("username")
*/
@Query(value = "select * from sys_user where username like :username",nativeQuery=true)
List<User> queryUserByLikeUsernameUseSQL(@Param("username") String username);
@Query(value = "update sys_user set username = ? where id = ?",nativeQuery=true)
@Modifying // 需要执行一个更新操作
Integer updateUsernameById(String username,Long id);
}
2、测试代码
@SpringBootTest
public class UserRepositorySQLTests {
@Autowired
private UserRepositorySQL userRepositorySQL;
/**
* 测试@Query查询 SQL
*/
@Test
public void test1(){
List<User> list = this.userRepositorySQL.queryUserByUsernameUseSQL("隔壁小王");
list.forEach(System.out::println);
}
@Test
public void test2(){
List<User> list = this.userRepositorySQL.queryUserByUsernameAndAgeUseSQL("隔壁小王", 15);
list.forEach(System.out::println);
}
@Test
public void test3(){
List<User> list = this.userRepositorySQL.queryUserByLikeUsernameUseSQL("%王%");
list.forEach(System.out::println);
}
/**
* 更新删除操作记得加上事务操作,不然会报错:
* Caused by: javax.persistence.TransactionRequiredException: Executing an update/delete query
*/
@Test
@Transactional //@Transactional与@Test 一起使用时 事务是自动回滚的。
@Rollback(false) //取消自动回滚
public void test4(){
Integer integer = userRepositorySQL.updateUsernameById("隔壁小王", 5L);
System.out.println("更新数据行数:" + integer);
}
}
3、查看日志
Hibernate:
update
sys_user
set
username = ?
where
id = ?
更新数据行数:1
PS:从日志上看 JPQL 与 SQL 查询看不出什么区别,不过使用 SpringData 时推荐还是使用 JPQL 方式。
总结:
- 可以通过自定义的 JPQL 完成
UPDATE和DELETE操作。 注意: JPQL 不支持使用INSERT(新增操作) - 在
@Query注解中编写 JPQL 语句, 如果是UPDATE或DELETE操作,必须使用@Modifying修饰 UPDATE或DELETE操作需要使用事务,此时需要的 Service 层的方法上添加事务操作- 默认情况下, SpringData 的每个方法上有事务, 但都是一个只读事务。 他们不能完成修改操作
3、@NamedQuery查询(JPQL)
@NamedQuery 与 @NamedNativeQuery 都是定义查询的一种形式,@NamedQuery 使用的是JPQL,而 @NamedNativeQuery 使用的是原生SQL。这两种不常用,所以简单介绍一下。
1、使用 @NamedQuery、@NamedQueries 注解在实体类中定义命名查询(单个和多个命名查询)
@Data
@Entity
@Table(name = "sys_user")
@NamedQuery(name="User.findAllUserNamedQuery",query="from User") // name指定命名查询的名称,query属性指定命令查询的语句
@NamedQueries({ // 定义多个
@NamedQuery(name="User.findUserByUsernameNamedQuery",query="from User where username = ?1"),
@NamedQuery(name="User.findUserByLikeUsernameNamedQuery",query="from User where username like :username")
})
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String password;
private Integer age;
}
2、在Repository接口中声明方法
/**
* Repository接口:
* 在User.Java实体类使用@NamedQuery 与 @NamedNativeQuery 都是定义查询的一种形式,
* @NamedQuery 使用的是JPQL,而 @NamedNativeQuery 使用的是原生SQL。
* @NamedQuery 内的 name 就是本接口定义的方法名称
*/
public interface UserRepositoryNamedQuery extends Repository<User, Long> {
/**
* 使用@NamedQuery进行方法查询,方法名为@NamedQuery的name参数
*/
List<User> findAllUserNamedQuery();
List<User> findUserByUsernameNamedQuery(String name);
List<User> findUserByLikeUsernameNamedQuery(String username);
}
3、测试代码
package com.example.jpa;
import com.example.jpa.entity.User;
import com.example.jpa.repository.UserJpaRepository;
import com.example.jpa.repository.UserRepositoryNamedQuery;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
@SpringBootTest
public class UserRepositoryNamedQueryTests {
@Autowired
private UserJpaRepository userJpaRepository;
@BeforeEach
public void initData(){
// 保存多条数据
User userA = new User();
userA.setUsername("隔壁小王");
userA.setPassword("password");
userA.setAge(18);
User userB = new User();
userB.setUsername("赵小丽");
userB.setPassword("666666");
userB.setAge(21);
User userC = new User();
userC.setUsername("王小虎");
userC.setPassword("123456");
userC.setAge(25);
this.userJpaRepository.saveAll(Arrays.asList(userA, userB, userC)).forEach(System.out::println);
}
@Autowired
private UserRepositoryNamedQuery userRepositoryNamedQuery;
@Test
public void testNamedQuery(){
System.out.println(userRepositoryNamedQuery.findAllUserNamedQuery());
System.out.println(userRepositoryNamedQuery.findUserByUsernameNamedQuery("隔壁小王"));
System.out.println(userRepositoryNamedQuery.findUserByLikeUsernameNamedQuery("%王%"));
}
@Test
public void testNamedNativeQuery(){
System.out.println(userRepositoryNamedQuery.findAllUserNamedNativeQuery());
System.out.println(userRepositoryNamedQuery.findUserByUsernameNamedNativeQuery("隔壁小王"));
System.out.println(userRepositoryNamedQuery.findUserByLikeUsernameNamedNativeQuery("%王%"));
}
}
4、查看日志
// 省略数据初始化日志
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
[User(id=1, username=隔壁小王, password=password, age=18), User(id=2, username=赵小丽, password=666666, age=21), User(id=3, username=王小虎, password=123456, age=25)]
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.username=?
[User(id=1, username=隔壁小王, password=password, age=18)]
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.username like ?
[User(id=1, username=隔壁小王, password=password, age=18), User(id=3, username=王小虎, password=123456, age=25)]
4、@NamedNativeQuery查询(SQL)
1、使用 @NamedNativeQuery、@NamedNativeQueries 定义单个和多个命名查询(注意使用@NamedNativeQuery需要指定resultClass参数类型)
@Data
@Entity
@Table(name = "sys_user")
@NamedNativeQuery(name="User.findAllUserNamedNativeQuery",query="select * from sys_user", resultClass = User.class)
@NamedNativeQueries({
@NamedNativeQuery(name="User.findUserByUsernameNamedNativeQuery",query="select * from sys_user where username = ?1", resultClass = User.class),
@NamedNativeQuery(name="User.findUserByLikeUsernameNamedNativeQuery",query="select * from sys_user where username like :username", resultClass = User.class)
})
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String password;
private Integer age;
}
2、在Repository接口中声明方法
/**
* Repository接口:
* 在User.Java实体类使用@NamedQuery 与 @NamedNativeQuery 都是定义查询的一种形式,
* @NamedQuery 使用的是JPQL,而 @NamedNativeQuery 使用的是原生SQL。
* @NamedQuery 内的 name 就是本接口定义的方法名称
*/
public interface UserRepositoryNamedQuery extends Repository<User, Long> {
/**
* 使用@NamedNativeQuery进行方法查询,方法名为@NamedQuery的name参数
*/
List<User> findAllUserNamedNativeQuery();
List<User> findUserByUsernameNamedNativeQuery(String name);
List<User> findUserByLikeUsernameNamedNativeQuery(String username);
}
3、测试代码
package com.example.jpa;
import com.example.jpa.entity.User;
import com.example.jpa.repository.UserJpaRepository;
import com.example.jpa.repository.UserRepositoryNamedQuery;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
@SpringBootTest
public class UserRepositoryNamedQueryTests {
@Autowired
private UserJpaRepository userJpaRepository;
@BeforeEach
public void initData(){
// 保存多条数据
User userA = new User();
userA.setUsername("隔壁小王");
userA.setPassword("password");
userA.setAge(18);
User userB = new User();
userB.setUsername("赵小丽");
userB.setPassword("666666");
userB.setAge(21);
User userC = new User();
userC.setUsername("王小虎");
userC.setPassword("123456");
userC.setAge(25);
this.userJpaRepository.saveAll(Arrays.asList(userA, userB, userC)).forEach(System.out::println);
}
@Autowired
private UserRepositoryNamedQuery userRepositoryNamedQuery;
@Test
public void testNamedNativeQuery(){
System.out.println(userRepositoryNamedQuery.findAllUserNamedNativeQuery());
System.out.println(userRepositoryNamedQuery.findUserByUsernameNamedNativeQuery("隔壁小王"));
System.out.println(userRepositoryNamedQuery.findUserByLikeUsernameNamedNativeQuery("%王%"));
}
}
4、查看日志
// 省略数据初始化日志
Hibernate:
select
*
from
sys_user
[User(id=1, username=隔壁小王, password=password, age=18), User(id=2, username=赵小丽, password=666666, age=21), User(id=3, username=王小虎, password=123456, age=25)]
Hibernate:
select
*
from
sys_user
where
username = ?
[User(id=1, username=隔壁小王, password=password, age=18)]
Hibernate:
select
*
from
sys_user
where
username like ?
[User(id=1, username=隔壁小王, password=password, age=18), User(id=3, username=王小虎, password=123456, age=25)]
总结:
- @NamedQuery、@NamedNativeQuery注解也可以使用
<named-query>、<named-native-query />标签来替代写在orm.xml中。 - @NamedNativeQuery还可以与@SqlResultSetMapping(@EntityResult、@ConstructorResult、@ColumnResult、@FieldResult)注解配置使用,指定映射。
- @NamedQueries,@NamedNativeQueries、@SqlResultSetMappings用装多个@NamedQuery、@NamedNativeQuery、@SqlResultSetMapping
- 我们一般不推荐使用@NamedQuery、@NamedNativeQuery,而使用下面的@Query注解。
5、QueryByExampleExecutor 接口
- QueryByExampleExecutor、JpaSpecificationExecutor:https://mp.weixin.qq.com/s/gnWkFH8kvYDMzyMe7CqX0w
- 使用Specification与Example方式实现动态条件查询案例:https://blog.csdn.net/weixin_53142722/article/details/126097851
如上已经实现了基本的CRUD操作和分页及排序查找功能,还不足以应对工作中出现的复杂业务场景。下面介绍SpringDataJpa中的QueryByExampleExecutor、JpaSpecificationExecutor两个接口实现相对复杂的业务场景。
1、QueryByExampleExecutor 的介绍
按示例查询(QBE)是一种用户友好的查询技术,具有简单的接 口。它允许动态查询创建,并且不需要编写包含字段名称的查询。从 UML图中,可以看出继承JpaRepository接口后,自动拥有了按“实例”进行查询的诸多方法。可见SpringData的团队已经认为了QBE是 SpringJPA的基本功能了,继承 QueryByExampleExecutor和 继承 JpaRepository 都会有这些基本方法。所以 QueryByExampleExecutor 位于 Spring Data Common 中。因为JpaRepository 接口已经继承了QueryByExampleExecutor接口,所以一般我们直接继承JpaRepository即可使用QueryByExampleExecutor了。
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {}
QueryByExampleExecutor 的特点:
- 支持动态查询。即支持查询条件个数不固定的情况,如:用户列表中有多个过滤条件,用户使用时在“用户名”查询框中输入了值,就需要按用户名进行过滤,如果没有输入值,就忽略这个过滤条件。对应的实现是,在构建查询条件UserInfo对象时,将email属性值设置为具体的条件值或设置为null。
- 不支持过滤条件分组。即不支持过滤条件用or(或)来连接,所有的过滤查件,都是简单一层的用and(并且)连接。例如: firstname = ?0 or (firstname = ?1 and lastname = ?2)。
- 正是由于这个限制,有些查询是没办法支持的,例如要查询某个时间段内添加的客户,对应的属性是addTime,需要传入“开始时间”和“结束时 间”两个条件值,而这种查询方式没有存两个值的位置,所以就没办法完成这样的查询。
QueryByExampleExecutor 的限制:
- 属性不支持嵌套或者分组约束,比如这样的查询 firstname = ?0 or (firstname = ?1 and lastname = ?2)
- 灵活匹配只支持字符串类型,其他类型只支持精确匹配
1、QueryByExampleExecutor 接口详细
public interface QueryByExampleExecutor<T> {
// 根据“实体”查询条件,查找⼀个对象,如返回空则抛org.springframework.dao.IncorrectResultSizeDataAccessException异常
<S extends T> Optional<S> findOne(Example<S> example);
/** 根据样例查找符合条件的所有对象集合 **/
<S extends T> Iterable<S> findAll(Example<S> example);
/** 根据样例查找符合条件的所有对象集合,并根据排序条件排好序 **/
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort);
/** 根据样例查找符合条件的所有对象集合,并根据分页条件分页 * */
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);
/** 查询符合样例条件的记录数样 **/
<S extends T> long count(Example<S> example);
/** 检查数据库表中是否包含符合样例条件的记录,存在返回true,否则返回false **/
<S extends T> boolean exists(Example<S> example);
}
所以看Example基本上就可以掌握的它的用法和API了。注意: Example接口在org.springframework.data.domain包下
public interface Example<T> {
/** 创建一个泛型对象的样例,泛型对象必须是与数据库表中一条记录对应的实体类 **/
static <T> Example<T> of(T probe) {
returnnew TypedExample<>(probe, ExampleMatcher.matching());
}
/** 根据实体类和匹配规则创建一个样例 **/
static <T> Example<T> of(T probe, ExampleMatcher matcher) {
returnnew TypedExample<>(probe, matcher);
}
/** 获取样例中的实体类对象 **/
T getProbe();
/** 获取样例中的匹配器 **/
ExampleMatcher getMatcher();
/** *获取样例中的实体类类型 **/
@SuppressWarnings("unchecked")
default Class<T> getProbeType() {
return (Class<T>) ProxyUtils.getUserClass(getProbe().getClass());
}
}
从源码中可以看出Example主要包含三部分内容:
- Probe:这是具有填充字段的域对象的实际实体类,即查询条件的封装类。必填。(又可以理解为:查询条件参数)
- ExampleMatcher:有关于如何匹配特定字段的匹配规则,可以重复使用在多个示例。必填。如果不填,用默认的。(又可以理解为参数的匹配规则)
- Example:Example由Probe(探针)和ExampleMatcher组成,用于创建查询。(又可以理解为组合查询参数和参数的匹配规则)
2、QueryByExampleExecutor 的使用
1、创建Repository层接口,继承JpaRepository即可,因为JpaRepository继承了QueryByExampleExecutor,所以无需单独继承。
/**
* PagingAndSortingRepository 接口
* 因为JpaRepository继承了QueryByExampleExecutor,所以无需单独继承
*/
public interface UserQueryByExampleExecutor extends JpaRepository<User,Long> {
}
2、使用Example查询单个对象
@Autowired
private UserQueryByExampleExecutor userQueryByExampleExecutor;
@Test
public void findOneByExample() {
// 设置查询条件对象(字段有值都会查询,只是看查any或all,如果某个字段有值又想忽略请用.withIgnorePaths()方法)
User user = new User();
user.setUsername("隔壁小王");
user.setPassword("password");
// 构建ExampleMatcher对象,matchingAll表示要匹配所有
ExampleMatcher exampleMatcher = ExampleMatcher.matchingAll();
// username字段使用精准匹配的方式, passwor没有设置匹配模式,默认也是精准匹配
exampleMatcher.withMatcher("username",
ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.EXACT, true));
// 利用Example类的静态构造函数构造Example实例对象
Example<User> example = Example.of(user, exampleMatcher);
System.out.println(userQueryByExampleExecutor.findOne(example).get());
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
user0_.username in (
select
user1_.username
from
sys_user user1_
where
user1_.username=?
)
User(id=1, username=隔壁小王, password=password, age=18)
3、使用Example查询所有对象
@Autowired
private UserQueryByExampleExecutor userQueryByExampleExecutor;
@Test
public void findAllByExample() {
// 设置查询条件对象(字段有值都会查询,只是看查any或all,如果某个字段有值又想忽略请用.withIgnorePaths()方法)
User user = new User();
user.setId(1L);
user.setUsername("隔壁");
user.setPassword("xxx");
user.setAge(99999);
// 匹配任意一个符合条件的字段(or)
ExampleMatcher exampleMatcher = ExampleMatcher.matchingAny()
// 模糊查询匹配开头,即{username}%
.withMatcher("username", ExampleMatcher.GenericPropertyMatchers.startsWith())
// 全部模糊查询,即%{password}%
.withMatcher("password", ExampleMatcher.GenericPropertyMatchers.contains())
// 不区分大小写
.withIgnoreCase()
//忽略字段, 即不管id是什么值都不加入查询条件
.withIgnorePaths("id");
Example<User> example = Example.of(user, exampleMatcher);
System.out.println(userQueryByExampleExecutor.findAll(example));
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
lower(user0_.username) like ? escape ?
or user0_.age=99999
or lower(user0_.password) like ? escape ?
[User(id=1, username=隔壁小王, password=password, age=18)]
通过测试和日志信息发现通过样例的ExampleMatcher.GenericPropertyMatchers.startsWith()走的其实还是完全匹配,并不是起始匹配,后台日志中的SQL参数化查询信息如上所述。
使用案例分析:上面的代码示例中是这样创建实例的:Example.of(userInfo,exampleMatcher);我们看到,Example对象,由 user和matcher共同创建,为讲解方便,我们先来明确一些定义:
- Probe:实体对象,在持久化框架中与Table对应的域对象,一个对象代表数据库表中的一条记录,如上例中User对象。 在构建查询条件时,一个实体对象代表的是查询条件中的字段值部 分。如:要查询姓名为 “ZhangSan”的客户,实体对象只能存储条件值为可忽略大小写的“ZhangSan”。
- ExampleMatcher:匹配器,它是匹配“实体对象”的,表 示了如何使用“实体对象”中的“值”进行查询,它代表的是“查询 方式”,解释了如何去查的问题。
- Example:实例对象,代表的是完整的查询条件,由实体对象(查询条件值)和匹配器(查询方式)共同创建。
官方创建ExampleMatcher例子(Lambda Java8)
ExampleMatcher matcher = ExampleMatcher.matching() .withMatcher("firstname", match -> match.endsWith()) .withMatcher("firstname", match -> match.startsWith()); }
3、ExampleMatcher 源码解读
1、源码解读,另外:ExampleMatcher接口的实现类为TypedExampleMatcher类
public interface ExampleMatcher {
// 实例化ExampleMatcher,必须匹配所有全部的条件, 采⽤默认 and 的查询⽅式
static ExampleMatcher matching() {
return matchingAll();
}
// 实例化ExampleMatcher,匹配任意一个条件即可, 采⽤默认 or 的查询⽅式
static ExampleMatcher matchingAny() {
return new TypedExampleMatcher().withMode(MatchMode.ANY);
}
// 实例化ExampleMatcher,必须匹配所有全部的条件, 采⽤默认 and 的查询⽅式
static ExampleMatcher matchingAll() {
return new TypedExampleMatcher().withMode(MatchMode.ALL);
}
// 忽略属性列表,忽略的属性不参与查询过滤
ExampleMatcher withIgnorePaths(String... ignoredPaths);
// 使用字符串匹配器
ExampleMatcher withStringMatcher(StringMatcher defaultStringMatcher);
// 忽略大小写的匹配器
default ExampleMatcher withIgnoreCase() {
return withIgnoreCase(true);
}
// 传参决定是否忽略大小写
ExampleMatcher withIgnoreCase(boolean defaultIgnoreCase);
// 根据与表字段对应的属性名propertyPath和匹配配置器匹配
default ExampleMatcher withMatcher(String propertyPath, MatcherConfigurer<GenericPropertyMatcher> matcherConfigurer) {
Assert.hasText(propertyPath, "PropertyPath must not be empty!");
Assert.notNull(matcherConfigurer, "MatcherConfigurer must not be empty!");
GenericPropertyMatcher genericPropertyMatcher = new GenericPropertyMatcher();
matcherConfigurer.configureMatcher(genericPropertyMatcher);
return withMatcher(propertyPath, genericPropertyMatcher);
}
// 同上,第二个参数为GenericPropertyMatcher类型(常用)
ExampleMatcher withMatcher(String propertyPath, GenericPropertyMatcher genericPropertyMatcher);
// NULL 值的字段会参与SQL匹配
default ExampleMatcher withIncludeNullValues() {
return withNullHandler(NullHandler.INCLUDE);
}
// NULL 值的字段不会参与SQL匹配
default ExampleMatcher withIgnoreNullValues() {
return withNullHandler(NullHandler.IGNORE);
}
}
2、关键属性分析
(1)ignoredPaths:忽略属性列表,忽略的属性不参与查询过滤。是一个可变参数。
(2)nullHandler:Null值处理方式,枚举类型,有2个可选值:INCLUDE(包括)、IGNORE(忽略)
- 标识作为条件的实体对象中,一个属性值(条件值)为Null时, 表示是否参与过滤。
- 当该选项值是INCLUDE时,表示仍参与过滤,会匹配数据库表中该字段值是Null的记录;
- 若为IGNORE值,表示不参与过滤。
(3)defaultStringMatcher:(StringMatcher 类型)默认字符串匹配方式,枚举类 型,有6个可选值:
- DEFAULT(默认,效果同EXACT)
- EXACT(相等)
- STARTING(开始匹配)
- ENDING(结束匹配)
- CONTAINING(包含,模糊匹配)
- REGEX(正则表达式)
(3)defaultIgnoreCase:默认大小写忽略方式,布尔型,当值为 false 时,即不忽略,大小不相等。
- 该配置对所有字符串属性过滤有效,除非该属性在 propertySpecifiers 中单独定义自己的忽略大小写方式。
(4)propertySpecifiers:各属性特定查询方式,描述了各个属性单独定义的查询方式,每个查询方式中包含4个元素:属性名、字符串匹配方式、大小写忽略方式、属性转换器。
- 如果属性未单独定义查询方式,或单独查询方式中,某个元素未定义(如字符串匹配方式),则采用 ExampleMatcher 中定义的默认值,即上面介绍的 defaultStringMatcher 和 defaultIgnoreCase 的值。
3、StringMatcher 参数详解
| 字符串匹配方式 | 对应JPQL的写法 |
|---|---|
| Default&不忽略大小写 | firstname=?1 |
| Exact&忽略大小写 | LOWER(firstname) = LOWER(?1) |
| Starting&忽略大小写 | LOWER(firstname) like LOWER(?0)+’%’ |
| Ending&不忽略大小写 | firstname like ‘%’+?1 |
| Containing不忽略大小写 | firstname like ‘%’+?1+’%’ |
4、QueryByExampleExecutor 实际场景
使用一组静态或动态约束来查询数据存储、频繁重构域对象,而不用担心破坏现有查询、简单的查询的使用场景,有时候还是挺方便的。
实际使用中我们需要考虑的因素:查询条件的表示,有两部分,一是条件值,二是查询方式。条件值用实体对象(如 Customer 对象)来存储,相对简单,当页面传入过滤条件值时,存入相对应的属性中,没入传入时,属性保持默认值。查询方式是用匹配器 ExampleMatcher 来表示,情况相对复杂些,需要考虑的因素有以下几个:
(1)Null 值的处理:当某个条件值为 Null时,是应当忽略这个过滤条件呢,还是应当去匹配数据库表中该字段值是 Null 的记录?
- Null 值处理方式:默认值是 IGNORE(忽略),即当条件值为 Null 时,则忽略此过滤条件,一般业务也是采用这种方式就可满足。当需要查询数据库表中属性为 Null 的记录时,可将值设为 INCLUDE,这时,对于不需要参与查询的属性,都必须添加到忽略列表(ignoredPaths)中,否则会出现查不到数据的情况。
(2)基本类型的处理:如客户 Customer 对象中的年龄 age 是 int 型的,当页面不传入条件值时,它默认是0,是有值的,那是否参与查询呢?
- 关于基本数据类型处理方式:实体对象中,避免使用基本数据类型,采用包装器类型。如果已经采用了基本类型,而这个属性查询时不需要进行过滤,则把它添加到忽略列表(ignoredPaths)中。
(3)忽略某些属性值:一个实体对象,有许多个属性,是否每个属性都参与过滤?是否可以忽略某些属性?
- ignoredPaths:虽然某些字段里面有值或者设置了其他匹配规则,只要放在 ignoredPaths 中,就会忽略此字段的,不作为过滤条件。
(4)不同的过滤方式:同样是作为 String 值,可能“姓名”希望精确匹配,“地址”希望模糊匹配,如何做到?
- 默认配置和特殊配置混合使用:默认创建匹配器时,字符串采用的是精确匹配、不忽略大小写,可以通过操作方法改变这种默认匹配,以满足大多数查询条件的需要,如将“字符串匹配方式”改为 CONTAINING(包含,模糊匹配),这是比较常用的情况。对于个别属性需要特定的查询方式,可以通过配置“属性特定查询方式”来满足要求,设置 propertySpecifiers 的值即可。
(5)大小写匹配:字符串匹配时,有时可能希望忽略大小写,有时则不忽略,如何做到?
- defaultIgnoreCase:忽略大小的生效与否,是依赖于数据库的。例如 MySQL 数据库中,默认创建表结构时,字段是已经忽略大小写的,所以这个配置与否,都是忽略的。如果业务需要严格区分大小写,可以改变数据库表结构属性来实现。
5、QueryByExampleExecutor 实际案例
(1)无匹配器的情况
要求:查询地址是“河南省郑州市”,且重点关注的客户。
说明:使用默认匹配器就可以满足查询条件,则不需要创建匹配器。
代码示例:
// 创建查询条件数据对象 Customer customer = new Customer(); customer.setAddress("河南省郑州市"); customer.setFocus(true); // 创建实例 Example<Customer> ex = Example.of(customer); // 查询 List<Customer> ls = dao.findAll(ex);
(2)多种条件组合
要求:根据姓名、地址、备注进行模糊查询,忽略大小写,地址要求开始匹配。
说明:这是通用情况,主要演示改变默认字符串匹配方式、改变默认大小写忽略方式、属性特定查询方式配置、忽略属性列表配置。
代码示例:
// 创建查询条件数据对象 Customer customer = new Customer(); customer.setName("zhang"); customer.setAddress("河南省"); customer.setRemark("BB"); // 虽然有值,但是不参与过滤条件 customer.setFocus(true); // 构建对象,创建匹配器,即如何使用查询条件, 这是是全部匹配方式 (and) ExampleMatcher matcher = ExampleMatcher.matching() // 改变默认字符串匹配方式:模糊查询 (属于全局配置) .withStringMatcher(StringMatcher.CONTAINING) // 改变默认大小写忽略方式:忽略大小写 (属于全局配置) .withIgnoreCase(true) // 地址采用“开始匹配”的方式查询 (属于局部配置) .withMatcher("address", GenericPropertyMatchers.startsWith()) // 忽略属性:是否关注。因为是基本类型,需要忽略掉 .withIgnorePaths("focus"); // 创建实例 Example<Customer> ex = Example.of(customer, matcher); // 查询 List<Customer> ls = dao.findAll(ex);(3)多级查询
要求:查询所有潜在客户。
说明:主要演示多层级属性查询。
代码示例
// 创建查询条件数据对象 CustomerType type = new CustomerType(); type.setCode("01"); // 编号01代表潜在客户 Customer customer = new Customer(); customer.setCustomerType(type); // 构建对象,创建匹配器,即如何使用查询条件, 这是是全部匹配方式 (and) ExampleMatcher matcher = ExampleMatcher.matching() // 级联查询,字段 user.email 采⽤字符前缀匹配规则 .withMatcher("customer.code", ExampleMatcher.GenericPropertyMatchers.startsWith()) // 忽略属性:是否关注。因为是基本类型,需要忽略掉 .withIgnorePaths("focus"); // 创建实例 Example<Customer> ex = Example.of(customer, matcher); // 查询 List<Customer> ls = dao.findAll(ex);
(4)查询 Null 值
要求:地址是 Null 的客户。
说明:主要演示改变“Null 值处理方式”。
代码示例
// 创建查询条件数据对象 Customer customer = new Customer(); // 构建对象,创建匹配器,即如何使用查询条件, 这是是全部匹配方式 (and) ExampleMatcher matcher = ExampleMatcher.matching() //构建对象 // 改变“Null值处理方式”:包括null。sql:is null .withIncludeNullValues() // 忽略其他属性 .withIgnorePaths("id", "name", "sex", "age", "focus", "addTime", "remark", "customerType"); // 创建实例 Example<Customer> ex = Example.of(customer, matcher); // 查询 List<Customer> ls = dao.findAll(ex);
虽然工作中用的最多的还是“简单查询”和基于JPA Criteria的动态查询(可以满足所有需求,没有局限性),但QueryByExampleExecutor 还是个非常不错的两种中间场景的查询处理手段,其他人没有用,感觉是对其不熟悉,还是希望我们学习过 QueryByExampleExecutor 的开发者用起来,用熟悉了会增加开发效率。
6、QueryByExampleExecutor 实现源码
(1)我们通过开发工具——Hierarchy,来看一下其接口的实现类有哪些:
QueryByExampleExecutor(org.springframework.data.repository.query)
JpaRepository(org.springframework.data.jpa.repository)
JpaRepositoryImplementation(org.springframework.data.jpa.repository.support)
SimpleJpaRepository(org.springframework.data.jpa.repository.support)
QuerydslJpaRepository(org.springframework.data.jpa.repository.support)
(2)可以发现 JpaSpecificationExecutor 的实现类是 SimpleJpaRepository。
而 SimpleJpaRepository 也实现了 JpaSpecificationExecutor,于是就利用 Specification 的特性,创建了内部类 ExampleSpecification,通过 Exmaple 实现了一套工具类和对 Predicate 的构建,进而实现了整个 ExampleQuery 的逻辑。
如果我们自己去看源码,会发现 QueryByExampleExecutor 给我们提供了两种思路:
- 通过 JpaSpecificationExecutor 自定义 Response 的思路。
- 和对 JpaSpecificationExecutor 的扩展思路(在后面章节自定义 Repository 中会详细介绍)
(3)SimpleJpaRepository 实现类中的关键源码:
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private final EntityManager em;
public <S extends T> Optional<S> findOne(Example<S> example) {
try {
return Optional.of(this.getQuery(new ExampleSpecification(example, this.escapeCharacter), example.getProbeType(), (Sort)Sort.unsorted()).getSingleResult());
} catch (NoResultException var3) {
return Optional.empty();
}
}
protected <S extends T> TypedQuery<S> getQuery(@Nullable Specification<S> spec, Class<S> domainClass, Sort sort) {
CriteriaBuilder builder = this.em.getCriteriaBuilder();
CriteriaQuery<S> query = builder.createQuery(domainClass);
Root<S> root = this.applySpecificationToCriteria(spec, domainClass, query);
query.select(root);
if (sort.isSorted()) {
query.orderBy(QueryUtils.toOrders(sort, root, builder));
}
return this.applyRepositoryMethodMetadata(this.em.createQuery(query));
}
}
(4)读 SimpleJpaRepository 源码给大家的启示
当我们学习一个 API 的时候最好顺带读一下源码,分析一下它的实现结构,这样你会有意外发现:
- 学习源码的编程思想;
- 学习源码的实现方式,我自己如何写,这样可以很快的提高我们自己的编程水平。
7、QueryByExampleExecutor 参考文献 & 鸣谢
- Spring Data JPA 之 QueryByExampleExecutor 的用法和原理分析:https://blog.csdn.net/qq_40161813/article/details/125581497
- Spring Data JPA 从入门到精通~QueryByExampleExecutor的使用:https://blog.csdn.net/listeningsea/article/details/122378964
6、JpaSpecificationExecutor 接口
JpaSpecificationExecutor 接口不能单独使用,需要配合着 JPA 的其他接口一起使用
1、JpaSpecificationExecutor 介绍
JpaSpecificationExecutor是JPA 2.0提供的Criteria API,可 以用于动态生成query。Spring Data JPA支持Criteria查询,可以很方便地使用,足以应付工作中的所有复杂查询的情况了,可以对JPA实现最大限度的扩展。
该接口主要是提供了多条件查询(动态查询),并且可以在查询中添加排序与分页。查看 JpaSpecificationExecutor 接口源码中的方法
/**
* JpaSpecificationExecutor:用来做动态查询的接口
* Specification:是SpringDataJPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件。
* JpaSpecificationExecutor接口下一共就5个接口方法
*/
public interface JpaSpecificationExecutor<T> {
T findOne(Specification<T> spec); // 根据Specificatio条件查询单个结果,查询单个
List<T> findAll(Specification<T> spec); // 根据Specificatio条件查询全部
Page<T> findAll(Specification<T> spec, Pageable pageable); // 根据Specificatio条件查询全部【分页】
List<T> findAll(Specification<T> spec, Sort sort); // 根据Specificatio条件查询全部【排序】
long count(Specification<T> spec); // 根据Specificatio条件统计总数
}
这个接口基本是围绕着Specification接口来定义的, Specification 接口中只定义了如下一个方法,另外Specification是Spring Data JPA对Specification 的聚合操作工具类,里面有以下4个方法(静态和默认方法):
// 需要自定义我们自己的Specification实现类
public interface Specification<T> {
/**
* root:查询的根对象(查询的任何属性都可以从根对象中获取)
* CriteriaQuery:顶层查询对象,自定义查询方式(作为一个了解,一般不用)
* CriteriaBuilder:查询的构造器,封装了很多的查询条件
*/
@Nullable
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb); // 用于封装查询条件
static <T> Specification<T> not(Specification<T> spec) {
return Specifications.negated(spec);
}
static <T> Specification<T> where(Specification<T> spec) {
return Specifications.where(spec);
}
default Specification<T> and(Specification<T> other) {
return Specifications.composed(this, other, CompositionType.AND);
}
default Specification<T> or(Specification<T> other) {
return Specifications.composed(this, other, CompositionType.OR);
}
}
所以可看出,JpaSpecificationExecutor是针对 Criteria API 进行了 predicate 标准封装,帮我们封装了通过 EntityManager 的查询和使用细节,使得操作Criteria更加便利了一些。
缺点:不支持分组和聚合函数,需要使用entityManager自己构建Criteria来查询。SpringDataJPA规范不支持 groupBy。可以查看源码SimpleJpaRepository 将 query.select/multiselect 替换为 query.select(root)。
2、Criteria API 的概念简单介绍
(1)Root<T>root:代表了可以查询和操作的实体对象的根。如 果将实体对象比喻成表名,那root里面就是这张表里面的字段。这不 过是JPQL的实体字段而已。通过里面的Path<Y>get(String attributeName)来获得我们操作的字段。
(2)CriteriaQuery<?>query:代表一个specific的顶层查询对 象,它包含着查询的各个部分,比如:select、from、where、group by、order by等。CriteriaQuery对象只对实体类型或嵌入式类型的 Criteria查询起作用,简单理解,它提供了查询ROOT的方法。常用的方法有:
// 单个查询
CriteriaQuery<T> select(Selection<? extends T> selection);
// 多个查询,等同于联合查询
CriteriaQuery<T> multiselect(Selection... selections);
// where 条件过滤
CriteriaQuery<T> where(Predicate... restrictions);
// 分组查询
CriteriaQuery<T> groupBy(Expression... expressions);
// having过滤
CriteriaQuery<T> having(Predicate... restrictions);
// 排序查询
CriteriaQuery<T> orderBy(Order... o);
// 去重过滤
CriteriaQuery<T> distinct(boolean distinct);
// 获取排序操作对象
List<Order> getOrderList();
// 获取所有参数
Set<ParameterExpression<?>> getParameters();
(3)CriteriaBuilder cb:用来构建CritiaQuery的构建器对 象,其实就相当于条件或者是条件组合,以谓语即Predicate的形式 返回。构建简单的Predicate示例:
Predicate p1 = cb.like(root.get("name").as(String.class),"%"+param.getName()+"%");
Predicate p2 = cb.equal(root.get("uuid").as(Integer.class),param.getUuid());
Predicate p3 = cb.gt(root.get("age").as(Integer.class),param.getAge());
// 构建组合的Predicate示例
Predicate p = cb.and(p3, cb.or(p1, p2));
(4) 实际经验:到此我们发现其实JpaSpecificationExecutor 帮我们提供了一个高级的入口和结构,通过这个入口,可以使用底层 JPA的Criteria的所有方法,其实就可以满足了所有业务场景。但实 际工作中,需要注意的是,如果一旦我们写的实现逻辑太复杂,一般的程序员看不懂的时候,那一定是有问题的,我们要寻找更简单的, 更易懂的,更优雅的方式。比如:
- 分页和排序我们就没有自己再去实现一遍逻辑,直接用其开放的Pageable和Sort即可。
- 当过多地使用group或者having、sum、count等内置的SQL函数 的时候,我们想想就是我们通过Specification实现了逻辑, 这种效率真的高吗?是不是数据的其他算法更好?
- 当我们过多地操作left join和inner Join链表查询的时候, 我们想想,是不是通过数据库的视图(view)更优雅一点?
3、JpaSpecificationExecutor 示例
1、初始化数据
1、创建Repository层接口,除了继承JpaSpecificationExecutor,还需要继承 JPA 其他接口
/**
* JpaSpecificationExecutor 接口
* 该接口主要是提供了多条件查询的支持,并且可以在查询中添加排序与分页。
* 注意:JpaSpecificationExecutor不能单独使用,需要配合着jpa中的其他接口一起使用
*/
public interface UserJpaSpecificationExecutor extends JpaRepository<User,Long>, JpaSpecificationExecutor<User> {
}
2、下面测试类实战操作,先准备测试数据
@Autowired
private UserJpaRepository userJpaRepository;
@BeforeEach
public void initData(){
// 保存多条数据
User userA = new User();
userA.setUsername("隔壁小王");
userA.setPassword("password");
userA.setAge(18);
User userB = new User();
userB.setUsername("赵小丽");
userB.setPassword("666666");
userB.setAge(21);
User userC = new User();
userC.setUsername("王小虎");
userC.setPassword("123456");
userC.setAge(25);
this.userJpaRepository.saveAll(Arrays.asList(userA, userB, userC)).forEach(System.out::println);
}
2、单条件查询
/**
* 条件查询——单条件
* Predicate 过滤条件
* jpql:from User where username = '隔壁小王'
* sql:select * from sys_user where username = '隔壁小王'
*/
@Test
public void test1() {
Specification<User> spec = new Specification<User>() {
/**
* @param root 根对象。封装了查询条件的对象
* @param query 定义了一个基本的查询。一般使用较少
* @param cb 创建一个查询条件
* @return Predicate:定义了查询条件
*/
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Path<Object> username = root.get("username");
Predicate predicate = cb.equal(username, "隔壁小王");
return predicate;
}
};
List<User> userList = userJpaSpecificationExecutor.findAll(spec);
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.username=?
User(id=1, username=隔壁小王, password=password, age=18)
3、多条件查询
1、多条件查询一(推荐此方式,支持动态条件查询),SQL全部是and拼接
/**
* 多条件查询一(推荐此方式,支持动态条件查询)
* jpql:from User where username = '隔壁小王' and password = 'password' and age < 30
* sql:select * from sys_user where username = '隔壁小王' and password = 'password' and age < 30
*/
@Test
public void test2(){
Specification<User> spec = (root, query, cb) -> {
String username = "隔壁小王";
String password = "password";
List<Predicate> predicates = new ArrayList<>();
if (!ObjectUtils.isEmpty(username)) {
predicates.add(cb.equal(root.get("username"), username));
}
if (!ObjectUtils.isEmpty(password)) {
predicates.add(cb.equal(root.get("password"), password));
}
// 或者 cb.and(toArray);
Predicate[] toArray = predicates.toArray(new Predicate[0]);
return query.where(toArray).getRestriction();
};
List<User> userList = userJpaSpecificationExecutor.findAll(spec);
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
user0_.username=?
and user0_.password=?
and user0_.age<30
User(id=1, username=隔壁小王, password=password, age=18)
多条件查询二:
/**
* 多条件查询二: 使用过滤条件or
*/
@Test
public void test3() {
List<User> userList = userJpaSpecificationExecutor.findAll((root, query, cb) -> {
Predicate age1 = cb.greaterThan(root.get("age"), 16);
Predicate age2 = cb.lessThan(root.get("age"), 22);
Predicate orPredicate1 = cb.or(age1, age2); // 使用or连接两个条件
Predicate username1 = cb.equal(root.get("username"), "隔壁小王");
Predicate username2 = cb.equal(root.get("username"), "王小虎");
Predicate orPredicate2 = cb.or(username1, username2); // 使用or连接两个条件
Predicate andPredicate = cb.and(orPredicate1, orPredicate2);
return query.where(andPredicate).getRestriction();
});
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
(user0_.age>16 or user0_.age<22)
and (user0_.username=? or user0_.username=?)
User(id=1, username=隔壁小王, password=password, age=18)
User(id=3, username=王小虎, password=123456, age=25)
4、模糊查询
/**
* 模糊查询
* jpql:from User where username like '%小王' and password like 'pass%' and age < 30
* sql:select * from sys_user where username like '%小王' and password like 'pass%' and age < 30
*/
@Test
public void test4(){
Specification<User> spec = (root, query, cb) -> {
Predicate username = cb.like(root.get("username"), "%小王");
Predicate password = cb.like(root.get("password"), "pass%");
Predicate age = cb.lt(root.get("age"), 30);
Predicate predicate = cb.and(username, password);
predicate = cb.and(predicate, age);
return predicate;
};
List<User> userList = userJpaSpecificationExecutor.findAll(spec);
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
(
user0_.username like ?
)
and (
user0_.password like ?
)
and user0_.age<30
User(id=1, username=隔壁小王, password=password, age=18)
5、字段子查询
/**
* in子查询
* jpql:from User where username in ("隔壁小王", "王小虎") or username = "赵小丽"
* sql:select * from sys_user where username in ("隔壁小王", "王小虎") or username = "赵小丽"
*/
@Test
public void testIn(){
List<User> userList = userJpaSpecificationExecutor.findAll((root, query, cb) -> {
CriteriaBuilder.In<Object> in = cb.in(root.get("username")).value(Arrays.asList("隔壁小王", "王小虎"));
Predicate username = cb.equal(root.get("username"), "赵小丽");
return cb.or(in, username);
});
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
user0_.username in (
? , ?
)
or user0_.username=?
User(id=1, username=隔壁小王, password=password, age=18)
User(id=2, username=赵小丽, password=666666, age=21)
User(id=3, username=王小虎, password=123456, age=25)
6、对象子查询
1、子条件或者子语句查询案例1
@Test
public void testSubSpecification1() {
List<User> userList = userJpaSpecificationExecutor.findAll((root, query, cb) -> {
// 1.获取子查询对象
Subquery<User> subQuery = query.subquery(User.class);
Root<User> subRoot = subQuery.from(User.class);
// 2.通过子查询对象, 映射投影字段(注意:只有子查询中可以用成功投影查询)
subQuery = subQuery.select(subRoot.get("username"));
// 3.设置子查询的查询条件
subQuery.where(cb.equal(subRoot.get("username"), "隔壁小王"));
// 4.将父查询条件和子查询合并, root.get("username")这一定不能填错字段
Predicate parentAndSubConjunctPredicate = root.get("username").in(subQuery);
return query.where(parentAndSubConjunctPredicate).getRestriction();
});
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
user0_.username in (
select
user1_.username
from
sys_user user1_
where
user1_.username=?
)
User(id=1, username=隔壁小王, password=password, age=18)
2、子条件或者子语句查询案例2
@Test
public void testSubSpecification2() {
List<User> userList = userJpaSpecificationExecutor.findAll((root, query, cb) -> {
// 1.父查询条件
Predicate parentPredicate = cb.le(root.get("age"), 30);
// 2.子查询
Subquery<User> subQuery = query.subquery(User.class);
Root<User> subRoot = subQuery.from(User.class);
// 这是子查询语句中只查询一个id字段, 这样做是为了后面可以在in内存在一个field
subQuery = subQuery.select(subRoot.get("id"));
// 3.子查询中的条件, 子查询的cb和父查询的cb相同
Predicate subPredicate1 = cb.equal(subRoot.get("username"), "隔壁小王");
Predicate subPredicate2 = cb.equal(subRoot.get("age"), 18);
subQuery.where(cb.and(subPredicate1, subPredicate2));
// 3.将父查询条件和子查询合并, root.get("id")这一定不能填错字段
Predicate parentAndSubConjunctPredicate = root.get("id").in(subQuery);
return query.where(parentPredicate, parentAndSubConjunctPredicate).getRestriction();
});
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
user0_.age<=30
and (
user0_.id in (
select
user1_.id
from
sys_user user1_
where
user1_.username=?
and user1_.age=18
)
)
User(id=1, username=隔壁小王, password=password, age=18)
7、常用查询条件汇总
| 方法名称 | 对应SQL |
|---|---|
| equle | filed = value |
| notEqule | filed != value |
| gt(greaterThan ) | filed > value |
| lt(lessThan ) | filed < value |
| ge(greaterThanOrEqualTo ) | filed >= value |
| le( lessThanOrEqualTo) | filed <= value |
| between | filed between value and value |
| isNotNull | filed is not null |
| isNull | filed is null |
| like | filed like value |
| notLike | filed not like value |
@Test
public void testAll(){
List<User> userList = userJpaSpecificationExecutor.findAll((root, query, cb) -> {
// 等于
Predicate predicate1 = cb.equal(root.get("username"), "小王");
// 不等于
Predicate predicate2 = cb.notEqual(root.get("password"), "123456");
// 大于
Predicate predicate3 = cb.greaterThan(root.get("age"), 1);
// 大于等于
Predicate predicate4 = cb.greaterThanOrEqualTo(root.get("age"), 1);
// 小于
Predicate predicate5 = cb.lessThan(root.get("age"), 2);
// 小于等于
Predicate predicate6 = cb.lessThanOrEqualTo(root.get("age"), 2);
// between, 根据时间区间查询
// Predicate predicate7 = cb.between(root.get("date"), new Date(), new Date());
Predicate predicate7 = cb.between(root.get("age"), 18, 25);
// 非空
Predicate predicate8 = cb.isNotNull(root.get("id"));
// 为空
Predicate predicate9 = cb.isNull(root.get("password"));
// 模糊查询
Predicate predicate10 = cb.like(root.get("username"), "王%");
// 模糊查询取反
Predicate predicate11 = cb.notLike(root.get("username"), "王%");
// in
Predicate predicate12 = root.get("age").in(18, 20);
// 连接Predicate
Predicate[] predicateArray = {predicate1, predicate2, predicate3, predicate4, predicate5,
predicate6, predicate7, predicate8, predicate9, predicate10, predicate11, predicate12};
return query.where(predicateArray).getRestriction();
});
userList.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_2_,
user0_.age as age2_2_,
user0_.password as password3_2_,
user0_.username as username4_2_
from
sys_user user0_
where
user0_.username=?
and user0_.password<>?
and user0_.age>1
and user0_.age>=1
and user0_.age<2
and user0_.age<=2
and (user0_.age between 18 and 25)
and (user0_.id is not null)
and (user0_.password is null)
and (user0_.username like ?)
and (user0_.username not like ?)
and (user0_.age in (18 , 20))
8、分页查询
/**
* 分页操作
*/
@Test
public void testPageable(){
Specification<User> spec = (root, criteriaQuery, criteriaBuilder) -> {
Predicate username = criteriaBuilder.equal(root.get("username"), "隔壁小王");
Predicate password = criteriaBuilder.equal(root.get("password"), "password");
return criteriaBuilder.and(username, password);
};
// 分页对象
Pageable pageable = PageRequest.of(0, 2);
Page<User> page = this.userJpaSpecificationExecutor.findAll(spec, pageable);
System.out.println("总记录数: " + page.getTotalElements());
System.out.println("当前第几页: " + (page.getNumber() + 1));
System.out.println("总页数: " + page.getTotalPages());
System.out.println("当前页面的 List: " + page.getContent());
System.out.println("当前页面的记录数: " + page.getNumberOfElements());
page.getContent().forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.username=?
and user0_.password=? limit ?
总记录数: 1
当前第几页: 1
总页数: 1
当前页面的 List: [User(id=1, username=隔壁小王, password=password, age=18)]
当前页面的记录数: 1
User(id=1, username=隔壁小王, password=password, age=18)
9、排序查询
/**
* 排序操作
*/
@Test
public void testSort(){
Specification<User> spec = (root, criteriaQuery, criteriaBuilder) -> {
Predicate username = criteriaBuilder.equal(root.get("username"), "隔壁小王");
Predicate password = criteriaBuilder.equal(root.get("password"), "password");
query.where(cb.and(username, password));
// 排序方1, 如果内部排序与外部排序同时是哦那个只有外部排序生效
// query.orderBy(cb.desc(root.get("age")));
return query.getRestriction();
};
// 排序对象
Sort sort = Sort.by(Sort.Direction.DESC,"id");
List<User> users = this.userJpaSpecificationExecutor.findAll(spec, sort);
users.forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.username=?
and user0_.password=?
order by
user0_.id desc
User(id=1, username=隔壁小王, password=password, age=18)
10、分页和排序查询
/**
* 分页+排序 操作
*/
@Test
public void testPageableAndSort(){
Specification<User> spec = (root, criteriaQuery, criteriaBuilder) -> {
Predicate username = criteriaBuilder.equal(root.get("username"), "隔壁小王");
Predicate password = criteriaBuilder.equal(root.get("password"), "password");
return criteriaBuilder.and(username, password);
};
// 排序
Sort sort = Sort.by(Sort.Direction.DESC,"id");
// 分页
Pageable pageable = PageRequest.of(0, 2, sort);
Page<User> page = this.userJpaSpecificationExecutor.findAll(spec, pageable);
System.out.println("总记录数: " + page.getTotalElements());
System.out.println("当前第几页: " + (page.getNumber() + 1));
System.out.println("总页数: " + page.getTotalPages());
System.out.println("当前页面的 List: " + page.getContent());
System.out.println("当前页面的记录数: " + page.getNumberOfElements());
page.getContent().forEach(System.out::println);
}
Hibernate:
select
user0_.id as id1_1_,
user0_.age as age2_1_,
user0_.password as password3_1_,
user0_.username as username4_1_
from
sys_user user0_
where
user0_.username=?
and user0_.password=?
order by
user0_.id desc limit ?
总记录数: 1
当前第几页: 1
总页数: 1
当前页面的 List: [User(id=1, username=隔壁小王, password=password, age=18)]
当前页面的记录数: 1
User(id=1, username=隔壁小王, password=password, age=18)
11、投影和分组查询
虽然JpaSpecificationExecutor无法实现select后面属性的选择和groupBy的构建,不过可以直接使用JPA原生的Criteria方式来完成。
注意:这里关键是要@PersistenceContext注入EntityManager对象
1、投影查询
@PersistenceContext
private EntityManager entityManager;
/**
* 投影查询 — criteriaBuilder.createTupleQuery()
* sql:select username, age from sys_user
*
* 注意:使用:返回元组(Tuple)的查询
*/
@Test
public void testFindAllMultiSelect() {
// 1.CriteriaBuilder 安全查询创建工厂
CriteriaBuilder criteriaBuilder = entityManager.getCriteriaBuilder();
// 2.CriteriaQuery 安全查询主语句
CriteriaQuery<Tuple> criteriaQuery = criteriaBuilder.createTupleQuery();
// 3.Root 定义查询的From子句中能出现的类型
Root<User> from = criteriaQuery.from(User.class);
// 需要给字段取别名,否则无法通过tuple.get(field)获取数据
criteriaQuery.multiselect(from.get("username").alias("username"), from.get("age").alias("age"));
TypedQuery<Tuple> query = entityManager.createQuery(criteriaQuery);
List<Tuple> tuples = query.getResultList();
// 输出tuples对象的值, 有2种方式获取
// 或者: name = list.get(0).get(0); age = list.get(0).get(1)
tuples.forEach(x-> System.out.println(x.get("username")+"、"+x.get("age")));
// 一般会转换成我们想要的类, 例如User
List<User> users = tuples.stream().map(tuple -> {
User user = new User();
user.setUsername((String) tuple.get("username"));
user.setAge((Integer) tuple.get("age"));
return user;
}).collect(Collectors.toList());
System.out.println(users);
}
Hibernate:
select
user0_.username as col_0_0_,
user0_.age as col_1_0_
from
sys_user user0_
隔壁小王、18
赵小丽、21
王小虎、25
[User(id=null, username=隔壁小王, password=null, age=18), User(id=null, username=赵小丽, password=null, age=21), User(id=null, username=王小虎, password=null, age=25)]
2、分组查询
/**
* 分组查询
* sql:select username,count(username),max(age),min(age),sum(age),avg(age) from sys_user group by username
*/
@Test
public void testFindGroupBy() {
CriteriaBuilder criteriaBuilder = entityManager.getCriteriaBuilder();
CriteriaQuery<Tuple> criteriaQuery = criteriaBuilder.createTupleQuery();
Root<User> from = criteriaQuery.from(User.class);
// .alias("name") 取别名
criteriaQuery.multiselect(
from.get("username").alias("username"),
criteriaBuilder.count(from.get("username")).alias("count"),
criteriaBuilder.max(from.get("age")).alias("max"),
criteriaBuilder.min(from.get("age")).alias("min"),
criteriaBuilder.sum(from.get("age")).alias("sum"),
criteriaBuilder.avg(from.get("age")).alias("avg"));
criteriaQuery.groupBy(from.get("username"));
// criteriaQuery.having(criteriaBuilder.disjunction());
List<Tuple> tuples = entityManager.createQuery(criteriaQuery).getResultList();
tuples.forEach(x-> System.out.println(x.get("username") + "、" +
x.get("count") + "、" +
x.get("max") + "、" +
x.get("min") + "、" +
x.get("sum") + "、" +
x.get("avg"))
);
// TODO: 如果有需要自己可以再次转换成业务类
}
Hibernate:
select
user0_.username as col_0_0_,
count(user0_.username) as col_1_0_,
max(user0_.age) as col_2_0_,
min(user0_.age) as col_3_0_,
sum(user0_.age) as col_4_0_,
avg(user0_.age) as col_5_0_
from
sys_user user0_
group by
user0_.username
隔壁小王、1、18、18、18、18.0
赵小丽、1、21、21、21、21.0
王小虎、1、25、25、25、25.0
所以如果想投影查询和分组查询的话还得使用原生的Criteria方式来查询。
一般的复杂或者连表复杂查询使用CriteriaBuilder、CriteriaQuery、Root 来完成查询。如果不需要构建Selection、groupBy时,也可以只构建Predicate,然后使用JPA的findAll()方法即可。
12、多表关联查询(双向一对多)
1、实体类配置与测试代码如下:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "user")
public class User implements Serializable { // 用户类(主表)
@Id
@Column(name = "user_id")
private Long userId;
@Column(name = "username")
private String username;
@OneToMany(mappedBy = "user")
private List<UserInfo> userInfos;
}
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@ToString(exclude = "user")
@Entity
@Table(name = "user_info")
public class UserInfo implements Serializable { // 用户信息类(从表)
@Id
@Column(name = "user_info_id")
private Long userInfoId;
@Column(name = "country")
private String country;
@ManyToOne
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 初始化数据:非级联添加: 先保存user, 并且设置user到userInfo中, 然后再保存userInfo
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 从类方级联新增
User user1 = new User(1L, "DEV", null);
User user2 = new User(2L, "UAT", null);
userRepository.saveAllAndFlush(Arrays.asList(user1, user2));
UserInfo userInfo1 = new UserInfo(1L, "CN", user1);
UserInfo userInfo2 = new UserInfo(2L, "EN", user1);
UserInfo userInfo3 = new UserInfo(3L, "UK", user2);
UserInfo userInfo4 = new UserInfo(4L, "DE", user2);
userInfoRepository.saveAllAndFlush(Arrays.asList(userInfo1, userInfo2, userInfo3, userInfo4));
}
/**
* 多表多条件动态查询: Join代表链接查询,通过root对象获取
* 创建的过程中,第一个参数为关联对象的属性名称,第二个参数为连接查询的方式(left,inner,right)
* JoinType.LEFT : 左外连接,JoinType.INNER:内连接,JoinType.RIGHT:右外连接
* 使用多表关联后,Join 就相当有了 root 的功能,可以join.get("对象属性名称")
* 注意!注意!注意:
* Root:代表的是User表,所以通过root.get()只能获取Many表的属性或字段.
* Join:代表的是UserInfo表,虽然是关联查询,但它只代表关联的UserInfo表,只能获取UserInfo的属性
* 如果root/join获取自己表以外的属性或字段会报如下错:
* Unable to locate Attribute with the the given name [categoryType] on this ManagedType[XXX]
* 如果有第三张表关联使用join.join()往下传递即可。
*/
@Test
@Order(2)
@Transactional // 解决在java代码中的no Session问题
void findJoinTable() {
String username = "DEV";
String country = "CN";
userRepository.findAll((root, query, cb) -> {
/**
* Join代表链接查询,通过root对象获取
* 创建过程中:
* 第一个参数为关联对象的属性名称,
* 第二个参数为连接查询的方式 (JoinType.LEFT,JoinType.INNER,JoinType.RIGHT)
*/
Join<User, UserInfo> join = root.join("userInfos", JoinType.LEFT);
// 用列表装载断言对象
List<Predicate> predicates = new ArrayList<>();
// Path<Object> 由于Path没有指定类型,这里指定了.as(String.class)
if (!ObjectUtils.isEmpty(username)) {
predicates.add(cb.equal(root.get("username").as(String.class), username));
}
if (!ObjectUtils.isEmpty(country)) {
predicates.add(cb.equal(join.get("country").as(String.class), country));
}
Predicate[] toArray = predicates.toArray(new Predicate[0]);
return query.where(toArray).getRestriction();
})/*.forEach(System.out::println)*/;
}
}
2、查看日志:
cascadeSave()
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)findJoinTable()
Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ left outer join user_info userinfos1_ on user0_.user_id=userinfos1_.user_id where user0_.username=? and userinfos1_.country=?
注意(重点):
1、可以发现 Specification 重写方法里面的 root,criteriaQuery 和 builder 都已经被 JPA 赋值好了,我们只需要关注Predicate 的构建,也就是说在调用 JpaSpecificationExecutor 接口内的 findXxx() 方法只能完成 where 条件的构建,而不能实现 select 后面属性的选择和 groupBy 的构建。
2、不管是Hibernate还是JPA,表之间的连接查询,被映射为实体类之间的关联关系,这样,如果两个实体类之间没有(实现)关联关系,你就不能把两个实体(或者表)Join起来查询。这是很恼火的事情,因为我们很多时候并不需要显式定义两个实体类之间的关联关系就可以实现业务逻辑,如果使用JPQL,只是为了Join我们就必须在两个实体类之间添加代码,而且还不能逆向工程,如果表里面没有定义外键约束的话,逆向工程会把我们添加的关联代码抹掉。
3、如果真有特别复杂的 SQL 无法使用 Specification 及以上其他方式解决,可以使用 jdbcTemplate 自写SQL查询解决。
4、Specification 自定义扩展方法
我们在实际工作中会发现,如果按上面的逻辑,简单重复,总感觉是不是可以抽出一些公用方法呢,此时我们引入一种工厂模式,帮我们做一些事情。基于JpaSpecificationExecutor的思路,我们创建一个SpecificationFactory.Java,内容如下:
public final class SpecificationFactory {
// 模糊查询,匹配对应字段
public static Specification containsLike(String attribute, String value) {
return (root, query, cb) -> cb.like(root.get(attribute), "%" + value + "%");
}
// 获取某字段等于value的查询条件
public static Specification equal(String attribute, Object value) {
return (root, query, cb) -> cb.equal(root.get(attribute), value);
}
// 插叙某字段在一个区间的范围
public static Specification isBetween(String attribute, int min, int max) {
return (root, query, cb) -> cb.between(root.get(attribute), min, max);
}
public static Specification isBetween(String attribute, double min, double max) {
return (root, query, cb) -> cb.between(root.get(attribute), min, max);
}
public static Specification isBetween(String attribute, Date min, Date max) {
return (root, query, cb) -> cb.between(root.get(attribute), min, max);
}
// 通过属性名和集合实现In查询
public static Specification in(String attribute, Collection c) {
return (root, query, cb) -> root.get(attribute).in(c);
}
public static Specification greaterThan(String attribute, BigDecimal value) {
return (root, query, cb) -> cb.greaterThan(root.get(attribute), value);
}
public static Specification greaterThan(String attribute, Long value) {
return (root, query, cb) -> cb.greaterThan(root.get(attribute), value);
}
}
1、配合Specification使用,调用示例1:
@Override
public List<UserInfo> findAllByContainsLike(String attribute, String value) {
return simpleJpaRepository.findAll(SpecificationFactory.containsLike(attribute,value));
}
2、配合Specification使用,调用示例2:
@Override
public List<UserInfo> findAllByContainsLikeAndBetween(String attribute, String value, Date min, Date max) {
return simpleJpaRepository.findAll(SpecificationFactory.containsLike(attribute,value)
.and(SpecificationFactory.isBetween("createdTime",min,max)));
}
5、JpaSpecificationExecutor 参考文献 & 鸣谢
JPA之Criteria查询:第一种:通过JPA的Criteria API实现。第二种:实现实现 JpaSpecificationExecutor 接口
- SpringBoot之路(四)Spring-Data-Jpa中的高级应用:https://mp.weixin.qq.com/s/gnWkFH8kvYDMzyMe7CqX0w
- 博客园(My Sunshine)JPA 使用 Specification 复杂查询和 Criteria 查询:https://blog.wuwii.com/jpa-specification.html
- 博客园,JPA Criteria 查询:类型安全与面向对象:https://www.cnblogs.com/JAYIT/p/6972144.html
- CSDN(天涯泪小武)JPA 复杂条件查询Group By等等:https://tianyalei.blog.csdn.net/article/details/90704969
- CNDN(流烟默)JpaSpecificationExecutor复杂动态查询实例:https://blog.csdn.net/J080624/article/details/84581231
- SpringDataJPA 动态查询 Specification 自定义工具类:https://blog.csdn.net/qq_32786139/article/details/86473544
- SpringDataJPA Specification 子查询实现:https://blog.csdn.net/xuyp95/article/details/91909036
- 使用JPA Specification EntityManager 多条件 复杂动态查询 子查询 组合 and or 分组 分页 排序 案例:https://blog.csdn.net/weixin_41347419/article/details/105098113
7、Repository 自定义接口
有时JPA接口提供的方法并不满足我们的需求,这时我们可以自定义Repository来扩展。主要通过@PersistenceContext 获取 EntityManager 对象来实现
1、定义一个普通接口
/**
* 自定义Repository接口
*/
public interface UserCustomRepository {
User findUserById(Long id);
}
2、创建接口实现类(使用 @PersistenceContext 注入 EntityManager 对象)
public class UserCustomRepositoryImpl implements UserCustomRepository {
// 解决线程安全问题,如果使用@autowire来对EntityManager进行注入,那可能会出现线程安全问题,
// 使用注解PersistenceContext可以为每一个线程单独绑定一个EntityManager,这样就可以解决线程不安全的问题了
@PersistenceContext
private EntityManager entityManager;
@Override
public User findUserById(Long id) {
return entityManager.find(User.class,id);
}
}
3、使用接口
/**
* 用户自定义Repository接口讲解
*/
public interface UserDao extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User>, UserCustomRepository{
}
4、测试代码
@SpringBootTest
public class UserCustomRepositoryTests {
@Autowired
private UserDao userDao;
@Test
public void testFind(){
System.out.println(userDao.findUserById(6L));
}
}
5、查看日志
Hibernate:
select
user0_.id as id1_0_0_,
user0_.age as age2_0_0_,
user0_.password as password3_0_0_,
user0_.username as username4_0_0_
from
sys_user user0_
where
user0_.id=?
User(id=2, username=王小虎, password=123456, age=25)
SpringData JPA 数据表映射(简版)
1、映射注解说明
1.配置多表联系注解介绍
@OneToOne 一对一映射
targetEntityClass: 表示该属性关联的实体类型(对方类.class),该属性通常可不指定,ORM根据属性类型自动判断
cascade: 级联操作
CascadeType.MERGE 级联更新
CascadeType.PERSIST 级联保存
CascadeType.REFRESH 级联刷新
CascadeType.REMOVE 级联删除
CascadeType.DETACH 级联脱管
CascadeType.ALL 级联上述5种操作
fetch: 抓取策略(多表连接查询)
FetchType.LAZY: 延迟加载 (延迟加载)(默认)
FetchType.EAGER: 迫切查询 (⽴即加载)
mappedBy: 放弃外键维护 (常用)
orphanRemoval: 是否使用孤儿删除
optional: 关联是否可选, 默认是可选的(也就是可以为空).如设置为false, 则必须始终存在非空关系
@OneToMany 一对多映射
targetEntityClass: 指定多方类的字节码,该属性通常可不指定,ORM根据属性类型自动判断
cascade: 指定要使用的级联操作
fetch: 指定是否采用延迟加载
mappedBy: 指定`从表`实体类中引用`主表`对象的名称
orphanRemoval: 是否使用孤儿删除
@ManyToOne 多对一映射
targetEntityClass: 指定一方实体类字节码,该属性通常可不指定,ORM根据属性类型自动判断
cascade: 指定要使用的级联操作
fetch: 指定是否采用延迟加载
optional: 关联是否可选, 默认是可选的(也就是可以为空).如设置为false,则必须始终存在非空关系
@ManyToMany(多对多)
targetEntityClass: 指定另一方类的字节码
cascade: 配置级联操作
fetch: 配置延迟加载和立即加载
mappedBy: 放弃外键维护
2:配置外键关系的注解
@JoinColumn 用于定义主键字段和外键字段的对应关系。
name: 【己方】实体的【数据库字段】,指定(当前类)外键字段的名称
referencedColumnName: 【对方】实体的【数据库字段】(如果是主键,可以省略),指定引用主表的主键字段名称
unique: 是否唯一。默认值不唯一
nullable: 是否允许为空。默认值允许
insertable: 是否允许插入。默认值允许
updatable: 是否允许更新。默认值允许
columnDefinition: 列的定义信息
table 包含该列的表的名称 (可选)
foreignKey 外键策略, JPA2.1新增, 三种模式: 创建外键约束, 不创建外键约束, 采⽤默认⾏为
@JoinTable 针对中间表的设置
name: 配置中间表的名称
joinColumns: 中间表的外键字段关联当前实体类所对应表的主键字段
@JoinColumn:
name: 本类的外键
referencedColumnName: 本类与外键(表)对应的主键
inverseJoinColumn: 中间表的外键字段关联对方表的主键字段
@JoinColumn:
name: 对方类的外键
referencedColumnName: 对方类与外键(表)对应的主键
3:首先确定多表之间的关系:
一对一和一对多:
一的一方称为主表,而多的一方称为从表,外键就要建立在从表上,它们的取值的来源主要来自主键
多对多:
这个时候需要建立一个中间表,中间表中最少由2个字段组成,这2个字段作为外键指向2张表的主键又组成了联合主键
4、mappedBy 属性
mappedBy: 是OneToOne、OneToMany和ManyToMany这三种关联关系的属性。
用来标注拥有这种关系的字段。 除非关系是单向的,否则是必需的。
那么什么叫拥有关联关系呢,假设是双向一对一的话,那么拥有关系的这一方有建立、解除和更新与另一方关系的能力。而另一方没有,只能被动管理。
由于JoinTable和JoinColumn一般定义在拥有关系的这一端,而mappedBy一定是定义在关系的被拥有方(the owned side),也就是跟定义JoinTable和JoinColumn互斥的一方,它的值指向拥有方中关于被拥有方的字段,可能是一个对象(OneToMany),也可能是一个对象集合(ManyToMany)
关系映射中mappedBy的全面理解
mappedBy 单向关系不需要设置该属性,双向关系必须设置,避免双方都建立外键字段数据库中1对多的关系,关联关系总是被多方维护的即外键建在多方,我们在单方对象的@OneToMany(mappedby=””)把关系的维护交给多方对象的属性去维护关系。
对于mappedBy属性的总结:
- 只有OneToOne、OneToMany、ManyToMan 才有mappedBy属性,ManyToOne 不存在该属性;
- mappedBy标签一定是定义在the owned side(被拥有方的),他指向theowning side(拥有方);
- 关系的拥有方负责关系的维护,在拥有方建立外键。所以用到@JoinColumn
- mappedBy跟JoinColumn/JoinTable总是处于互斥的一方
这里的维护关联关系,拿多对多来说就是中间表,在不设置cascade的情况下,中间表由负责维护关联关系的一方维护。
2、一对一关系映射
2.1、准备一对一
1、表结构和需求
-- 需求:学生表与学生信息表的一对一的关联关系
-- 学生表(主键表):一方
-- 学生信息表(外键表):一方
-- 学生表结构
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| student_id | bigint(20) | NO | PRI | NULL | auto_increment |
| student_name | varchar(255) | YES | | NULL | |
| student_pwd | varchar(255) | YES | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
-- 学生信息表结构
+----------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------------+--------------+------+-----+---------+----------------+
| information_id | bigint(20) | NO | PRI | NULL | auto_increment |
| student_age | int(11) | YES | | NULL | |
| student_number | varchar(255) | YES | | NULL | |
| student_id | bigint(20) | YES | MUL | NULL | |
+----------------+--------------+------+-----+---------+----------------+
2、创建2个实体类对应的DAO接口
/**
* 学生表repository接口
*/
public interface StudentRepository extends JpaRepository<Student,Long> {
}
/**
* 学生信息表repository接口
*/
public interface StudentInformationRepository extends JpaRepository<StudentInformation,Long> {
}
2.2、单向一对一
1、创建:学生信息实体类(拥有方,外键表)
@Data
@Entity
@Table(name = "tb_student_information")
public class StudentInformation implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "information_id")
private Long informationId;
@Column(name = "student_number")
private String studentNumber;
@Column(name = "student_age")
private Integer studentAge;
// 单向的话配置可以只配置拥有方(外键方)
@OneToOne
@JoinColumn(name = "student_id")
private Student student;
}
2、创建:学生实体类(被拥有方,主键表)
@Data
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "student_id")
private Long studentId;
@Column(name = "student_name")
private String studentName;
@Column(name = "student_pwd")
private String studentPwd;
}
3、测试代码:
@SpringBootTest
public class AssociationTableTests {
@Autowired
StudentRepository studentRepository;
@Autowired
StudentInformationRepository informationRepository;
/**
* 单向一对一
*/
@Test
public void testOneToOneSave(){
// 首先给学生表(主键表)增加一条数据
Student student = new Student();
student.setStudentName("小明");
student.setStudentPwd("123456");
studentRepository.saveAndFlush(student);
// 然后再给学生信息表(外键表)增加一条数据
StudentInformation information = new StudentInformation();
information.setStudentNumber("001");
information.setStudentAge(13);
// 设置这个字段相当于给外键设置值,如果没有设置那么保存后外键字段将为null
information.setStudent(student);
informationRepository.saveAndFlush(information);
// 查询信息
System.out.println(teacherRepository.findById(student.getStudentId()));
System.out.println(informationRepository.findById(information.getInformationId()));
}
}
查看日志:
Hibernate:
insert
into
tb_student
(student_name, student_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_student_information
(student_id, student_age, student_number)
values
(?, ?, ?)
Hibernate:
select
teacher0_.teacher_id as teacher_1_5_0_,
teacher0_.teacher_name as teacher_2_5_0_,
teacher0_.teacher_pwd as teacher_3_5_0_
from
tb_teacher teacher0_
where
teacher0_.teacher_id=?
Optional.empty
Hibernate:
select
studentinf0_.information_id as informat1_3_0_,
studentinf0_.student_id as student_4_3_0_,
studentinf0_.student_age as student_2_3_0_,
studentinf0_.student_number as student_3_3_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_information studentinf0_
left outer join
tb_student student1_
on studentinf0_.student_id=student1_.student_id
where
studentinf0_.information_id=?
Optional[StudentInformation(informationId=8, studentNumber=001, studentAge=13, student=Student(studentId=8, studentName=小明, studentPwd=123456))]
2.3、双向一对一
1、学生信息实体类(拥有方,外键表)不变
@Data
@Entity
@Table(name = "tb_student_information")
public class StudentInformation implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "information_id")
private Long informationId;
@Column(name = "student_number")
private String studentNumber;
@Column(name = "student_age")
private Integer studentAge;
// 单向的话配置可以只配置拥有方(外键方)
@OneToOne
@JoinColumn(name = "student_id")
private Student student;
}
2、学生实体类(主键表)需要增加属性与注解
@Data
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "student_id")
private Long studentId;
@Column(name = "student_name")
private String studentName;
@Column(name = "student_pwd")
private String studentPwd;
// 上面的属性与单向一对一是一样的,就增加了如下信息
/**
* mappedBy:放弃维护外键,值为另一方引用本类的属性名
*/
@OneToOne(mappedBy = "student")
private StudentInformation studentInformation;
}
3、测试代码与单向一对一也是一样的
@SpringBootTest
public class AssociationTableTests {
@Autowired
StudentRepository studentRepository;
@Autowired
StudentInformationRepository informationRepository;
/**
* 双向一对一
*/
@Test
public void testOneToOneSave(){
// 首先给学生表(主键表)增加一条数据
Student student = new Student();
student.setStudentName("小明");
student.setStudentPwd("123456");
studentRepository.saveAndFlush(student);
// 然后再给学生信息表(外键表)增加一条数据
StudentInformation information = new StudentInformation();
information.setStudentNumber("001");
information.setStudentAge(13);
// 设置这个字段相当于给外键设置值,如果没有设置那么保存后外键字段将为null
information.setStudent(student);
informationRepository.saveAndFlush(information);
// 查询信息
System.out.println(teacherRepository.findById(student.getStudentId()));
System.out.println(informationRepository.findById(information.getInformationId()));
}
}
4、查看日志:
// 插入语句与查询语句
Hibernate:
insert
into
tb_student
(student_name, student_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_student_information
(student_id, student_age, student_number)
values
(?, ?, ?)
Hibernate:
select
teacher0_.teacher_id as teacher_1_5_0_,
teacher0_.teacher_name as teacher_2_5_0_,
teacher0_.teacher_pwd as teacher_3_5_0_
from
tb_teacher teacher0_
where
teacher0_.teacher_id=?
Optional.empty
Hibernate:
select
studentinf0_.information_id as informat1_3_0_,
studentinf0_.student_id as student_4_3_0_,
studentinf0_.student_age as student_2_3_0_,
studentinf0_.student_number as student_3_3_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_information studentinf0_
left outer join
tb_student student1_
on studentinf0_.student_id=student1_.student_id
where
studentinf0_.information_id=?
// 查询后开始报错
java.lang.StackOverflowError
at java.lang.StringBuilder.append(StringBuilder.java:136)
at com.example.jpa.entity.Student.toString(Student.java:13)
at java.lang.String.valueOf(String.java:2994)
可以发现会报如上栈溢出错误。原因:双向查询后使用(System.out)输出时,toString() 方式时各自对象相互引用导致死循环。
解决方案:
- 去除@Data注解,替换成@Getter和@Setter注解。使用@ToString(exclude = “引用类型字段”)
- 也可以重写toString()方法,把引用类型的输出删掉即可
- 查询后可以不要输出打印该对象,这样就不会死循环输出对象中的对象了(治标不治本, 不推荐)
在实体类上增加@JsonIgnoreProperties(value = "对方类引用本类的属性名")(暂时我试了时无效的,打印对象还是会报错)
3、一对多关系映射
3.1、准备一对多
1、表结构和需求
-- 需求:学生表与学生称即表的一对多的关联关系
-- 学生表(主键表):一方
-- 学生成绩表(外键表):多方
-- 学生表结构
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| student_id | bigint(20) | NO | PRI | NULL | auto_increment |
| student_name | varchar(255) | YES | | NULL | |
| student_pwd | varchar(255) | YES | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
-- 学生成绩表结构
+----------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------------+--------------+------+-----+---------+----------------+
| result_id | bigint(20) | NO | PRI | NULL | auto_increment |
| result_score | float | YES | | NULL | |
| result_subject | varchar(255) | YES | | NULL | |
| student_id | bigint(20) | YES | MUL | NULL | |
+----------------+--------------+------+-----+---------+----------------+
2、创建2个实体类对应的DAO接口
/**
* 学生表repository接口
*/
public interface StudentRepository extends JpaRepository<Student,Long> {
}
/**
* 学生成绩表repository接口
*/
public interface StudentResultRepository extends JpaRepository<StudentResult,Long> {
}
3.2、单向一对多
单向一对多的话,那么只能是:一方(主键表)为拥有方,多方(外键表)为被拥有端。(只配置一方即可)
1、创建:学生实体类(拥有方,主键表)只配置一方(主键方)即可
@Data
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "student_id")
private Long studentId;
@Column(name = "student_name")
private String studentName;
@Column(name = "student_pwd")
private String studentPwd;
/**
* 单向一对多:只需要配置一方(主键表)即可
* 一般配置@OneToMany + @JoinColumn
* 也可以只配置@OneToMany,@JoinColumn会按照默认规则生成外键
* @OneToMany:
* targetEntity:指定对方类的字节码(可选)
* fetch:指定是懒加载还是立即加载(@OneToMany中默认是懒加载)(最好必填)
* @JoinColumn:
* name:外键字段名称(必填,不然会默认生成外键字段名)
* referencedColumnName:指定引用主表的主键字段名称(注意是数据库字段不是实体类属性名)
* 注意!注意!注意!
* 一对多时一方默认时开启懒加载的,需要关闭,非则查询会报错
*/
@OneToMany(targetEntity = StudentResult.class,fetch = FetchType.EAGER)
@JoinColumn(name="student_id",referencedColumnName = "student_id")
private List<StudentResult> studentResults = new ArrayList<>();
}
2、创建:学生成绩实体类(被拥有方,外键表),多方(外键方)无需配置
@Data
@Entity
@Table(name = "tb_student_result")
public class StudentResult {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "result_id")
private Long resultId;
@Column(name = "result_subject")
private String resultSubject;
@Column(name = "result_score")
private float resultScore;
}
3、测试代码:
/**
* 单向 一对多
* 数据插入的步骤为:
* 先插入外键表数据,此时外键表中的外键为null,
* 然后在插入主键表数据,最后更新外键表中的外键
* 可以查看日志输入的顺序
*/
@Test
public void testOneToManySave(){
// 首先给学生成绩表插入两条数据
StudentResult studentResultA = new StudentResult();
studentResultA.setResultSubject("语文");
studentResultA.setResultScore(89.5f);
resultRepository.saveAndFlush(studentResultA);
StudentResult studentResultB = new StudentResult();
studentResultB.setResultSubject("数学");
studentResultB.setResultScore(92f);
resultRepository.saveAndFlush(studentResultB);
// 然后给学生表(主键表)增加一条数据
Student student = new Student();
student.setStudentName("小明");
student.setStudentPwd("123456");
student.setStudentResults(Arrays.asList(studentResultA, studentResultB));
studentRepository.saveAndFlush(student);
// 查询学生(主)表数据
System.out.println(studentRepository.findById(student.getStudentId()));
// 查询成绩(从)表数据
System.out.println(resultRepository.findById(studentResultA.getResultId()));
System.out.println(resultRepository.findById(studentResultB.getResultId()));
}
4、查看日志
// 初始化表的语句
Hibernate:
create table tb_student (
student_id bigint not null auto_increment,
student_name varchar(255),
student_pwd varchar(255),
primary key (student_id)
) engine=InnoDB
Hibernate:
create table tb_student_result (
result_id bigint not null auto_increment,
result_score float,
result_subject varchar(255),
student_id bigint,
primary key (result_id)
) engine=InnoDB
Hibernate:
alter table tb_student_result
add constraint FK5101rgeygkbcenssvt342o3kg
foreign key (student_id)
references tb_student (student_id)
Hibernate: // 插入数据语句
insert
into
tb_student_result
(result_score, result_subject)
values
(?, ?)
Hibernate:
insert
into
tb_student_result
(result_score, result_subject)
values
(?, ?)
Hibernate:
insert
into
tb_student
(student_name, student_pwd)
values
(?, ?)
Hibernate:
update
tb_student_result
set
student_id=?
where
result_id=?
Hibernate:
update
tb_student_result
set
student_id=?
where
result_id=?
Hibernate: // 查询语句
select
student0_.student_id as student_1_2_0_,
student0_.student_name as student_2_2_0_,
student0_.student_pwd as student_3_2_0_,
studentres1_.student_id as student_4_4_1_,
studentres1_.result_id as result_i1_4_1_,
studentres1_.result_id as result_i1_4_2_,
studentres1_.result_score as result_s2_4_2_,
studentres1_.result_subject as result_s3_4_2_
from
tb_student student0_
left outer join
tb_student_result studentres1_
on student0_.student_id=studentres1_.student_id
where
student0_.student_id=?
// 输出查询结果
Optional[Student(studentId=1, studentName=小明, studentPwd=123456, studentResults=[StudentResult(resultId=1, resultSubject=语文, resultScore=89.5), StudentResult(resultId=2, resultSubject=数学, resultScore=92.0)])]
Hibernate: // 查询语句
select
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_score as result_s2_4_0_,
studentres0_.result_subject as result_s3_4_0_
from
tb_student_result studentres0_
where
studentres0_.result_id=?
Optional[StudentResult(resultId=1, resultSubject=语文, resultScore=89.5)]
Hibernate:
select
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_score as result_s2_4_0_,
studentres0_.result_subject as result_s3_4_0_
from
tb_student_result studentres0_
where
studentres0_.result_id=?
Optional[StudentResult(resultId=2, resultSubject=数学, resultScore=92.0)]
PS:可能会出现如下报错信息:
org.hibernate.LazyInitializationException: failed to lazily initialize XXXXX could not initialize proxy - no Session
问题解决:这个问题是由于实体中一对多或者多对多关联关系的加载方式配置不当引起的。一对多或者多对多关联关系的加载策略使用了懒加载,结果在加载子实体时就会报:org.hibernate.LazyInitializationException: failed to lazily initialize XXXXX could not initialize proxy - no Session错误,只需要将懒加载改为急加载即可
方式一:修改实体类
// 修改学生实体类(主表),从一方获取多方的时候默认时懒加载.改成立即加载
@OneToMany(fetch = FetchType.EAGER)
方式二:配置文件修改
# 开启延迟加载
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
两者方式选择一种即可。
3.3、单向多对一
单向多对一的话:多方(外键表)为拥有方,一方(主键表)为被拥有端。(只配置多方即可)
1、创建:学生成绩实体类(拥有方,外键表)(只配置多方(外键方)即可)
@Data
@Entity
@Table(name = "tb_student_result")
public class StudentResult {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "result_id")
private Long resultId;
@Column(name = "result_subject")
private String resultSubject;
@Column(name = "result_score")
private float resultScore;
/**
* 单向多对一:只配置多方(外键方)即可。
* @ManyToOne
* name:指定对方类的字节码(可选)
* @JoinColumn
* name:外键字段名称(必填,不然会默认生成外键字段名)
* referencedColumnName:指定引用主表的主键字段名称(注意是数据库字段不是实体类属性名)
*/
@ManyToOne(targetEntity = Student.class)
@JoinColumn(name = "student_id", referencedColumnName = "student_id")
private Student student;
}
2、创建:学生实体类(被拥有方,主键表)(一方(主键方)无需配置)
@Data
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "student_id")
private Long studentId;
@Column(name = "student_name")
private String studentName;
@Column(name = "student_pwd")
private String studentPwd;
}
3、测试代码
/**
* 单向 多对一
* 数据插入的步骤为:先插入插入主键表数据,然后在外键表数据
*/
@Test
public void testManyToOneSave(){
// 首先给学生表(主键表)增加一条数据
Student student = new Student();
student.setStudentName("小明");
student.setStudentPwd("123456");
studentRepository.saveAndFlush(student);
/**
* 然后给学生成绩表插入两条数据
* 与单向一对多不同的是:setStudent(student),这个步骤就是给外键字段设置值
*/
StudentResult studentResultA = new StudentResult();
studentResultA.setResultSubject("语文");
studentResultA.setResultScore(89.5f);
studentResultA.setStudent(student);
resultRepository.saveAndFlush(studentResultA);
StudentResult studentResultB = new StudentResult();
studentResultB.setResultSubject("数学");
studentResultB.setResultScore(92f);
studentResultB.setStudent(student);
resultRepository.saveAndFlush(studentResultB);
// 查询学生(主)表数据
System.out.println(studentRepository.findById(student.getStudentId()));
// 查询成绩(从)表数据
System.out.println(resultRepository.findById(studentResultA.getResultId()));
System.out.println(resultRepository.findById(studentResultB.getResultId()));
}
4、查看日志
// 初始化表的语句
Hibernate:
create table tb_student (
student_id bigint not null auto_increment,
student_name varchar(255),
student_pwd varchar(255),
primary key (student_id)
) engine=InnoDB
Hibernate:
create table tb_student_result (
result_id bigint not null auto_increment,
result_score float,
result_subject varchar(255),
student_id bigint,
primary key (result_id)
) engine=InnoDB
Hibernate:
alter table tb_student_result
add constraint FK5101rgeygkbcenssvt342o3kg
foreign key (student_id)
references tb_student (student_id)
Hibernate: // 插入语句
insert
into
tb_student
(student_name, student_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_student_result
(result_score, result_subject, student_id)
values
(?, ?, ?)
Hibernate:
insert
into
tb_student_result
(result_score, result_subject, student_id)
values
(?, ?, ?)
Hibernate: // 查询学生表语句
select
student0_.student_id as student_1_2_0_,
student0_.student_name as student_2_2_0_,
student0_.student_pwd as student_3_2_0_
from
tb_student student0_
where
student0_.student_id=?
Optional[Student(studentId=1, studentName=小明, studentPwd=123456)]
Hibernate: // 关联查询语句
select
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_score as result_s2_4_0_,
studentres0_.result_subject as result_s3_4_0_,
studentres0_.student_id as student_4_4_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_result studentres0_
left outer join
tb_student student1_
on studentres0_.student_id=student1_.student_id
where
studentres0_.result_id=?
Optional[StudentResult(resultId=1, resultSubject=语文, resultScore=89.5, student=Student(studentId=1, studentName=小明, studentPwd=123456))]
Hibernate:
select
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_score as result_s2_4_0_,
studentres0_.result_subject as result_s3_4_0_,
studentres0_.student_id as student_4_4_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_result studentres0_
left outer join
tb_student student1_
on studentres0_.student_id=student1_.student_id
where
studentres0_.result_id=?
Optional[StudentResult(resultId=2, resultSubject=数学, resultScore=92.0, student=Student(studentId=1, studentName=小明, studentPwd=123456))]
3.4、双向一对多
双向一对多的话:多方(外键表)为拥有方,一方(主键表)为被拥有端。
1、创建:学生成绩实体类(拥有方,多方、外键表)(多方 / 外键方 配置:@ManyToOne + @JoinColumn)
PS:实际跟单向多对一代码一样,多了一个重写toString方法,为了避免输出死循环
@Data
@ToString(exclude = "student") // 为了避免输出死循环重写了toString
@Entity
@Table(name = "tb_student_result")
public class StudentResult {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "result_id")
private Long resultId;
@Column(name = "result_subject")
private String resultSubject;
@Column(name = "result_score")
private float resultScore;
/**
* 单向多对一:只配置多方(外键方)即可。
* @ManyToOne
* name:指定对方类的字节码(可选)
* @JoinColumn
* name:外键字段名称(必填,不然会默认生成外键字段名)
* referencedColumnName:指定引用主表的主键字段名称(注意是数据库字段不是实体类属性名)
*/
@ManyToOne(targetEntity = Student.class)
@JoinColumn(name = "student_id", referencedColumnName = "student_id")
private Student student;
}
2、创建:学生实体类(被拥有方,一方、主键表)(一方 / 主键方 配置:@OneToMany)
PS:实际上跟单向多对一相比:加了一个属性加上了@OneToMany,并且重写toString方法避免死循环
@Data
@ToString(exclude = "studentResults") // 为了避免输出死循环重写了toString
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "student_id")
private Long studentId;
@Column(name = "student_name")
private String studentName;
@Column(name = "student_pwd")
private String studentPwd;
/**
* 双向一对多:(实际就比单向多对一多了一个@OneToMany)
* 必须在一方配置:@OneToMany:mappedBy + fetch 属性
* @OneToMany
* mappedBy:放弃维护外键,值为另一方(拥有方 / 外键方 / 多方)引用本类的属性名
* fetch:指定是懒加载还是立即加载(@OneToMany中默认是懒加载)(最好必填)
*/
@OneToMany(mappedBy = "student",fetch = FetchType.EAGER)
private List<StudentResult> studentResults = new ArrayList<>();
}
3、测试代码
/**
* 双向 一对多
* 数据插入的步骤为:先插入插入主键表数据,然后在外键表数据
*/
@Test
public void testOneToManyTwoWaySave2(){
// 首先给学生表(主键表)增加一条数据
Student student = new Student();
student.setStudentName("小明");
student.setStudentPwd("123456");
studentRepository.saveAndFlush(student);
/**
* 然后给学生成绩表插入两条数据
* 与单向一对多不同的是:setStudent(student),这个步骤就是给外键字段设置值
*/
StudentResult studentResultA = new StudentResult();
studentResultA.setResultSubject("语文");
studentResultA.setResultScore(89.5f);
resultRepository.saveAndFlush(studentResultA);
StudentResult studentResultB = new StudentResult();
studentResultB.setResultSubject("数学");
studentResultB.setResultScore(92f);
resultRepository.saveAndFlush(studentResultB);
// 查询学生(主)表数据
System.out.println(studentRepository.findById(student.getStudentId()));
// 查询成绩(从)表数据
System.out.println(resultRepository.findById(studentResultA.getResultId()));
System.out.println(resultRepository.findById(studentResultB.getResultId()));
}
4、查看日志
// 建表语句跟之前一样
Hibernate: // 插入语句
insert
into
tb_student
(student_name, student_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_student_result
(result_score, result_subject, student_id)
values
(?, ?, ?)
Hibernate:
insert
into
tb_student_result
(result_score, result_subject, student_id)
values
(?, ?, ?)
Hibernate: // 关联查询语句
select
student0_.student_id as student_1_2_0_,
student0_.student_name as student_2_2_0_,
student0_.student_pwd as student_3_2_0_,
studentres1_.student_id as student_4_4_1_,
studentres1_.result_id as result_i1_4_1_,
studentres1_.result_id as result_i1_4_2_,
studentres1_.result_score as result_s2_4_2_,
studentres1_.result_subject as result_s3_4_2_,
studentres1_.student_id as student_4_4_2_
from
tb_student student0_
left outer join
tb_student_result studentres1_
on student0_.student_id=studentres1_.student_id
where
student0_.student_id=?
Optional[Student{studentId=1, studentName='小明', studentPwd='123456'}]
Hibernate: // 关联查询语句
select
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_score as result_s2_4_0_,
studentres0_.result_subject as result_s3_4_0_,
studentres0_.student_id as student_4_4_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_result studentres0_
left outer join
tb_student student1_
on studentres0_.student_id=student1_.student_id
where
studentres0_.result_id=?
Hibernate:
select
studentres0_.student_id as student_4_4_0_,
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_id as result_i1_4_1_,
studentres0_.result_score as result_s2_4_1_,
studentres0_.result_subject as result_s3_4_1_,
studentres0_.student_id as student_4_4_1_
from
tb_student_result studentres0_
where
studentres0_.student_id=?
Optional[StudentResult{resultId=1, resultSubject='语文', resultScore=89.5}]
Hibernate: // 关联查询语句
select
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_score as result_s2_4_0_,
studentres0_.result_subject as result_s3_4_0_,
studentres0_.student_id as student_4_4_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_result studentres0_
left outer join
tb_student student1_
on studentres0_.student_id=student1_.student_id
where
studentres0_.result_id=?
Hibernate:
select
studentres0_.student_id as student_4_4_0_,
studentres0_.result_id as result_i1_4_0_,
studentres0_.result_id as result_i1_4_1_,
studentres0_.result_score as result_s2_4_1_,
studentres0_.result_subject as result_s3_4_1_,
studentres0_.student_id as student_4_4_1_
from
tb_student_result studentres0_
where
studentres0_.student_id=?
Optional[StudentResult{resultId=2, resultSubject='数学', resultScore=92.0}]
PS 注意1:
双向一对多中,一方/被拥有方/主键表 一般我们是放弃外键维护的,所以想使用单向一对多的方式插入数据,那么外键是会为空的(即:先插入多方/外键表数据,然后插入一方/主键表数据,最后在一方/主键表 内给引用的多方属性设置值。如果是在单向一对多的情况下,最后会有一个update语句修改外键null的值,当时在双向一对多中并不会,最后插入完数据,外键表会为空)
PS 注意2:
双向一对多中,一方/被拥有方/主键表 中我们去掉放弃外键维护配置,然后再次使用单向一对多的方式插入数据,会发现外键字段依旧为null,当时可以看到日志中显示:JPA给我多创建了一个中间表来维护两个表的主外键。还是把两张表关联起来了。
// 去除放弃外键维护配置,然后再运行一对多中测试代码,我们再查看日志
@OneToMany(/*mappedBy = "student",*/fetch = FetchType.EAGER)
private List<StudentResult> studentResults = new ArrayList<>();
Hibernate:
create table tb_student_student_results (
student_student_id bigint not null,
student_results_result_id bigint not null
) engine=MyISAM
Hibernate:
alter table tb_student_student_results
drop index UK_3ifcd0d9c34kmalbnsk94a3h2
Hibernate:
alter table tb_student_student_results
add constraint UK_3ifcd0d9c34kmalbnsk94a3h2 unique (student_results_result_id)
Hibernate:
alter table tb_student_result
add constraint FK5101rgeygkbcenssvt342o3kg
foreign key (student_id)
references tb_student (student_id)
Hibernate:
alter table tb_student_student_results
add constraint FKknyiphtyp1nnff3jm5c5ahe3a
foreign key (student_results_result_id)
references tb_student_result (result_id)
Hibernate:
alter table tb_student_student_results
add constraint FKfpfap07ekhngj6ya5e9sx9ngb
foreign key (student_student_id)
references tb_student (student_id)
4、多对多关系映射
4.1、准备多对多
1、表结构和需求
-- 需求:学生表与学生称即表的一对多的关联关系
-- 学生表(主键表):多方
-- 老师表(主键表):多方
-- 学生老师表(外键中间表)
-- 学生表结构
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| student_id | bigint(20) | NO | PRI | NULL | auto_increment |
| student_name | varchar(255) | YES | | NULL | |
| student_pwd | varchar(255) | YES | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
-- 老师表结构
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| teacher_id | bigint(20) | NO | PRI | NULL | auto_increment |
| teacher_name | varchar(255) | YES | | NULL | |
| teacher_pwd | varchar(255) | YES | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
-- 学生老师表结构
+------------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------+------+-----+---------+-------+
| student_id | bigint(20) | NO | MUL | NULL | |
| teacher_id | bigint(20) | NO | MUL | NULL | |
+------------+------------+------+-----+---------+-------+
2、创建2个实体类对应的Dao接口
/**
* 学生表repository接口
*/
public interface StudentRepository extends JpaRepository<Student,Long> {
}
/**
* 老师表repository接口
*/
public interface TeacherRepository extends JpaRepository<Teacher,Long> {
}
4.2、单向多对多
单向多对多:两张表都为多方,谁都可以为拥有方和被拥有方。这里定义:学生表为拥有方,老师表为被拥有方
1、创建:学生实体类(拥有方)
@Data
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "student_id")
private Long studentId;
@Column(name = "student_name")
private String studentName;
@Column(name = "student_pwd")
private String studentPwd;
/**
* @JoinTable:
* name:中间表名称
* joinColumns 中间表对应本类的信息
* @JoinColumn;
* name:本类的外键字段(中间表的数据库字段)
* referencedColumnName:本类与外键(表)对应的主键(本类的主键字段)
* inverseJoinColumns 中间表对应对方类的信息
* @JoinColumn:
* name:对方类的外键(中间表的数据字段)
* referencedColumnName:对方类与外键(表)对应的主键(对方类的主键字段)
*
* 注意!注意!注意:
* 不管是一对多或者多对多:
* @OneToMany、@ManyToMany 中的fetch属性默认都是懒加载.
* 可以理解为查询本实体类中的多方(List/Set)属性时,默认是懒加载
*/
@ManyToMany(fetch = FetchType.EAGER)
@JoinTable(name="tb_student_teacher",
joinColumns=@JoinColumn(
name="student_id",
referencedColumnName = "student_id"),
inverseJoinColumns=@JoinColumn(
name="teacher_id",
referencedColumnName = "teacher_id"))
private List<Teacher> teachers = new ArrayList<>();
}
2、创建:老师实体类(被拥有方)(无需配置)
@Data
@Entity
@Table(name = "tb_teacher")
public class Teacher {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "teacher_id")
private Long teacherId;
@Column(name = "teacher_name")
private String teacherName;
@Column(name = "teacher_pwd")
private String teacherPwd;
}
3、测试代码
/**
* 单向 多对多
* 先插入被拥有端数据,然后插入拥有端数据
*/
@Test
public void testManyToMany(){
// 首先给老师表(被拥有方)增加数据
Teacher teacherA = new Teacher();
teacherA.setTeacherName("语文老师");
teacherA.setTeacherPwd("666666");
teacherRepository.saveAndFlush(teacherA);
Teacher teacherB = new Teacher();
teacherB.setTeacherName("数学老师");
teacherB.setTeacherPwd("888888");
teacherRepository.saveAndFlush(teacherB);
Teacher teacherC = new Teacher();
teacherC.setTeacherName("英语老师");
teacherC.setTeacherPwd("888888");
teacherRepository.saveAndFlush(teacherC);
// 然后给学生表数据(拥有方)增加数据
Student studentA = new Student();
studentA.setStudentName("小明");
studentA.setStudentPwd("123456");
// 这步骤设置值就是给中间表插入数据
studentA.setTeachers(Arrays.asList(teacherA,teacherB));
studentRepository.saveAndFlush(studentA);
Student studentB = new Student();
studentB.setStudentName("小明");
studentB.setStudentPwd("123456");
// 这步骤设置值就是给中间表插入数据
studentB.setTeachers(Arrays.asList(teacherB,teacherC));
studentRepository.saveAndFlush(studentB);
// 查询学生表(拥有方)数据
System.out.println(studentRepository.findById(studentA.getStudentId()));
System.out.println(studentRepository.findById(studentB.getStudentId()));
}
4、查看日志
// 建立中间表日志
Hibernate:
alter table tb_student_teacher
add constraint FKf3vdcta2bcm9seh723ge2tel
foreign key (teacher_id)
references tb_teacher (teacher_id)
Hibernate:
alter table tb_student_teacher
add constraint FKkhrh8vhu4pnumefhvuwdiby8y
foreign key (student_id)
references tb_student (student_id)
// 省略了插入数据语句和查询语句...
Optional[Student(studentId=1, studentName=小明, studentPwd=123456, teachers=[Teacher(teacherId=1, teacherName=语文老师, teacherPwd=666666), Teacher(teacherId=2, teacherName=数学老师, teacherPwd=888888)])]
// 查询语句省略...可以参考上面查询语句,一样的
Optional[Student(studentId=2, studentName=小明, studentPwd=123456, teachers=[Teacher(teacherId=2, teacherName=数学老师, teacherPwd=888888), Teacher(teacherId=3, teacherName=英语老师, teacherPwd=888888)])]
// 完整的日志
Hibernate: // 插入数据
insert
into
tb_teacher
(teacher_name, teacher_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_teacher
(teacher_name, teacher_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_teacher
(teacher_name, teacher_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_student
(student_name, student_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_student_teacher
(student_id, teacher_id)
values
(?, ?)
Hibernate:
insert
into
tb_student_teacher
(student_id, teacher_id)
values
(?, ?)
Hibernate:
insert
into
tb_student
(student_name, student_pwd)
values
(?, ?)
Hibernate:
insert
into
tb_student_teacher
(student_id, teacher_id)
values
(?, ?)
Hibernate:
insert
into
tb_student_teacher
(student_id, teacher_id)
values
(?, ?)
Hibernate: // 查询语句
select
student0_.student_id as student_1_2_0_,
student0_.student_name as student_2_2_0_,
student0_.student_pwd as student_3_2_0_,
teachers1_.student_id as student_1_5_1_,
teacher2_.teacher_id as teacher_2_5_1_,
teacher2_.teacher_id as teacher_1_6_2_,
teacher2_.teacher_name as teacher_2_6_2_,
teacher2_.teacher_pwd as teacher_3_6_2_
from
tb_student student0_
left outer join
tb_student_teacher teachers1_
on student0_.student_id=teachers1_.student_id
left outer join
tb_teacher teacher2_
on teachers1_.teacher_id=teacher2_.teacher_id
where
student0_.student_id=?
Student(studentId=1, studentName=小明, studentPwd=123456, teachers=[Teacher(teacherId=1, teacherName=语文老师, teacherPwd=666666), Teacher(teacherId=2, teacherName=数学老师, teacherPwd=888888)])
2
Hibernate:
select
student0_.student_id as student_1_2_0_,
student0_.student_name as student_2_2_0_,
student0_.student_pwd as student_3_2_0_,
teachers1_.student_id as student_1_5_1_,
teacher2_.teacher_id as teacher_2_5_1_,
teacher2_.teacher_id as teacher_1_6_2_,
teacher2_.teacher_name as teacher_2_6_2_,
teacher2_.teacher_pwd as teacher_3_6_2_
from
tb_student student0_
left outer join
tb_student_teacher teachers1_
on student0_.student_id=teachers1_.student_id
left outer join
tb_teacher teacher2_
on teachers1_.teacher_id=teacher2_.teacher_id
where
student0_.student_id=?
Student(studentId=2, studentName=小明, studentPwd=123456, teachers=[Teacher(teacherId=2, teacherName=数学老师, teacherPwd=888888), Teacher(teacherId=3, teacherName=英语老师, teacherPwd=888888)])
2
Hibernate:
select
teacher0_.teacher_id as teacher_1_6_0_,
teacher0_.teacher_name as teacher_2_6_0_,
teacher0_.teacher_pwd as teacher_3_6_0_
from
tb_teacher teacher0_
where
teacher0_.teacher_id=?
Teacher(teacherId=2, teacherName=数学老师, teacherPwd=888888)
4.3、双向多对多
双向多对多:两张表都为多方,谁都可以为拥有方和被拥有方。这里定义:学生表为拥有方,老师表为被拥有方
1、创建:学生实体类(拥有方)(参考单向多对多代码,为了避免死循环重写了ToString方法)
@Data
@ToString(exclude = "teachers")
@Entity
@Table(name = "tb_student")
public class Student implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "student_id")
private Long studentId;
@Column(name = "student_name")
private String studentName;
@Column(name = "student_pwd")
private String studentPwd;
/**
* @JoinTable:
* name:中间表名称
* joinColumns 中间表对应本类的信息
* @JoinColumn;
* name:本类的外键字段(中间表的数据库字段)
* referencedColumnName:本类与外键(表)对应的主键(本类的主键字段)
* inverseJoinColumns 中间表对应对方类的信息
* @JoinColumn:
* name:对方类的外键(中间表的数据字段)
* referencedColumnName:对方类与外键(表)对应的主键(对方类的主键字段)
*
* 注意!注意!注意:
* 不管是一对多或者多对多:
* @OneToMany、@ManyToMany 中的fetch属性默认都是懒加载.
* 可以理解为查询本实体类中的多方(List/Set)属性时,默认是懒加载
*/
@ManyToMany(fetch = FetchType.EAGER)
@JoinTable(name="tb_student_teacher",
joinColumns=@JoinColumn(
name="student_id",
referencedColumnName = "student_id"),
inverseJoinColumns=@JoinColumn(
name="teacher_id",
referencedColumnName = "teacher_id"))
private List<Teacher> teachers = new ArrayList<>();
}
2、创建:老师实体类(被拥有方)(增加@ManyToMany和重写ToString方法)
@Data
@Entity
@Table(name = "tb_teacher")
public class Teacher {
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)
@Column(name = "teacher_id")
private Long teacherId;
@Column(name = "teacher_name")
private String teacherName;
@Column(name = "teacher_pwd")
private String teacherPwd;
/**
* 双向多对多:
* 需要配置 @ManyToMany:mappedBy + fetch 属性
* @ManyToMany
* mappedBy:放弃维护外键,值为另一方(拥有方)引用本类的属性名
* fetch:指定是懒加载还是立即加载(@OneToMany中默认是懒加载)(最好必填)
*/
@ManyToMany(mappedBy = "teachers",fetch = FetchType.EAGER)
private List<Student> students = new ArrayList<>();
}
3、测试代码
/**
* 单向/双向 多对多
* 先插入被拥有端数据,然后插入拥有端数据
*/
@Test
public void testManyToMany(){
// 首先给老师表(被拥有方)增加数据
Teacher teacherA = new Teacher();
teacherA.setTeacherName("语文老师");
teacherA.setTeacherPwd("666666");
teacherRepository.saveAndFlush(teacherA);
Teacher teacherB = new Teacher();
teacherB.setTeacherName("数学老师");
teacherB.setTeacherPwd("888888");
teacherRepository.saveAndFlush(teacherB);
Teacher teacherC = new Teacher();
teacherC.setTeacherName("英语老师");
teacherC.setTeacherPwd("888888");
teacherRepository.saveAndFlush(teacherC);
// 然后给学生表数据(拥有方)增加数据
Student studentA = new Student();
studentA.setStudentName("小明");
studentA.setStudentPwd("123456");
// 这步骤设置值就是给中间表插入数据
studentA.setTeachers(Arrays.asList(teacherA,teacherB));
studentRepository.saveAndFlush(studentA);
Student studentB = new Student();
studentB.setStudentName("小明");
studentB.setStudentPwd("123456");
// 这步骤设置值就是给中间表插入数据
studentB.setTeachers(Arrays.asList(teacherB,teacherC));
studentRepository.saveAndFlush(studentB);
// 查询学生表(拥有方)数据
Student student1 = studentRepository.findById(studentA.getStudentId()).get();
System.out.println(student1.getTeachers().size());
Student student2 = studentRepository.findById(studentB.getStudentId()).get();
System.out.println(student2.getTeachers().size());
// 查询老师表(被拥有方)数据
Teacher teacher = teacherRepository.findById(teacherB.getTeacherId()).get();
System.out.println(teacher);
System.out.println(teacher.getStudents().size());
}
4、查看日志
Hibernate:
select
student0_.student_id as student_1_2_0_,
student0_.student_name as student_2_2_0_,
student0_.student_pwd as student_3_2_0_,
teachers1_.student_id as student_1_5_1_,
teacher2_.teacher_id as teacher_2_5_1_,
teacher2_.teacher_id as teacher_1_6_2_,
teacher2_.teacher_name as teacher_2_6_2_,
teacher2_.teacher_pwd as teacher_3_6_2_
from
tb_student student0_
left outer join
tb_student_teacher teachers1_
on student0_.student_id=teachers1_.student_id
left outer join
tb_teacher teacher2_
on teachers1_.teacher_id=teacher2_.teacher_id
where
student0_.student_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Hibernate:
select
teachers0_.student_id as student_1_5_0_,
teachers0_.teacher_id as teacher_2_5_0_,
teacher1_.teacher_id as teacher_1_6_1_,
teacher1_.teacher_name as teacher_2_6_1_,
teacher1_.teacher_pwd as teacher_3_6_1_
from
tb_student_teacher teachers0_
inner join
tb_teacher teacher1_
on teachers0_.teacher_id=teacher1_.teacher_id
where
teachers0_.student_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Student{studentId=7, studentName='小明', studentPwd='123456'}
2
Hibernate:
select
student0_.student_id as student_1_2_0_,
student0_.student_name as student_2_2_0_,
student0_.student_pwd as student_3_2_0_,
teachers1_.student_id as student_1_5_1_,
teacher2_.teacher_id as teacher_2_5_1_,
teacher2_.teacher_id as teacher_1_6_2_,
teacher2_.teacher_name as teacher_2_6_2_,
teacher2_.teacher_pwd as teacher_3_6_2_
from
tb_student student0_
left outer join
tb_student_teacher teachers1_
on student0_.student_id=teachers1_.student_id
left outer join
tb_teacher teacher2_
on teachers1_.teacher_id=teacher2_.teacher_id
where
student0_.student_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Hibernate:
select
teachers0_.student_id as student_1_5_0_,
teachers0_.teacher_id as teacher_2_5_0_,
teacher1_.teacher_id as teacher_1_6_1_,
teacher1_.teacher_name as teacher_2_6_1_,
teacher1_.teacher_pwd as teacher_3_6_1_
from
tb_student_teacher teachers0_
inner join
tb_teacher teacher1_
on teachers0_.teacher_id=teacher1_.teacher_id
where
teachers0_.student_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Student{studentId=8, studentName='小明', studentPwd='123456'}
2
Hibernate:
select
teacher0_.teacher_id as teacher_1_6_0_,
teacher0_.teacher_name as teacher_2_6_0_,
teacher0_.teacher_pwd as teacher_3_6_0_,
students1_.teacher_id as teacher_2_5_1_,
student2_.student_id as student_1_5_1_,
student2_.student_id as student_1_2_2_,
student2_.student_name as student_2_2_2_,
student2_.student_pwd as student_3_2_2_
from
tb_teacher teacher0_
left outer join
tb_student_teacher students1_
on teacher0_.teacher_id=students1_.teacher_id
left outer join
tb_student student2_
on students1_.student_id=student2_.student_id
where
teacher0_.teacher_id=?
Hibernate:
select
teachers0_.student_id as student_1_5_0_,
teachers0_.teacher_id as teacher_2_5_0_,
teacher1_.teacher_id as teacher_1_6_1_,
teacher1_.teacher_name as teacher_2_6_1_,
teacher1_.teacher_pwd as teacher_3_6_1_
from
tb_student_teacher teachers0_
inner join
tb_teacher teacher1_
on teachers0_.teacher_id=teacher1_.teacher_id
where
teachers0_.student_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Hibernate:
select
teachers0_.student_id as student_1_5_0_,
teachers0_.teacher_id as teacher_2_5_0_,
teacher1_.teacher_id as teacher_1_6_1_,
teacher1_.teacher_name as teacher_2_6_1_,
teacher1_.teacher_pwd as teacher_3_6_1_
from
tb_student_teacher teachers0_
inner join
tb_teacher teacher1_
on teachers0_.teacher_id=teacher1_.teacher_id
where
teachers0_.student_id=?
Hibernate:
select
students0_.teacher_id as teacher_2_5_0_,
students0_.student_id as student_1_5_0_,
student1_.student_id as student_1_2_1_,
student1_.student_name as student_2_2_1_,
student1_.student_pwd as student_3_2_1_
from
tb_student_teacher students0_
inner join
tb_student student1_
on students0_.student_id=student1_.student_id
where
students0_.teacher_id=?
Teacher{teacherId=11, teacherName='数学老师', teacherPwd='888888'}
2
SpringData JPA 实体类关联(详版)
实体与实体之间的关联关系⼀共分为四种,分别为:OneToOne、OneToMany、ManyToOne 及 ManyToMany;实体类之间主外键关联字段或属性使用注解一般分为这三种:@JoinColumn、@JoinColumns、@JoinTable。⽽实体之间的关联关系⼜分为双向的和单向的。实体之间的关联关系是在 JPA 使⽤中最容易发⽣问题的地⽅,接下来我将⼀⼀揭晓并解释。
1、OneToOne 一对一关系映射
1、表结构与实体类初始化
1、表结构和需求
-- 需求: 用户表与用户信息表的一对一的关联关系。
-- 用户表 (user)(主键表): 一方
-- 用户信息表 (user_info)(外键表): 一方
-- 用户表是⽤户的主信息, 用户信息表是⽤户的扩展信息, 两者是⼀对⼀关系, user_info 表⾥有⼀个 user_id 作为关联关系的外键
-- 用户表结构
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| user_id | bigint | NO | PRI | NULL | |
| username | varchar(255) | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+
-- 用户信息表结构
+--------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+-------+
| user_info_id | bigint | NO | PRI | NULL | |
| country | varchar(255) | YES | | NULL | |
| user_id | bigint | YES | MUL | NULL | |
+--------------+--------------+------+-----+---------+-------+
2、创建2个实体类对应的Repository接口
// 用户类对应repository接口
public interface UserRepository extends JpaRepository<User, Long> {
}
// 用户信息类对应repository接口
public interface UserInfoRepository extends JpaRepository<UserInfo, Long> {
}
3、先建两个实体类:User 和 UserInfo,暂未建立关联关系,讲解特定注解时补充。
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "user")
public class User {
@Id
@Column(name = "user_id")
private Long userId;
@Column(name = "username")
private String username;
}
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@ToString(exclude = "user")
@Entity
@Table(name = "user_info")
public class UserInfo {
@Id
@Column(name = "user_info_id")
private Long userInfoId;
@Column(name = "country")
private String country;
}
后续代码将会对下面这部分共同代码略写。
2、OneToOne 源码解读
@OneToOne:⼀般表示对象之间⼀对⼀的关联关系,它可以放在 field 上⾯,也可以放在 get/set ⽅法上⾯。其中 JPA 协议有规定:如果是配置双向关联,维护关联关系的是拥有外键的⼀⽅,⽽另⼀⽅必须配置 mappedBy;如果是单项关联,直接配置在拥有外键的⼀⽅即可。
public @interface OneToOne {
/**
* 表示关系⽬标实体,默认该注解标识的返回值的类型的类。该属性通常可以不指定, ORM JPA会根据属性类型自动判断
*/
Class targetEntity() default void.class;
/**
* cascade 级联操作策略,就是我们常说的级联操作.
* CascadeType 的枚举值只有五个,分别如下:
* - 级联新建:CascadeType.PERSIST
* - 级联删除:CascadeType.REMOVE
* - 级联刷新:CascadeType.REFRESH
* - 级联更新:CascadeType.MERGE
* - 级联脱管:CascadeType.DETACH
* - 全部级联:CascadeType.ALL
*/
CascadeType[] cascade() default {};
/**
* 数据获取⽅式 EAGER(⽴即加载)/LAZY(延迟加载)
*/
FetchType fetch() default EAGER;
/**
* 是否允许为空,默认是可选的,也就表示可以为空
*/
boolean optional() default true;
/**
* 放弃外键维护权: 指定从表实体类中引用主表对象的名称(常用), 必须双向关联使用才有效, 在单项关联中设置了也无效
*/
String mappedBy() default "";
/**
* 当被标识的字段发⽣删除或者置空操作后,是否应⽤级联删除
* 即进⾏通过删除操作,默认 false,注意与 CascadeType.REMOVE 级联删除的区别
*/
boolean orphanRemoval() default false;
}
3、OneToOne 单向映射
这里提示一下:实际上OneToOne 单向映射案例与 ManyToOne 单向映射案例基本一样。
单向一对一映射,先建立实体类关联关系,单向一对一必须只能配置在从实体类一方,主类方的实体类配置自己的字段即可。(单向OneToOne:OneToOne用在什么实体类,外键就建立到什么实体类中,所以你感受下为什么是只能配置在从表方了)
public class User implements Serializable { // 用户类(主表),单向一对一从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
/**
* @OneToOne:
* targetEntity: 指定另一方的类的字节码(即:从主实体类)(默认可以不配置)
* cascade: 开启级联操作
* orphanRemoval: 开启孤儿和删除, 需搭配级联hi使用
* @JoinColumn(都是数据库字段名):
* name: 自己表中外键字段名
* referencedColumnName: 对应关联主表的主键字段名
*/
@OneToOne(targetEntity = User.class, cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
1、非级联操作测试(默认)
1、这里主要测试单向一对一的非级联新增、删除、更新。由于默认就是非级联操作,所以对应实体类就使用上面即可,测试代码如下:
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 非级联添加: 必须先保存user, 再保存userInfo, 因为现在外键维护方是userInfo
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void save() {
System.out.println("===========save()===========");
User user = new User(1L, "SAM");
userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
/**
* 非级联更新测试: 没有什么好测试, 各种更新各自的即可。需要新增可以参考新增test
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void update() {
System.out.println("===========update()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setCountry("CNN");
userInfoRepository.saveAndFlush(userInfo);
userInfo.getUser().setUsername("SAMS");
userRepository.saveAndFlush(userInfo.getUser());
}
/**
* 非级联删除:
* - 正常先删除外键维护的表数据(并且会自动删除外键中间表数据), 然后才能删除userInfo非外键
* - 如果先删除user, JPA会先自动update userInfo把关联关系去掉, 然后删除user
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void delete() {
System.out.println("===========delete()===========");
// 建议先删除从表数据, 等从表中数据删完, 再删除主表中关联的数据
userInfoRepository.deleteById(1L);
userRepository.deleteById(1L);
}
}
2、日志打印如下:
save() 日志
===========save()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)update() 日志
===========update()=========== ## 更新前会先查询是否存在,省略了查询语句(此查询是一个关联查询) Hibernate: update user_info set country=?, user_id=? where user_info_id=? Hibernate: update user set username=? where user_id=?delete() 日志
===========delete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
2、有级联操作测试
1、由于默认是不开启级联操作的,所以需要在实体类上手动设置打开级联操作。
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
User user = new User(1L, "DEV");
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
/**
* 级联更新: 需要把更新的user设置到userInfo对象中, 或者直接拿出来更改, 而后直接更新userInfo即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setCountry("CNN");
userInfo.getUser().setUsername("SAMS");
userInfoRepository.saveAndFlush(userInfo);
// 级联操作可以省下此步骤: userRepository.saveAndFlush(userInfo.getUser());
}
/**
* 级联删除: 只需要使用userInfo删除即可, 会级联把user信息一起删除
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
// 建议先删除从表数据, 等从表中数据删完, 会自动删除主表中关联的数据
userInfoRepository.deleteById(1L);
}
}
2、日志打印
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=?, user_id=? where user_info_id=? Hibernate: update user set username=? where user_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
3、延迟加载测试
1、由于一对一默认就是立即加载,我们需要手动设置为延迟加载
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 延迟加载查询需要加上@Transactional注解防止no session异常
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL, 没有使用到就只查user自己的信息
*/
@Test
@Order(2)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
}
/**
* 延迟加载: 与上面同理
*/
@Test
@Order(3)
@Transactional
void lazyQueryAll() {
System.out.println("===========lazyQueryAll()===========");
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
}
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
User user = new User(1L, "DEV");
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
}
2、打印日志如下:
lazyQueryById() 日志
===========lazyQueryById()=========== ## 可以发现使用到user就查询user的SQL, 使用到userInfo就查userInfo的SQL Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_ from user_info userinfo0_ where userinfo0_.user_info_id=? CN Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? DEVlazyQueryAll() 日志
## 同上, 使用到关联对象才会去查询SQL ===========lazyQueryAll()=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ CN Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? DEV
4、立即加载测试(默认)
1、由于一对一默认就是立即加载,所以不需要增加任何配置,这里需要注意:如下测试代码初始新增使用了级联模式(所以实体类中要开启级联操作)
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 立即加载查询可以去除@Transactional注解
/**
* 立即加载: 可以发现查询SQL是关联查询, 一次查询出所有数据.(包括关联表的)
*/
@Test
@Order(2)
void eagerQueryById() {
System.out.println("===========eagerQueryById()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
}
/**
* 立即加载: 与上面同理
*/
@Test
@Order(3)
void eagerQueryAll() {
System.out.println("===========eagerQueryAll()===========");
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
}
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
User user = new User(1L, "DEV");
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
}
2、打印日志如下
eagerQueryById() 日志
===========eagerQueryById()=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_info_id=? CNeagerQueryAll() 日志
===========eagerQueryAll()=========== ## 可以发现只是查询了user对象, JPA发送了2条SQL. Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? CN
4、OneToOne 双向映射
双向一对一实体类配置(是否需要级联以及懒加载看自己业务需求)
public class User implements Serializable { // 用户类(主表),单向一对一从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private UserInfo userInfo;
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
/**
* @OneToOne:
* targetEntity: 指定另一方的类的字节码(即:从主实体类)(默认可以不配置)
* cascade: 开启级联操作
* orphanRemoval: 开启孤儿和删除, 需搭配级联hi使用
* @JoinColumn(都是数据库字段名):
* name: 自己表中外键字段名
* referencedColumnName: 对应关联主表的主键字段名
*/
@OneToOne(targetEntity = User.class, cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
1、非级联操作测试(默认)
1、实体类配置与测试代码如下
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(mappedBy = "user")
private UserInfo userInfo;
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 非级联添加: 必须先保存user, 再保存userInfo, 因为现在外键维护方是userInfo
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void save() {
System.out.println("===========save()===========");
User user = new User(1L, "SAM", null);
userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
// 如下保存会报错, UserInfo#user字段在保存时不能为null
// userInfoRepository.saveAndFlush(new UserInfo(2L, "EN", null));
}
/**
* 非级联更新测试: 没有什么好测试, 各种更新各自的即可。需要新增可以参考新增test
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void update() {
System.out.println("===========update()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setCountry("CNN");
userInfoRepository.saveAndFlush(userInfo);
userInfo.getUser().setUsername("SAMS");
userRepository.saveAndFlush(userInfo.getUser());
}
/**
* 非级联删除:
* - 正常先删除外键维护的表数据(并且会自动删除外键中间表数据), 然后才能删除userInfo非外键
* - 如果先删除user, JPA会先自动update userInfo把关联关系去掉, 然后删除user
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void delete() {
System.out.println("===========delete()===========");
// 建议先删除从表数据, 等从表中数据删完, 再删除主表中关联的数据
userInfoRepository.deleteById(1L);
userRepository.deleteById(1L);
}
}
2、日志打印如下:
save() 日志
===========save()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)update() 日志
===========update()=========== ## 更新前会先查询是否存在,省略了查询语句(此查询是一个关联查询) Hibernate: update user_info set country=?, user_id=? where user_info_id=? Hibernate: update user set username=? where user_id=?delete() 日志
===========delete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
2、有级联操作测试
1、实体类配置与测试代码如下
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private UserInfo userInfo;
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 从类方级联新增
User user = new User(1L, "DEV", null);
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
System.out.println("===========分割线===========");
// 主类方级联新增
UserInfo userInfo2 = new UserInfo(2L, "EN", null);
User user2 = new User(2L, "UAT", userInfo2);
userInfo2.setUser(user2);
userRepository.saveAndFlush(user2);
}
/**
* 级联更新: 需要把更新的user设置到userInfo对象中, 或者直接拿出来更改, 而后直接更新userInfo即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
// 从类方级联更新
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setCountry("CNN");
userInfo.getUser().setUsername("SAMS");
userInfoRepository.saveAndFlush(userInfo);
// 级联操作可以省下此步骤: userRepository.saveAndFlush(userInfo.getUser());
System.out.println("===========分割线===========");
// 主类方级联更新
User user = userRepository.findById(2L).get();
user.setUsername("UATS");
user.getUserInfo().setCountry("ENN");
userRepository.saveAndFlush(user);
}
/**
* 级联删除: 只需要使用userInfo删除即可, 会级联把user信息一起删除
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
// 从类方级联删除, 建议先删除从表数据, 等从表中数据删完, 会自动删除主表中关联的数据
userInfoRepository.deleteById(1L);
System.out.println("===========分割线===========");
// 主类方级联删除
userRepository.deleteById(2L);
}
}
、日志打印
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) ===========分割线=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=?, user_id=? where user_info_id=? Hibernate: update user set username=? where user_id=? ===========分割线=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user set username=? where user_id=? Hibernate: update user_info set country=?, user_id=? where user_info_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=? ===========分割线=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
3、延迟加载测试(主类懒加载失效)
1、实体类配置与测试代码如下
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
// fetch = FetchType.LAZY 主类懒加载配置无效
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
private UserInfo userInfo;
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 延迟加载查询需要加上@Transactional注解防止no session异常
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL, 没有使用到就只查user自己的信息
*/
@Test
@Order(2)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
// 从类方级联查询
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
System.out.println("===========分割线===========");
// 主类方级联查询 (尽管在User类中设置了懒加载, 可以发现SQL已经打印了2条, 因为懒加载失效了)
User user = userRepository.findById(2L).get();
System.out.println(user.getUsername());
}
/**
* 延迟加载: 与上面同理
*/
@Test
@Order(3)
@Transactional
void lazyQueryAll() {
System.out.println("===========lazyQueryAll()===========");
// 主类方级联查询 (因为查询所有会有缓存问题, 所以把主类级联放前面, 为了测试出懒加载失效问题)
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
System.out.println("===========分割线===========");
// 从类方级联查询
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
}
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 从类方级联新增
User user = new User(1L, "DEV", null);
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
System.out.println("===========分割线===========");
// 主类方级联新增
UserInfo userInfo2 = new UserInfo(2L, "EN", null);
User user2 = new User(2L, "UAT", userInfo2);
userInfo2.setUser(user2);
userRepository.saveAndFlush(user2);
}
}
2、打印日志如下:
lazyQueryById() 日志
===========lazyQueryById()=========== ## 可以发现从类的延迟加载查询正常,没有使用就没有查询 Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_ from user_info userinfo0_ where userinfo0_.user_info_id=? CN ===========分割线=========== ## 而主类中虽然也设置了延迟加载查询, 可是没有生效 Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_ from user_info userinfo0_ where userinfo0_.user_id=? UATlazyQueryAll() 日志
===========lazyQueryAll()=========== ## 主类中设置了延迟加载查询, 可是没有生效. 依旧时立即加载 Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_ from user_info userinfo0_ where userinfo0_.user_id=? Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_ from user_info userinfo0_ where userinfo0_.user_id=? DEV ===========分割线=========== ## 从类中设置了懒加载, 正常生效了 Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ CN
4、立即加载测试(默认)
1、实体类配置与测试代码如下
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private UserInfo userInfo;
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 立即加载查询可以去除@Transactional注解
/**
* 立即加载: 可以发现查询SQL是关联查询, 一次查询出所有数据.(包括关联表的)
*/
@Test
@Order(2)
void eagerQueryById() {
System.out.println("===========eagerQueryById()===========");
// 从类方级联查询
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
System.out.println("===========分割线===========");
// 主类方级联查询
User user = userRepository.findById(2L).get();
System.out.println(user.getUsername());
}
/**
* 立即加载: 与上面同理
*/
@Test
@Order(3)
void eagerQueryAll() {
System.out.println("===========eagerQueryAll()===========");
// 从类方级联查询
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
System.out.println("===========分割线===========");
// 主类方级联查询
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
}
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 从类方级联新增
User user = new User(1L, "DEV", null);
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
System.out.println("===========分割线===========");
// 主类方级联新增
UserInfo userInfo2 = new UserInfo(2L, "EN", null);
User user2 = new User(2L, "UAT", userInfo2);
userInfo2.setUser(user2);
userRepository.saveAndFlush(user2);
}
}
2、打印日志如下
eagerQueryById() 日志
===========eagerQueryById()=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_info_id=? CN ===========分割线=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_, userinfo1_.user_id as user_id3_1_1_ from user user0_ left outer join user_info userinfo1_ on user0_.user_id=userinfo1_.user_id where user0_.user_id=? UATeagerQueryAll() 日志
===========eagerQueryAll()=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_, userinfo1_.user_id as user_id3_1_1_ from user user0_ left outer join user_info userinfo1_ on user0_.user_id=userinfo1_.user_id where user0_.user_id=? Hibernate: select userinfo0_.user_info_id as user_inf1_1_1_, userinfo0_.country as country2_1_1_, userinfo0_.user_id as user_id3_1_1_, user1_.user_id as user_id1_0_0_, user1_.username as username2_0_0_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_id=? Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_, userinfo1_.user_id as user_id3_1_1_ from user user0_ left outer join user_info userinfo1_ on user0_.user_id=userinfo1_.user_id where user0_.user_id=? Hibernate: select userinfo0_.user_info_id as user_inf1_1_1_, userinfo0_.country as country2_1_1_, userinfo0_.user_id as user_id3_1_1_, user1_.user_id as user_id1_0_0_, user1_.username as username2_0_0_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_id=? CN ===========分割线=========== Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ Hibernate: select userinfo0_.user_info_id as user_inf1_1_1_, userinfo0_.country as country2_1_1_, userinfo0_.user_id as user_id3_1_1_, user1_.user_id as user_id1_0_0_, user1_.username as username2_0_0_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_id=? Hibernate: select userinfo0_.user_info_id as user_inf1_1_1_, userinfo0_.country as country2_1_1_, userinfo0_.user_id as user_id3_1_1_, user1_.user_id as user_id1_0_0_, user1_.username as username2_0_0_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_id=? DEV
5、OneToOne 扩展
1、OneToOne 外键生成规则
1、@OneToOne 单独使用(默认生成的外键字段名称为:属性名_主键名 = 外键表+_id)
public class User implements Serializable { // 用户类(主表),单向一对一从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne
private User user;
}
## 启动项目可以看到建表日志,默认生成的外键为外键表+_id
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_user_id bigint, primary key (user_info_id))
Hibernate: alter table user_info add constraint FKi1mjqtts0we8oomodkc0etsqp foreign key (user_user_id) references user (user_id)
2、搭配@JoinColumn使用来指定外键名称,@OneToOne + JoinColumn 组合使用(可以自定义外键字段名)
public class User implements Serializable { // 用户类(主表),单向一对一从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@OneToOne
@JoinColumn(name = "user_id")
private User user;
}
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_id bigint, primary key (user_info_id))
Hibernate: alter table user_info add constraint FKn8pl63y4abe7n0ls6topbqjh2 foreign key (user_id) references user (user_id)
2、mappedBy 属性注意事项
只有关联关系的维护⽅才能操作两个实体之间外键的关系。被维护⽅即使设置了维护⽅属性进⾏存储也不会更新外键关联。
mappedBy 不能与 @JoinColumn 或者 @JoinTable 同时使⽤,因为没有意义,关联关系不在这⾥⾯维护。
此外,mappedBy 的值是指另⼀⽅的实体⾥⾯属性的字段,⽽不是数据库字段,也不是实体的对象的名字。也就是维护关联关系的⼀⽅属性字段名称,或者加了 @JoinColumn/@JoinTable 注解的属性字段名称。如上⾯的 User 例⼦ user ⾥⾯ mappedBy 的值,就是 UserInfo ⾥⾯的 user 字段的名字。
3、CascadeType 属性介绍
在 Cascade 的⽤法中,CascadeType 的枚举值只有五个,分别如下:
- 级联新建:CascadeType.PERSIST
- 级联删除:CascadeType.REMOVE
- 级联刷新:CascadeType.REFRESH
- 级联更新:CascadeType.MERGE
- 级联脱管:CascadeType.DETACH
- 全部级联:CascadeType.ALL
默认是没有级联操作的,关系表不会产⽣任何影响。此外,JPA 2.0 还新增了 CascadeType.DETACH,即级联实体到 Detach 状态。
4、orphanRemoval 属性用法
orphanRemoval:表示当关联关系被删除的时候,是否应⽤级联删除,默认 false。看看下面的官方解释。
JPA的官方文档以及规范中明确说明,如果JavaBean中父实体和子实体之间有一对一或一对多的级联关系的时候,如果我们想要删除父实体,也必须要级联删除子实体,需要被删除的级联关系中的子实体则被称为孤儿实体。
orphanremoval 属性的主要作用就是标记是否可以删除孤儿实体,假设我们这里有一个订单的案例,订单下面有许多行记录,假设我们删除其中的一行记录的话,需要被删除的这一行记录就被称作是孤儿,当我们设置这个属性为true的时候,意思就是我们可以从这个订单的所有记录中删除标记为孤儿的这条记录。简单说就是:把 User 置空,然后 update UserInfo对象,会把 User 数据删除。
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setUser(null);
userInfoRepository.saveAndFlush(userInfo);
// 如上操作会删除user数据
1、只配置 CascadeType.ALL 级联操作,不配置孤儿删除配置。在删除userInfo前把user属性设置为null,结果:可以发现当user属性为空的时候,userInfo并没有级联删除 User 对象的数据。
2、只单独配置孤儿删除(最后会报错),由于没有配置级联操作,所以无法级联新增,更加无法级联删除。所以可以得出结论:孤儿删除就建立再级联更新和删除的基础上配置的。
3、总结:Cascade 与 orphanRemoval 的区别关系与结论
(1)Cascade 与 orphanRemoval 的关系:
- 二者的作用范围不一样,CascadeType 的作用范围是数据库,当cascade属性设置了remove时,当删除级联关系中的子集时,顺便也会将数据库中对应的数据删除。orphanremoval属性的作用范围仅仅是Java应用代码中,做级联删除的操作也只适用于Java实体代码范畴,它可以清楚JavaBean的级联关系,但并不能影响数据库的数据,只要cascade不点头是无法删除掉数据库的数据的。
(2)Cascade 与 orphanRemoval 的结论
- 不结合cascade merge时, orphanRemoval 只删除Java对象中的关系。
- 结合cascade MERGE/REFRESH/ALL 时,orphanRemoval 可以自动删除/更新
(3)Cascade 与 orphanRemoval 的区别:
- 两种设置之间的区别在于对断开关系的响应。例如:当将用户字段设置为null或另一个用户对象时。
- 如果指定了 orphanRemoval = true,则会自动删除断开连接的User实例。这对于清理没有所有者对象(例如UserInfo)的引用不应该存在的依赖对象(例如User)很有用。
- 如果仅指定了 cascade = CascadeType.REMOVE, 则不会执行自动操作,因为断开关系不是删除操作。
5、fetch 查询数据的抓取策略
1、默认是立即加载:fetch = FetchType.EAGER(默认)
- 从打印结果的SQL语句来看:当查询当前对象时,都会同时关联查询与之关联的对象。这样实际上效率会很慢,影响性能。(注意:test1() 打印结果中没有user是因为配置了
@ToString(exclude = "user"),如果没有配置会导致双向查询打印死循环问题)
2、设置延迟加载:fetch = FetchType.LAZY,修改如下配置,执行如上测试代码:
- 注意:如果test()1 要获取.getUser() 对象会报错:
failed to lazily initialize XXXXX could not initialize proxy - no Session,只能开启立即加载。又或者直接获取对象中的ID值(不要直接获取对象或者其他值,可以通过ID再次单独查询此User对象)可以参考这篇:https://blog.csdn.net/qq_45795744/article/details/123562759 - 在主类设置延迟加载会失效,从类设置延迟加载没有问题。@OneToOne懒加载失效:http://wjhsh.net/jpfss-p-11058703.html
2、JoinColumn & JoinCloumns 外键
这两个注解是集合关系,可以同时使用,@JoinColumn 表示单字段,@JoinCloumns 表示多个 @JoinColumn(组合外键)
1、JoinColumn 源码分析
我们还是先直接看一下 @JoinColumn 源码,了解下这一注解都有哪些配置项。
public @interface JoinColumn {
// 关键的字段名,默认注解上的字段名,在@OneToOne或@OneToMany代表本表的外键字段名字;
String name() default "";
// 与name相反关联对象的字段,默认主键字段 (如果是主键,可以省略)
String referencedColumnName() default "";
// 外键字段是否唯一
boolean unique() default false;
// 外键字段是否允许为空
boolean nullable() default true;
// 是否跟随一起新增
boolean insertable() default true;
// 是否跟随一起更新
boolean updatable() default true;
// JPA2.1新增,外键策略
ForeignKey foreignKey() default @ForeignKey(PROVIDER_DEFAULT);
}
其次,我们看一下 @ForeignKey(PROVIDER_DEFAULT) 里面枚举值有几个。
public enum ConstraintMode {
// 创建外键约束(物理外键)
CONSTRAINT,
// 不创建外键约束(逻辑外键)
NO_CONSTRAINT,
// 采用默认行为
PROVIDER_DEFAULT
}
2、JoinColumns 组合外键
@JoinColumns 是 JoinColumns 的复数形式,就是通过多个字段进⾏的外键关联(主表是用联合主键的情况下,外键就需要使用到 @JoinColumns + @JoinColumn 来关联),一般情况不常⽤(PostgreSQL 分区表必须组合外键)
@Entity
@Table(name = "user")
public class User implements Serializable {
// ...省略基本属性,只关注关联属性或字段
@Id
@Column(name = "user_id")
private Long userId;
@Column(name = "username")
private String username;
@OneToMany(mappedBy = "user")
private List<UserInfo> userInfos = new ArrayList<>();
}
@Entity
@Table(name = "user_info")
public class UserInfo implements Serializable {
// ...省略基本属性,只关注关联属性或字段
@Id
@Column(name = "user_info_id")
private Long userInfoId;
@Column(name = "country")
private String country;
@ManyToOne
@JoinColumns({
@JoinColumn(name = "user_info_user_id", referencedColumnName = "user_id"),
@JoinColumn(name = "user_info_username", referencedColumnName = "username")
})
private User user;
}
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_info_user_id bigint, user_info_username varchar(255), primary key (user_info_id))
Hibernate: alter table user add constraint UK_e8j7vycvna4xr1h6frja42fni unique (user_id, username)
Hibernate: alter table user_info add constraint FKhw4r3vk8t1go469xtmk4dxhd7 foreign key (user_info_user_id, user_info_username) references user (user_id, username)
3、创建外键策略测试
1、这里主要讲解一下 foreignKey 属性的使用,如下是创建外键约束(默认),也就是使用物理外键(真创建)
@JoinColumn(foreignKey = @ForeignKey(ConstraintMode.CONSTRAINT), name ="user_id")
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_id bigint, primary key (user_info_id))
Hibernate: alter table user_info add constraint FKn8pl63y4abe7n0ls6topbqjh2 foreign key (user_id) references user (user_id)
2、前面用到的是物理外键约束,在我们真正的实际应用中基本上很少这样做(不推荐),我们都是使用逻辑外键(推荐),逻辑外键就是实际上数据库存在主键和外键两个字段,不过没有在数据库层面上建立起真正的约束,而是靠我们自己用代码和逻辑自己控制。而在@JoinColumn中就有这样的一个属性可以设置不创建外键约束,接下来我们查看实例。执行查看建表SQL。
@Entity
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
@OneToMany(targetEntity = UserInfo.class)
@JoinColumn(name = "user_id", referencedColumnName = "user_id",
foreignKey = @ForeignKey(ConstraintMode.NO_CONSTRAINT))
private List<UserInfo> userInfos = new ArrayList<>();
}
public class UserInfo implements Serializable { // 用户信息类(从表),单向一对多从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_id bigint, primary key (user_info_id))
从日志中可以看出来,仅仅只创建的2数据表,没有创建主外键约束,只是在userInfo表中增加了一个外键字段而已。
4、JoinColumn 深入理解
我所理解的 @JoinColumn ,它的本质是 @Column ,从本质上来说,它并不是在做关联,它是在做映射,它把【数据库】和【实体】映射起来,使用这类注解能够实现:数据库中的一个字段,对应着,实体类中的一个字段。所以,它在做的事情,并不是把【部门】和【实体】关联起来,而是把【表】和【实体类】映射起来(但是与此同时,也就关联起来了两个实体)
@OneToOne
@JoinColumn(name = "自己", referencedColumnName = "对方")
@OneToMany
@JoinColumn(name = "对方", referencedColumnName = "自己")
@ManyToOne
@JoinColumn(name = "自己", referencedColumnName = "对方")
刚才我们发现,【1 - 1】、【N - 1】的使用方法是相同的,但是【1 - N】刚好反了过来,这是为什么。是因为,@JoinColumn 根本就不关心它所在的实体类是谁,它的 name 属性指向的,永远都是外键。因为外键始终在【多】的一方(一对一的话就默认自己是多),因此 name 属性值为【多的一方的外键】。有关 @JoinColumn 自动建表的事情,我还没有弄清楚。
3、OneToMany & ManyToOne 一对多
1、表结构与实体类初始化
1、表结构和需求(实际上表结构需求都基本一样,就是外键表数据变成了多条)
-- 需求: 用户表与用户信息表的一对多的关联关系。
-- 用户表-user (主键表): 一方
-- 用户信息表-user_info (外键表): 多方
-- 用户表是⽤户的主信息, 用户信息表是⽤户的扩展信息, 两者是⼀对多关系, user_info 表⾥有⼀个 user_id 作为关联关系的外键
-- 用户表结构
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| user_id | bigint | NO | PRI | NULL | |
| username | varchar(255) | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+
-- 用户信息表结构
+--------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+-------+
| user_info_id | bigint | NO | PRI | NULL | |
| country | varchar(255) | YES | | NULL | |
| user_id | bigint | YES | MUL | NULL | |
+--------------+--------------+------+-----+---------+-------+
2、创建2个实体类对应的Repository接口
// 用户类对应repository接口
public interface UserRepository extends JpaRepository<User, Long> {
}
// 用户信息类对应repository接口
public interface UserInfoRepository extends JpaRepository<UserInfo, Long> {
}
3、先建两个实体类:User 和 UserInfo,暂未建立关联关系,讲解特定注解时补充。
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "user")
public class User {
@Id
@Column(name = "user_id")
private Long userId;
@Column(name = "username")
private String username;
}
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@ToString(exclude = "user")
@Entity
@Table(name = "user_info")
public class UserInfo {
@Id
@Column(name = "user_info_id")
private Long userInfoId;
@Column(name = "country")
private String country;
}
后续代码将会对下面这部分共同代码略写。
2、OneToMany 源码分析
@OneToMany 代表一对多,只能使用在主表类一方(非外键拥有方),如果单向一对多关联使则用@OneToMany,如果双向关联则要与 @ManyToOne 一起使用
public @interface OneToMany {
/**
* 指定多的多方的类的字节码(即:从表实体类),该参数一般可以不指定,
* ORM-JPA会根据属性类型自动判断,默认为当前标注属性上的实体类的字节码。
*/
Class targetEntity() default void.class;
/**
* 级联操作策略,如果不填,默认关系表不会产⽣任何影响。
* 级联更新: CascadeType.MERGE
* 级联保存: CascadeType.PERSIST
* 级联刷新: CascadeType.REFRESH
* 级联删除: CascadeType.REMOVE
* 级联脱管: CascadeType.DETACH
* 全部级联: CascadeType.ALL
*/
CascadeType[] cascade() default {};
/**
* 数据获取⽅式: EAGER(⽴即加载)/LAZY(延迟加载). 默认为LAZY(延迟加载)
* 注意:
* - OneToOne 和 ManyToOne 默认时LAZY(⽴即加载)
* - OneToMany 和 ManyToMany 默认时LAZY(延迟加载)
*/
FetchType fetch() default LAZY;
/**
* 放弃外键维护权: 指定从表实体类中引用主表对象的名称(常用),
* 注意:只有关系维护⽅才能操作两者的关系。必须双向关联使用才有效, 在单项关联中设置了也无效
*/
String mappedBy() default "";
/**
* 是否关联删除。和 CascadeType.REMOVE 级联删除效果差不多。
* 两种配置了⼀个就会⾃动级联删除,存在一定的区别
*/
boolean orphanRemoval() default false;
}
3、OneToMany 单向映射
单向一对多映射,先建立实体类关联关系,单向一对多只需要配置在一方从实体类即可,多方的实体类配置自己的字段即可。
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
/**
* @OneToMany:
* mappedBy: 单向中设置也无效, 并且无法在与@JoinTable或@JoinColumn同时定义,JPA会报错
* targetEntity: 指定多的多方的类的字节码(即:从表实体类)(默认可以不配置)
* cascade: 级联操作策略设置
* fetch: 数据加载方式, EAGER(⽴即加载)/LAZY(延迟加载), OneToMany默认为LAZY(延迟加载)
* orphanRemoval: 是否使用孤儿(关联)删除,默认没有启用false,需要启动设置 true即可
* 意思是被引用的从表实体List中如果被delete了一条Java对象数据或者整个List直接被设置为null,
* 在更新或者删除操作时也会把相应的对象在数据库中删除(因为该对象在JPA中已经处于没有Entity状态了)
*
* @JoinColumn: 该注解一般常用属性就是如下三个
* name: 指定外键字段名称(从表数据库字段)。
* referencedColumnName: 指定主键字段名称(主表数据库字段)
* foreignKey: 外键策略, 这里设置不参加外键约束, 外键策略, 这里设置不参加外键约束。
* 注意: 该属性只有开启 ddl-auto 自动建表功能才有效
* 注意:
* 如果使用@OneToMany则:
* - JoinColumn.name: 【对方】实体的【数据库字段】
* - JoinColumn.referencedColumnName: 【己方】实体的【数据库字段】(如果是主键,可以省略)
* 如果使用@OneToOne、@ManyToOne则:
* - JoinColumn.name: 【己方】实体的【数据库字段】
* - JoinColumn.referencedColumnName: 【对方】实体的【数据库字段】(如果是主键,可以省略)
* 可以得出结论: 从数据库层面看,不管@JoinColumn配置在哪一方
* - JoinColumn.name: 主表数据库主键字段
* - JoinColumn.referencedColumnName: 从表数据库外键字段
*/
@OneToMany(targetEntity = UserInfo.class, cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private List<UserInfo> userInfos = new ArrayList<>();
}
public class UserInfo implements Serializable { // 用户信息类(从表),单向一对多从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
1、非级联操作测试(默认)
1、这里主要测试单向一对多的非级联新增、删除、更新。由于默认就是非级联操作,所以对应实体类就使用上面即可,测试代码如下:
@OneToMany
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 非级联添加: 首先保存userInfo, 然后把userInfo设置到中user, 再保存user
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void save() {
System.out.println("===========save()===========");
UserInfo userInfo = new UserInfo(1L, "CN");
userInfoRepository.saveAndFlush(userInfo);
User user = new User(1L, "DEV", Arrays.asList(userInfo));
userRepository.saveAndFlush(user);
}
/**
* 非级联更新测试: 没有什么好测试, 各种更新各自的即可。需要新增可以参考新增test
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void update() {
System.out.println("===========update()===========");
User user = userRepository.findById(1L).get();
user.setUsername("SAMS");
userRepository.saveAndFlush(user);
user.getUserInfos().get(0).setCountry("CNN");
userInfoRepository.saveAndFlush(user.getUserInfos().get(0));
}
/**
* 非级联删除: 只能先删除外键维护的表数据(并且会自动删除外键中间表数据), 然后才能删除userInfo非外键
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void delete() {
System.out.println("===========delete()===========");
// 先删除user主表信息的话, 会先更新userId为null断开与外键的联系才能删除
userRepository.deleteById(1L);
userInfoRepository.deleteAllById(Arrays.asList(1L));
}
}
2、日志打印如下:
save() 日志
===========save()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_info_id) values (?, ?) ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: update user_info set user_id=? where user_info_id=?update() 日志
===========update()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user set username=? where user_id=? ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=? where user_info_id=?delete() 日志
===========delete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: update user_info set user_id=null where user_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user_info where user_info_id=?
2、有级联操作测试
1、由于默认是不开启级联操作的,所以需要在实体类上手动设置打开级联操作。
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 保存user对象时,保存user对象必须设置中userInfo,才能级联新增和操作
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo userInfo = new UserInfo(1L, "CN");
// 级联操作可以省下此步骤: userInfoRepository.saveAndFlush(userInfo);
User user = new User(1L, "DEV", Arrays.asList(userInfo));
userRepository.saveAndFlush(user);
}
/**
* 级联更新: 需要把更新的userInfo设置到user对象中, 或者直接拿出来更改, 而后直接更新user即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
User user = userRepository.findById(1L).get();
user.setUsername("SAMS");
user.getUserInfos().get(0).setCountry("CNN");
userRepository.saveAndFlush(user);
}
/**
* 级联删除: 只需要使用user删除即可, 会级联把userInfo信息一起删除
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
userRepository.deleteById(1L);
}
}
2、日志打印
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: update user_info set user_id=? where user_info_id=?cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user set username=? where user_id=? Hibernate: update user_info set country=? where user_info_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: update user_info set user_id=null where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
3、延迟加载测试(默认)
1、由于一对多默认就是延迟加载,所以不需要增加任何配置,这里需要注意:处理新增数据使用了级联模式(所以实体类中要开启级联操作)
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 延迟加载查询需要加上@Transactional注解防止no session异常
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL
*/
@Test
@Order(2)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
System.out.println(user.getUserInfos().get(0).getCountry());
}
/**
* 延迟加载: 与上面同理
*/
@Test
@Order(3)
@Transactional
void lazyQueryAll() {
System.out.println("===========lazyQueryAll()===========");
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
System.out.println(users.get(0).getUserInfos().get(0).getCountry());
}
/**
* 级联添加: 保存user对象时,保存user对象必须设置中userInfo,才能级联新增和操作
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo userInfo = new UserInfo(1L, "CN");
// 级联操作可以省下此步骤: userInfoRepository.saveAndFlush(userInfo);
User user = new User(1L, "DEV", Arrays.asList(userInfo));
userRepository.saveAndFlush(user);
}
}
2、打印日志如下:
lazyQueryById() 日志
===========lazyQueryById()=========== Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? DEV Hibernate: select userinfos0_.user_id as user_id3_1_0_, userinfos0_.user_info_id as user_inf1_1_0_, userinfos0_.user_info_id as user_inf1_1_1_, userinfos0_.country as country2_1_1_ from user_info userinfos0_ where userinfos0_.user_id=? CNlazyQueryAll() 日志
===========lazyQueryAll()=========== Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ DEV Hibernate: select userinfos0_.user_id as user_id3_1_0_, userinfos0_.user_info_id as user_inf1_1_0_, userinfos0_.user_info_id as user_inf1_1_1_, userinfos0_.country as country2_1_1_ from user_info userinfos0_ where userinfos0_.user_id=? CN
4、立即加载测试(不推荐)
1、一对多一般也不建议设置立即加载,比较影响性能,这里只是为了测试,开启立即加载配置,处理新增数据使用了级联模式。
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 立即加载查询可以去除@Transactional注解
/**
* 立即加载: 可以发现第一次查询主实体类的同时, 就级联把关联对象集合查询出来了
*/
@Test
@Order(2)
void eagerQueryById() {
System.out.println("===========eagerQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
}
/**
* 立即加载: 与上面同理
*/
@Test
@Order(3)
void eagerQueryAll() {
System.out.println("===========eagerQueryAll()===========");
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
}
/**
* 级联添加: 保存user对象时,保存user对象必须设置中userInfo,才能级联新增和操作
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo userInfo = new UserInfo(1L, "CN");
// 级联操作可以省下此步骤: userInfoRepository.saveAndFlush(userInfo);
User user = new User(1L, "DEV", Arrays.asList(userInfo));
userRepository.saveAndFlush(user);
}
}
2、打印日志如下
eagerQueryById() 日志
===========eagerQueryById()=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfos1_.user_id as user_id3_1_1_, userinfos1_.user_info_id as user_inf1_1_1_, userinfos1_.user_info_id as user_inf1_1_2_, userinfos1_.country as country2_1_2_ from user user0_ left outer join user_info userinfos1_ on user0_.user_id=userinfos1_.user_id where user0_.user_id=? DEVeagerQueryAll() 日志
===========eagerQueryAll()=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ Hibernate: select userinfos0_.user_id as user_id3_1_0_, userinfos0_.user_info_id as user_inf1_1_0_, userinfos0_.user_info_id as user_inf1_1_1_, userinfos0_.country as country2_1_1_ from user_info userinfos0_ where userinfos0_.user_id=? DEV
5、OneToMany 扩展
1、OneToMany 单独使用(默认生成的外键字段名称为:属性名_主键名,OneToMany作为外键维护方时且单独使用会新建外键表)
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
@OneToMany(targetEntity = UserInfo.class)
private List<UserInfo> userInfos = new ArrayList<>();
}
public class UserInfo implements Serializable { // 用户信息类(从表),单向一对多从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
## User 类中的 UserInfo 属性名为 userInfoList,UserInfo 的主键 ID 为 user_info_id,那么生成的外键名称为:user_info_list_user_info_id
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), primary key (user_info_id))
Hibernate: create table user_user_infos (user_user_id bigint not null, user_infos_user_info_id bigint not null)
2、OneToMany + JoinColumn 组合使用
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
@OneToMany(targetEntity = UserInfo.class)
@JoinColumn(name = "user_info_user_id", referencedColumnName = "user_id")
private List<UserInfo> userInfos = new ArrayList<>();
}
public class UserInfo implements Serializable { // 用户信息类(从表),单向一对多从表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_info_user_id bigint, primary key (user_info_id))
Hibernate: alter table user_info add constraint FKl6agd5mgnj887dylrs1ghy3db foreign key (user_info_user_id) references
4、ManyToOne 源码分析
@ManyToOne 代表多对一,只能使用在从表类一方(外键拥有方),单向多对一关联使用@ManyToOne,如果双向关联则要与 @OneToMany 一起使用。
public @interface ManyToOne {
/**
* 指定另一方实体类字节码(常用), 该参数一般可以不指定,ORM-JPA会根据属性类型自动判断
*/
Class targetEntity() default void.class;
/**
* 级联操作: 如果不填,默认关系表不会产⽣任何影响。
* 级联更新: CascadeType.MERGE
* 级联保存: CascadeType.PERSIST
* 级联刷新: CascadeType.REFRESH
* 级联删除: CascadeType.REMOVE
* 级联脱管: CascadeType.DETACH
* 全部级联: CascadeType.ALL
*/
CascadeType[] cascade() default {};
/**
* 指定是否采用延迟加载,EAGER(⽴即加载)/LAZY(延迟加载). 默认为EAGER(⽴即加载)
* 注意:
* - OneToOne 和 ManyToOne 默认时LAZY(⽴即加载)
* - OneToMany 和 ManyToMany 默认时LAZY(延迟加载)
*/
FetchType fetch() default EAGER;
/**
* 关联是否可选。若为 false,则必须始终存在非空关系。
*/
boolean optional() default true;
}
5、ManyToOne 单向映射
单向多对一映射,先建立实体类关联关系,单向多对一只需要配置在多方的实体类即可,一方的实体类配置自己的字段即可。
public class User implements Serializable { // 用户类(主表),单向多对一主表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
/**
* @ManyToOne:
* targetEntity: 指定一的一方的类的字节码(即:主表实体类)(ORM会自动判断,所以可以不设置)
* cascade: 级联操作策略设置
* fetch: 数据加载方式, EAGER(⽴即加载)/LAZY(延迟加载), ManyToOne默认是EAGER(⽴即加载)
* optional: 关联是否可选。若为 false,则必须始终存在非空关系(保存更新该字段不能为空)
*
* @JoinColumn: 该注解一般常用属性就是如下三个
* name: 指定外键字段名称(从表数据库字段)。
* referencedColumnName: 指定主键字段名称(主表数据库字段)
* foreignKey: 外键策略, 这里设置不参加外键约束, 外键策略, 这里设置不参加外键约束。
* 注意: 该属性只有开启 ddl-auto 自动建表功能才有效
* 注意:
* 如果使用@OneToMany则:
* - JoinColumn.name: 【对方】实体的【数据库字段】
* - JoinColumn.referencedColumnName: 【己方】实体的【数据库字段】(如果是主键,可以省略)
* 如果使用@OneToOne、@ManyToOne则:
* - JoinColumn.name: 【己方】实体的【数据库字段】
* - JoinColumn.referencedColumnName: 【对方】实体的【数据库字段】(如果是主键,可以省略)
* 可以得出结论: 从数据库层面看,不管@JoinColumn配置在哪一方
* - JoinColumn.name: 主表数据库主键字段
* - JoinColumn.referencedColumnName: 从表数据库外键字段
*/
@ManyToOne(targetEntity = User.class, cascade = CascadeType.ALL, optional = false)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
1、非级联操作测试(默认)
1、这里主要测试单向多对一的非级联新增、删除、更新。由于默认就是非级联操作,所以无需配置,测试代码如下:
@ManyToOne
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 非级联添加: 必须先保存user, 再保存userInfo, 因为现在外键维护方是userInfo
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void save() {
System.out.println("===========save()===========");
User user = new User(1L, "DEV");
userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
/**
* 非级联更新测试: 没有什么好测试, 各种更新各自的即可。需要新增可以参考新增test
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void update() {
System.out.println("===========update()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setCountry("CNN");
userInfoRepository.saveAndFlush(userInfo);
userInfo.getUser().setUsername("SAMS");
userRepository.saveAndFlush(userInfo.getUser());
}
/**
* 非级联删除: 只能先删除外键维护的表数据(并且会自动删除外键中间表数据), 然后才能删除userInfo非外键
* 如果先删除user, JPA会先自动update userInfo把关联关系去掉, 然后删除user
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void delete() {
System.out.println("===========delete()===========");
// 建议先删除从表数据, 等从表中数据删完, 再删除主表中关联的数据
userInfoRepository.deleteById(1L);
userRepository.deleteById(1L);
}
}
2、日志打印如下:
save() 日志
===========save()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)update() 日志
===========update()=========== ## 更新前会先查询是否存在,省略了查询语句(此查询是一个关联查询) Hibernate: update user_info set country=?, user_id=? where user_info_id=? Hibernate: update user set username=? where user_id=?delete() 日志
===========delete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
2、有级联操作测试
1、由于默认是不开启级联操作的,所以需要在实体类上手动设置打开级联操作。
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
User user = new User(1L, "DEV");
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
/**
* 级联更新: 需要把更新的user设置到userInfo对象中, 或者直接拿出来更改, 而后直接更新userInfo即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setCountry("CNN");
userInfo.getUser().setUsername("SAMS");
userInfoRepository.saveAndFlush(userInfo);
// 级联操作可以省下此步骤: userRepository.saveAndFlush(userInfo.getUser());
}
/**
* 级联删除: 只需要使用userInfo删除即可, 会级联把user信息一起删除
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
// 建议先删除从表数据, 等从表中数据删完, 会自动删除主表中关联的数据
userInfoRepository.deleteById(1L);
}
}
2、日志打印
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=?, user_id=? where user_info_id=? Hibernate: update user set username=? where user_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
3、延迟加载测试(推荐)
1、由于多对一默认就是立即加载,我们需要手动设置为延迟加载
@ManyToOne(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 延迟加载查询需要加上@Transactional注解防止no session异常
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL
*/
@Test
@Order(2)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
System.out.println(userInfo.getUser().getUsername());
}
/**
* 延迟加载: 与上面同理
*/
@Test
@Order(3)
@Transactional
void lazyQueryAll() {
System.out.println("===========lazyQueryAll()===========");
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
System.out.println(userInfos.get(0).getUser().getUsername());
}
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
User user = new User(1L, "DEV");
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
}
2、打印日志如下:
lazyQueryById() 日志
===========lazyQueryById()=========== ## 可以发现使用到user就查询user的SQL, 使用到userInfo就查userInfo的SQL Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_ from user_info userinfo0_ where userinfo0_.user_info_id=? CN Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? DEVlazyQueryAll() 日志
===========lazyQueryAll()=========== ## 同上, 使用到关联对象才会去查询SQL Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ CN Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? DEV
4、立即加载测试(默认)
1、由于多对一默认就是立即加载,所以不需要增加任何配置,这里需要注意:如下测试代码初始新增使用了级联模式(所以实体类中要开启级联操作)
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 立即加载查询可以去除@Transactional注解
/**
* 立即加载: 可以发现查询SQL是关联查询, 一次查询出所有数据.(包括关联表的)
*/
@Test
@Order(2)
void eagerQueryById() {
System.out.println("===========eagerQueryById()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
System.out.println(userInfo.getUser().getUsername());
}
/**
* 立即加载: 与上面同理
*/
@Test
@Order(3)
void eagerQueryAll() {
System.out.println("===========eagerQueryAll()===========");
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
System.out.println(userInfos.get(0).getUser().getUsername());
}
/**
* 级联添加: 保存userInfo对象时,必须要给userInfo设置user值才能级联新增user
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
User user = new User(1L, "DEV");
// 级联操作可以省下此步骤: userRepository.saveAndFlush(user);
UserInfo userInfo = new UserInfo(1L, "CN", user);
userInfoRepository.saveAndFlush(userInfo);
}
}
2、打印日志如下
eagerQueryById() 日志
===========eagerQueryById()=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_info_id=? CNeagerQueryAll() 日志
===========eagerQueryAll()=========== ## 可以发现只是查询了user对象, JPA发送了2条SQL. Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? CN
5、ManyToOne 扩展
1、ManyToOne 单独使用(默认生成的外键字段名称为:属性名_主键名)
public class User implements Serializable { // 用户类(主表),单向多对一主表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@ManyToOne(targetEntity = User.class)
private User user;
}
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_user_id bigint, primary key (user_info_id))
Hibernate: alter table user_info add constraint FKi1mjqtts0we8oomodkc0etsqp foreign key (user_user_id) references user (user_id)
2、ManyToOne + JoinColumn 组合使用(可以自定义外键字段名)
public class User implements Serializable { // 用户类(主表),单向多对一主表类基本没有改动
// ...省略基本属性,只关注关联属性或字段
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
@ManyToOne
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
Hibernate: create table user (user_id bigint not null, username varchar(255), primary key (user_id))
Hibernate: create table user_info (user_info_id bigint not null, country varchar(255), user_id bigint, primary key (user_info_id))
Hibernate: alter table user_info add constraint FKn8pl63y4abe7n0ls6topbqjh2 foreign key (user_id) references user (user_id)
6、OneToMany + ManyToOne 双向最佳实践
1、双向一对多或多对一实体类配置(是否需要级联以及懒加载看自己业务需求)
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
/**
* mappedBy: 放弃外键维护, 交给对方类维护
* cascade: 级联操作, 这里开启所有级联操作
* orphanRemoval: 开启孤儿删除, 一般搭配级联操作一起使用
* targetEntity 与 fetch 属性可以省略
* targetEntity: JPA会自动判断,所以可以不配置
* fetch: 为了性能一般都使用懒加载(特别是主表类), 默认就是懒加载, 所以可以不配置
*/
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private List<UserInfo> userInfos = new ArrayList<>();
}
public class UserInfo implements Serializable { // 用户信息类(从表)
// ...省略基本属性,只关注关联属性或字段
/**
* @ManyToOne:
* fetch: 默认就是立即加载, 为了性能一般都使用懒加载
* 注意: targetEntity, cascade 与 optional 属性一般可以不配置(当前案例开启级联操作)
* targetEntity: JPA会自动判断,所以可以不配置
* cascade: 级联操作, 一般双向一对多时, 多方不开启级联操作
* optional: 关联是否可选, 一般选择可选填 默认是可选true, 所以可以不配置
*
* @JoinColumn:
* name: 指定外键字段名称(从表数据库字段)。
* referencedColumnName: 指定对应主键字段名称(主表数据库字段)
*/
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
1、主类级联操作测试
1、实体类配置与测试代码如下
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private List<UserInfo> userInfos = new ArrayList<>();
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 想要从user主类方级联新增userInfo信息, 相对比较麻烦,
* 双向控制外键的设置已经交给了userInfo, 必须要在userInfo中包含user对象, 才能级联新增成功
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 由于设置了mapper外键交给从类维护, 所以外键一般由从类来插入, 如果想用userRepository保存到外键, 参考更新方法
User user1 = User.builder().userId(1L).username("Sam").build();
User user2 = User.builder().userId(2L).username("Tom").build();
userRepository.saveAllAndFlush(Arrays.asList(user1, user2));
// 在保存外键表时设置外键值即可
UserInfo userInfo1 = UserInfo.builder().userInfoId(1l).country("CN").user(user1).build();
UserInfo userInfo2 = UserInfo.builder().userInfoId(2l).country("EN").user(user1).build();
UserInfo userInfo3 = UserInfo.builder().userInfoId(3l).country("UK").user(user2).build();
UserInfo userInfo4 = UserInfo.builder().userInfoId(4l).country("DE").user(user2).build();
userInfoRepository.saveAll(Arrays.asList(userInfo1, userInfo2, userInfo3, userInfo4));
}
/**
* 级联更新: 需要把更新的userInfo设置到user对象中, 或者直接拿出来更改, 而后直接更新user即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
User user = userRepository.findById(1L).get();
user.setUsername("SAMS");
user.getUserInfos().get(0).setCountry("CNN");
// 新增如果userInfo没有给user设置值, 那么user_id外键字段将为null
user.getUserInfos().add(UserInfo.builder().userInfoId(5L).country("DK").user(user).build());
userRepository.saveAndFlush(user);
}
/**
* 级联删除: 只需要使用user删除即可, 会级联把userInfo信息一起删除
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
userRepository.deleteById(1L);
}
}
2、日志打印
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: update user set username=? where user_id=? Hibernate: update user_info set country=?, user_id=? where user_info_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
2、从类级联操作测试
1、实体类配置与测试代码如下
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 想要从user主类方级联新增userInfo信息, 相对比较麻烦,
* 双向控制外键的设置已经交给了userInfo, 必须要在userInfo中包含user对象, 才能级联新增成功
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 由于设置了mapper外键交给从类维护, 所以外键一般由从类来插入, 如果想用userRepository保存到外键, 参考更新方法
User user1 = User.builder().userId(1L).username("Sam").build();
User user2 = User.builder().userId(2L).username("Tom").build();
// 从类开启级联操作可以省略此代码: userRepository.saveAllAndFlush(Arrays.asList(user1, user2));
// 在保存外键表时设置外键值即可
UserInfo userInfo1 = UserInfo.builder().userInfoId(1l).country("CN").user(user1).build();
UserInfo userInfo2 = UserInfo.builder().userInfoId(2l).country("EN").user(user1).build();
UserInfo userInfo3 = UserInfo.builder().userInfoId(3l).country("UK").user(user2).build();
UserInfo userInfo4 = UserInfo.builder().userInfoId(4l).country("DE").user(user2).build();
userInfoRepository.saveAll(Arrays.asList(userInfo1, userInfo2, userInfo3, userInfo4));
}
/**
* 级联更新: 需要把更新的userInfo设置到user对象中, 或者直接拿出来更改, 而后直接更新user即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setCountry("CNN");
userInfo.getUser().setUsername("SAMS");
userInfoRepository.saveAndFlush(userInfo);
}
/**
* 级联删除: 在从类中级联删除时需要注意, 虽然只是删除userInfo为1的数据,
* 当时已经会级联删除到对应主键为1的user数据删除, 由于user也开启了级联操作,
* 在user中又会来一次级联删除, 然后把user表关联外键表中的数据全部删除
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
userInfoRepository.deleteById(1L);
userInfoRepository.deleteById(3L);
}
}
2、日志打印如下:
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=?, user_id=? where user_info_id=? Hibernate: update user set username=? where user_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
3、延迟加载测试
1、开启双向级联操作,并且从类配置懒加载模式,主类默认就是懒加载模式。
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private List<UserInfo> userInfos = new ArrayList<>();
@ManyToOne(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 延迟加载查询需要加上@Transactional注解防止no session异常
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL
*/
@Test
@Order(2)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
System.out.println("===========分割线===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
}
/**
* 延迟加载: 与上面同理
*/
@Test
@Order(3)
@Transactional
void lazyQueryAll() {
System.out.println("===========lazyQueryAll()===========");
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
System.out.println("===========分割线===========");
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
}
/**
* 级联添加: 想要从user主类方级联新增userInfo信息, 相对比较麻烦,
* 双向控制外键的设置已经交给了userInfo, 必须要在userInfo中包含user对象, 才能级联新增成功
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 由于设置了mapper外键交给从类维护, 所以外键一般由从类来插入, 如果想用userRepository保存到外键, 参考更新方法
User user1 = User.builder().userId(1L).username("Sam").build();
User user2 = User.builder().userId(2L).username("Tom").build();
// 从类开启级联操作可以省略此代码: userRepository.saveAllAndFlush(Arrays.asList(user1, user2));
// 在保存外键表时设置外键值即可
UserInfo userInfo1 = UserInfo.builder().userInfoId(1l).country("CN").user(user1).build();
UserInfo userInfo2 = UserInfo.builder().userInfoId(2l).country("EN").user(user1).build();
UserInfo userInfo3 = UserInfo.builder().userInfoId(3l).country("UK").user(user2).build();
UserInfo userInfo4 = UserInfo.builder().userInfoId(4l).country("DE").user(user2).build();
userInfoRepository.saveAll(Arrays.asList(userInfo1, userInfo2, userInfo3, userInfo4));
}
}
2、打印日志如下:
lazyQueryById() 日志
===========lazyQueryById()=========== Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? Sam ===========分割线=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_ from user_info userinfo0_ where userinfo0_.user_info_id=? CNlazyQueryAll() 日志
===========lazyQueryAll()=========== Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ Sam ===========分割线=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ CN
4、立即加载测试
1、开启双向级联操作,并且主类配置立即加载模式,从类默认就是立即加载模式。
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.EAGER)
private List<UserInfo> userInfos = new ArrayList<>();
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 立即加载查询可以去除@Transactional注解
/**
* 立即加载: 可以发现第一次查询主实体类的同时, 就级联把关联对象集合查询出来了
*/
@Test
@Order(2)
void eagerQueryById() {
System.out.println("===========eagerQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
System.out.println("===========分割线===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
}
/**
* 立即加载: 与上面同理
*/
@Test
@Order(3)
void eagerQueryAll() {
System.out.println("===========eagerQueryAll()===========");
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
System.out.println("===========分割线===========");
List<UserInfo> userInfos = userInfoRepository.findAll();
System.out.println(userInfos.get(0).getCountry());
}
/**
* 级联添加: 想要从user主类方级联新增userInfo信息, 相对比较麻烦,
* 双向控制外键的设置已经交给了userInfo, 必须要在userInfo中包含user对象, 才能级联新增成功
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 由于设置了mapper外键交给从类维护, 所以外键一般由从类来插入, 如果想用userRepository保存到外键, 参考更新方法
User user1 = User.builder().userId(1L).username("Sam").build();
User user2 = User.builder().userId(2L).username("Tom").build();
// 从类开启级联操作可以省略此代码: userRepository.saveAllAndFlush(Arrays.asList(user1, user2));
// 在保存外键表时设置外键值即可
UserInfo userInfo1 = UserInfo.builder().userInfoId(1l).country("CN").user(user1).build();
UserInfo userInfo2 = UserInfo.builder().userInfoId(2l).country("EN").user(user1).build();
UserInfo userInfo3 = UserInfo.builder().userInfoId(3l).country("UK").user(user2).build();
UserInfo userInfo4 = UserInfo.builder().userInfoId(4l).country("DE").user(user2).build();
userInfoRepository.saveAll(Arrays.asList(userInfo1, userInfo2, userInfo3, userInfo4));
}
}
2、打印日志如下
eagerQueryById() 日志
===========eagerQueryById()=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfos1_.user_id as user_id3_1_1_, userinfos1_.user_info_id as user_inf1_1_1_, userinfos1_.user_info_id as user_inf1_1_2_, userinfos1_.country as country2_1_2_, userinfos1_.user_id as user_id3_1_2_ from user user0_ left outer join user_info userinfos1_ on user0_.user_id=userinfos1_.user_id where user0_.user_id=? Sam ===========分割线=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, userinfo0_.user_id as user_id3_1_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_info userinfo0_ left outer join user user1_ on userinfo0_.user_id=user1_.user_id where userinfo0_.user_info_id=? Hibernate: select userinfos0_.user_id as user_id3_1_0_, userinfos0_.user_info_id as user_inf1_1_0_, userinfos0_.user_info_id as user_inf1_1_1_, userinfos0_.country as country2_1_1_, userinfos0_.user_id as user_id3_1_1_ from user_info userinfos0_ where userinfos0_.user_id=? CNeagerQueryAll() 日志
===========eagerQueryAll()=========== ## 虽然看到时一条关联SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ Hibernate: select userinfos0_.user_id as user_id3_1_0_, userinfos0_.user_info_id as user_inf1_1_0_, userinfos0_.user_info_id as user_inf1_1_1_, userinfos0_.country as country2_1_1_, userinfos0_.user_id as user_id3_1_1_ from user_info userinfos0_ where userinfos0_.user_id=? Hibernate: select userinfos0_.user_id as user_id3_1_0_, userinfos0_.user_info_id as user_inf1_1_0_, userinfos0_.user_info_id as user_inf1_1_1_, userinfos0_.country as country2_1_1_, userinfos0_.user_id as user_id3_1_1_ from user_info userinfos0_ where userinfos0_.user_id=? Sam ===========分割线=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_, userinfo0_.user_id as user_id3_1_ from user_info userinfo0_ Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfos1_.user_id as user_id3_1_1_, userinfos1_.user_info_id as user_inf1_1_1_, userinfos1_.user_info_id as user_inf1_1_2_, userinfos1_.country as country2_1_2_, userinfos1_.user_id as user_id3_1_2_ from user user0_ left outer join user_info userinfos1_ on user0_.user_id=userinfos1_.user_id where user0_.user_id=? Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfos1_.user_id as user_id3_1_1_, userinfos1_.user_info_id as user_inf1_1_1_, userinfos1_.user_info_id as user_inf1_1_2_, userinfos1_.country as country2_1_2_, userinfos1_.user_id as user_id3_1_2_ from user user0_ left outer join user_info userinfos1_ on user0_.user_id=userinfos1_.user_id where user0_.user_id=? CN
5、从类增加外键字段
1、很多情况下,暂时不想每次外键字段都去查询类,我只想要一个字段,并且还想使用上咱们的级联操作,那么我们可以搭配使用:既使用字段,又使用关联引用类。实体类代码如下(本次案例使用 主从实体类都使用级联操作、延迟加载):
// 主类
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private List<UserInfo> userInfos = new ArrayList<>();
// 从类
// 虽然已经定义关联属性引用类, 为了方便这里还特意了一个外键属性字段, 值必须与JoinColumn.name一致
@Column(name = "user_id")
private Long userId;
@ManyToOne(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", referencedColumnName = "user_id", insertable = false, updatable = false)
private User user;
注意:同时使用外键属性字段 + 外键引用类型字段时,需要在@JoinColumn增加
insertable = false, updatable = false
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 由于设置了mapper外键交给从类维护, 所以外键一般由从类来插入, 如果想用userRepository保存到外键, 参考更新方法
User user1 = User.builder().userId(1L).username("Sam").build();
User user2 = User.builder().userId(2L).username("Tom").build();
userRepository.saveAllAndFlush(Arrays.asList(user1, user2));
// 在保存外键表时设置外键值即可(如果想单独使用丛类级联新增的话,需要同时给userId和user属性都设置值才行, 否则外键会为null)
UserInfo userInfo1 = UserInfo.builder().userInfoId(1l).country("CN").userId(1L).build();
UserInfo userInfo2 = UserInfo.builder().userInfoId(2l).country("EN").userId(1L).build();
UserInfo userInfo3 = UserInfo.builder().userInfoId(3l).country("UK").userId(2L).build();
UserInfo userInfo4 = UserInfo.builder().userInfoId(4l).country("DE").userId(2L).build();
userInfoRepository.saveAll(Arrays.asList(userInfo1, userInfo2, userInfo3, userInfo4));
}
/**
* 级联更新: 修改关联关系只需要修改外键字段即可.
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
UserInfo userInfo = userInfoRepository.findById(3L).get();
userInfo.setUserId(1L);
userInfoRepository.saveAndFlush(userInfo);
}
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL
* 延迟加载查询需要加上@Transactional注解防止no session异常
*/
@Test
@Order(3)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUserInfos().size());
System.out.println("===========分割线===========");
UserInfo userInfo = userInfoRepository.findById(1L).get();
System.out.println(userInfo.getCountry());
}
/**
* 级联删除: 只需要使用user删除即可, 会级联把userInfo信息一起删除
*/
@Test
@Order(4)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
userRepository.deleteById(1L);
userRepository.deleteById(2L);
}
}
2、日志打印:
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?) Hibernate: insert into user_info (country, user_id, user_info_id) values (?, ?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=?, user_id=? where user_info_id=?lazyQueryById() 日志
===========lazyQueryById()=========== Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? Hibernate: select userinfos0_.user_id as user_id3_1_0_, userinfos0_.user_info_id as user_inf1_1_0_, userinfos0_.user_info_id as user_inf1_1_1_, userinfos0_.country as country2_1_1_, userinfos0_.user_id as user_id3_1_1_ from user_info userinfos0_ where userinfos0_.user_id=? 3 ===========分割线=========== CNcascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
4、ManyToMany 多对多关系映射
1、表结构与实体类初始化
1、表结构和需求(实际上表结构需求都基本一样,就是外键表数据变成了多条)
-- 需求: 用户表与用户扩展信息表(主要存国家)是多对多的关联关系,一个用户可以有国家,一个国家也可以被多个用户所拥有.
-- 用户表-user (主键表): 多方
-- 用户信息扩展表-user_info (主键表): 多方
-- 用户与用户扩展信息中间表-user_user_info (外键中间表)
-- 用户表结构
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| user_id | bigint | NO | PRI | NULL | |
| username | varchar(255) | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+
-- 用户扩展信息表结构
+--------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+-------+
| user_info_id | bigint | NO | PRI | NULL | |
| country | varchar(255) | YES | | NULL | |
+--------------+--------------+------+-----+---------+-------+
-- 用户与用户扩展信息外键中间表结构
+--------------+--------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------+------+-----+---------+-------+
| user_id | bigint | NO | MUL | NULL | |
| user_info_id | bigint | NO | MUL | NULL | |
+--------------+--------+------+-----+---------+-------+
2、创建2个实体类对应的Repository接口
// 用户类对应repository接口
public interface UserRepository extends JpaRepository<User, Long> {
}
// 用户信息类对应repository接口
public interface UserInfoRepository extends JpaRepository<UserInfo, Long> {
}
3、先建两个实体类:User 和 UserInfo,暂未建立关联关系,讲解特定注解时补充。
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "user")
public class User {
@Id
@Column(name = "user_id")
private Long userId;
@Column(name = "username")
private String username;
}
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "user_info")
public class UserInfo {
@Id
@Column(name = "user_info_id")
private Long userInfoId;
@Column(name = "country")
private String country;
}
后续代码将会对下面这部分共同代码略写。
2、ManyToMany 源码分析
public @interface ManyToMany {
/**
* 指定另一方实体类字节码(常用), 该参数一般可以不指定,ORM-JPA会根据属性类型自动判断
*/
Class targetEntity() default void.class;
/**
* 级联操作: 如果不填,默认关系表不会产⽣任何影响。
* 级联更新: CascadeType.MERGE
* 级联保存: CascadeType.PERSIST
* 级联刷新: CascadeType.REFRESH
* 级联删除: CascadeType.REMOVE
* 级联脱管: CascadeType.DETACH
* 全部级联: CascadeType.ALL
*/
CascadeType[] cascade() default {};
/**
* 指定是否采用延迟加载,EAGER(⽴即加载)/LAZY(延迟加载). 默认为LAZY(延迟加载)
* 注意:
* - OneToOne 和 ManyToOne 默认时LAZY(⽴即加载)
* - OneToMany 和 ManyToMany 默认时LAZY(延迟加载)
*/
FetchType fetch() default LAZY;
/**
* 指定关系被谁维护,单项的。注意:只有关系维护方才能操作两者的关系。双向关联实体时使用(常用)
*/
String mappedBy() default "";
}
3、ManyToMany 单向映射
单向多对多映射,先建立实体类关联关系,单向映射只需要配置一方实体类即可,另一方配置自己的字段即可。(反过来也一样,在另一类这样配置即可)
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
/**
* 配置多对多的映射关系 (用户到用户信息扩展的多对多关系)
* 1.声明表关系的配置
* @ManyToMany(targetEntity = UserInfo.class, cascade = CascadeType.ALL)
* targetEntity : 代表对方的实体类字节码 (默认可以不配置)
* cascade : 级联操作设置
* 2.配置中间表(包含两个外键)
* @JoinTable
* name : 中间表的名称
* joinColumns:配置当前对象在中间表的外键
* @JoinColumn的数组
* name:外键名
* referencedColumnName:参照的主表的主键名
* inverseJoinColumns:配置对方对象在中间表的外键
* @JoinColumn的数组
* name:外键名
* referencedColumnName:参照的主表的主键名
*/
@ManyToMany(targetEntity = UserInfo.class)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
}
public class UserInfo implements Serializable { // 用户信息类(主表)
// ...省略基本属性,只关注关联属性或字段
}
如果开启DDL-AUTO的话,可以看到建表SQL打印:
Hibernate: create table user ( user_id bigint not null, username varchar(255), primary key (user_id) ) engine=InnoD Hibernate: create table user_info ( user_info_id bigint not null, country varchar(255), primary key (user_info_id) ) engine=InnoDB Hibernate: create table user_user_info ( user_id bigint not null, user_info_id bigint not null ) engine=InnoDB Hibernate: alter table user_user_info add constraint FK8n5dd87vnb5fyr9omvodwe1ik foreign key (user_info_id) references user_info (user_info_id) Hibernate: alter table user_user_info add constraint FK13222lltg7n1yd0xdyyy26p73 foreign key (user_id) references user (user_id)
1、非级联操作测试(默认)
1、这里主要测试单向关联的非级联新增、删除、更新。由于默认就是非级联操作,所以对应实体类就使用上面即可,测试代码如下:
@ManyToMany
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 非级联添加: 首先保存userInfo, 然后把userInfo设置到中user, 再保存user
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void save() {
System.out.println("===========save()===========");
UserInfo cn = new UserInfo(1L, "CN");
UserInfo en = new UserInfo(2L, "EN");
UserInfo uk = new UserInfo(3L, "UK");
userInfoRepository.saveAll(Arrays.asList(cn, en, uk));
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
/**
* 非级联更新测试: 没有什么好测试, 各种更新各自的即可。需要新增可以参考新增test
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void update() {
System.out.println("===========update()===========");
User user = userRepository.findById(1L).get();
user.setUsername("SAMS");
userRepository.saveAndFlush(user);
user.getUserInfos().get(0).setCountry("CNN");
userInfoRepository.saveAndFlush(user.getUserInfos().get(0));
}
/**
* 非级联删除: 只能先删除外键维护的表数据(并且会自动删除外键中间表数据), 然后才能删除userInfo非外键
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void delete() {
System.out.println("===========delete()===========");
userRepository.deleteAllById(Arrays.asList(1L, 2L));
userInfoRepository.deleteAllById(Arrays.asList(1L, 2L, 3L));
}
}
2、日志打印如下:
save() 日志
===========save()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?)update() 日志
===========update()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user set username=? where user_id=? ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=? where user_info_id=?delete() 日志
===========delete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=?
2、有级联操作测试
1、由于默认是不开启级联操作的,所以需要在实体类上手动设置打开级联操作。
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 在保存user对象时, 如果设置了userInfo值, 则会级联新增
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo cn = new UserInfo(1L, "CN");
UserInfo en = new UserInfo(2L, "EN");
UserInfo uk = new UserInfo(3L, "UK");
// 级联操作可以省下此步骤: userInfoRepository.saveAll(Arrays.asList(cn, en, uk));
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
/**
* 级联更新: 需要把更新的userInfo设置到user对象中, 或者直接拿出来更改, 而后直接更新user即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
User user = userRepository.findById(1L).get();
user.setUsername("SAMM");
user.getUserInfos().get(0).setCountry("CNN");
userRepository.saveAndFlush(user);
}
/**
* 级联删除: 只需要使用user删除即可, 会级联把userInfo信息一起删除
*/
@Test
@Order(3)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
userRepository.deleteAllById(Arrays.asList(1L, 2L));
}
}
2、日志打印
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user set username=? where user_id=? Hibernate: update user_info set country=? where user_info_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
3、延迟加载测试(默认)
1、由于多对多默认就是延迟加载,所以不需要增加任何配置,这里需要注意:如下测试代码初始新增使用了级联模式(所以实体类中要开启级联操作)
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 延迟加载查询需要加上@Transactional注解防止no session异常
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL
*/
@Test
@Order(2)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
System.out.println(user.getUserInfos().get(0).getCountry());
}
/**
* 延迟加载: 与上面同理
*/
@Test
@Order(3)
@Transactional
void lazyQueryAll() {
System.out.println("===========lazyQueryAll()===========");
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
System.out.println(users.get(0).getUserInfos().get(0).getCountry());
}
/**
* 级联添加: 保存user对象时,保存user对象必须设置中userInfo,才能级联新增和操作
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo cn = new UserInfo(1L, "CN");
UserInfo en = new UserInfo(2L, "EN");
UserInfo uk = new UserInfo(3L, "UK");
// 级联操作可以省下此步骤: userInfoRepository.saveAll(Arrays.asList(cn, en, uk));
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
}
2、打印日志如下:
lazyQueryById() 日志
===========lazyQueryById()=========== Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? SAM Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? CNlazyQueryAll() 日志
===========lazyQueryAll()=========== Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ SAM Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? CN
4、立即加载测试(不推荐)
1、多对多一般也不建议设置立即加载,比较影响性能,这里只是为了测试,开启立即加载配置,处理新增数据使用了级联模式。
@ManyToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 立即加载查询可以去除@Transactional注解
/**
* 立即加载: 可以发现第一次查询主实体类的同时, 就级联把关联对象集合查询出来了
*/
@Test
@Order(2)
void eagerQueryById() {
System.out.println("===========eagerQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
}
/**
* 立即加载: 与上面同理
*/
@Test
@Order(3)
void eagerQueryAll() {
System.out.println("===========eagerQueryAll()===========");
List<User> users = userRepository.findAll();
System.out.println(users.get(0).getUsername());
}
/**
* 级联添加: 保存user对象时,保存user对象必须设置中userInfo,才能级联新增和操作
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo cn = new UserInfo(1L, "CN");
UserInfo en = new UserInfo(2L, "EN");
UserInfo uk = new UserInfo(3L, "UK");
// 级联操作可以省下此步骤: userInfoRepository.saveAll(Arrays.asList(cn, en, uk));
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
}
2、打印日志如下
eagerQueryById() 日志
===========eagerQueryById()=========== ## 虽然看到时一条SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfos1_.user_id as user_id1_2_1_, userinfo2_.user_info_id as user_inf2_2_1_, userinfo2_.user_info_id as user_inf1_1_2_, userinfo2_.country as country2_1_2_ from user user0_ left outer join user_user_info userinfos1_ on user0_.user_id=userinfos1_.user_id left outer join user_info userinfo2_ on userinfos1_.user_info_id=userinfo2_.user_info_id where user0_.user_id=? SAMeagerQueryAll() 日志
===========eagerQueryAll()=========== ## 虽然看到时一条SQL, 可是JPA会把它映射到关联类集合中 Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? SAM
4、ManyToMany 双向映射
双向多对多映射时跟单向多对多基本差不多,只需要在另一方类中配置@ManyToMany即可,注意还需要配置mappedBy属性(双向映射必配)
public class User implements Serializable { // 用户类(主表)
// ...省略基本属性,只关注关联属性或字段
/**
* 配置多对多的映射关系 (用户到用户信息扩展的多对多关系)
* 1.声明表关系的配置
* @ManyToMany(targetEntity = UserInfo.class, cascade = CascadeType.ALL)
* targetEntity : 代表对方的实体类字节码 (默认可以不配置)
* cascade : 级联操作设置
* 2.配置中间表(包含两个外键)
* @JoinTable
* name : 中间表的名称
* joinColumns:配置当前对象在中间表的外键
* @JoinColumn的数组
* name:外键名
* referencedColumnName:参照的主表的主键名
* inverseJoinColumns:配置对方对象在中间表的外键
* @JoinColumn的数组
* name:外键名
* referencedColumnName:参照的主表的主键名
*/
@ManyToMany(targetEntity = UserInfo.class)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
}
@ToString(exclude = "user")
public class UserInfo implements Serializable { // 用户信息类(主表)
// ...省略基本属性,只关注关联属性或字段
/**
* @ManyToMany
* targetEntity :配置目标的实体类。映射多对多的时候不用写
* mappedBy :放弃维护外键,值为另一方(拥有方)引用本类的属性名
* fetch :指定是懒加载还是立即加载(默认是懒加载)
*/
@ManyToMany(mappedBy = "userInfos", targetEntity = User.class)
private List<User> user = new ArrayList<>();
}
1、非级联操作测试(默认)
1、这里主要测试双向关联的非级联新增、删除、更新。由于默认就是非级联操作,所以对应实体类就使用上面即可,测试代码如下:
@ManyToMany
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
@ManyToMany(mappedBy = "userInfos")
private List<User> user = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 非级联添加: 首先保存userInfo, 然后把userInfo设置到中user, 再保存user
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void save() {
System.out.println("===========save()===========");
UserInfo cn = new UserInfo(1L, "CN", null);
UserInfo en = new UserInfo(2L, "EN", null);
UserInfo uk = new UserInfo(3L, "UK", null);
userInfoRepository.saveAll(Arrays.asList(cn, en, uk));
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
/**
* 非级联更新测试: 没有什么好测试, 各种更新各自的即可。需要新增可以参考新增test
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void update() {
System.out.println("===========update()===========");
User user = userRepository.findById(1L).get();
user.setUsername("SAMS");
userRepository.saveAndFlush(user);
user.getUserInfos().get(0).setCountry("CNN");
userInfoRepository.saveAndFlush(user.getUserInfos().get(0));
}
/**
* 非级联删除: 只能先删除外键维护的表数据(并且会自动删除外键中间表数据), 然后才能删除userInfo非外键
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void delete() {
System.out.println("===========delete()===========");
userRepository.deleteAllById(Arrays.asList(1L, 2L));
userInfoRepository.deleteAllById(Arrays.asList(1L, 2L, 3L));
}
}
2、日志打印如下:
save() 日志
===========save()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?)update() 日志
===========update()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user set username=? where user_id=? ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user_info set country=? where user_info_id=?delete() 日志
===========delete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=?
2、有级联操作测试
1、由于默认是不开启级联操作的,所以需要在实体类上手动设置打开级联操作。如下是双向级联操作代码(一般只会开启主表类的级联操作):
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
@ManyToMany(mappedBy = "userInfos")
private List<User> user = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=false"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
/**
* 级联添加: 在保存user对象时, 如果设置了userInfo值, 则会级联新增
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo cn = new UserInfo(1L, "CN", null);
UserInfo en = new UserInfo(2L, "EN", null);
UserInfo uk = new UserInfo(3L, "UK", null);
// 级联操作可以省下此步骤: userInfoRepository.saveAll(Arrays.asList(cn, en, uk));
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
/**
* 级联更新: 需要把更新的userInfo设置到user对象中, 或者直接拿出来更改, 而后直接更新user即可
*/
@Test
@Order(2)
@Rollback(false)
@Transactional
void cascadeUpdate() {
System.out.println("===========cascadeUpdate()===========");
User user = userRepository.findById(1L).get();
user.setUsername("SAMS");
user.getUserInfos().get(0).setCountry("CNN");
userRepository.saveAndFlush(user);
}
/**
* 级联删除: 直接从user对象(外键控制方)删除即可级联删除userinfo了
*/
@Test
@Order(3)
@Rollback(false)
@Transactional
void cascadeDelete() {
System.out.println("===========cascadeDelete()===========");
userRepository.deleteAllById(Arrays.asList(1L, 2L));
}
}
2、打印日志如下:
cascadeSave() 日志
===========cascadeSave()=========== ## 新增前会先查询是否存在,省略了查询语句 Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user (username, user_id) values (?, ?) Hibernate: insert into user_info (country, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?) Hibernate: insert into user_user_info (user_id, user_info_id) values (?, ?)cascadeUpdate() 日志
===========cascadeUpdate()=========== ## 更新前会先查询是否存在,省略了查询语句 Hibernate: update user set username=? where user_id=? Hibernate: update user_info set country=? where user_info_id=?cascadeDelete() 日志
===========cascadeDelete()=========== ## 删除前会先查询是否存在,省略了查询语句 Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user_user_info where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=? Hibernate: delete from user_info where user_info_id=? Hibernate: delete from user where user_id=?
3、延迟加载测试(默认)
1、由于多对多默认就是延迟加载,所以不需要增加任何配置,这里需要注意:如下测试代码初始新增使用了级联模式(所以实体类中要开启级联操作)
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
// @ToString(exclude = "user") 需要在方法上加上当前配置, 避免toString打印循环引用导致死循环
@ManyToMany(mappedBy = "userInfos")
private List<User> user = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 延迟加载查询需要加上@Transactional注解防止no session异常
/**
* 延迟加载: 可以发现在使用到子类关联对象时才会发送级联SQL
*/
@Test
@Order(2)
@Transactional
void lazyQueryById() {
System.out.println("===========lazyQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
System.out.println("===========分割线===========");
UserInfo userInfo = userInfoRepository.findById(3L).get();
System.out.println(userInfo.getUser().get(0).getUsername());
}
/**
* 级联添加: 保存user对象时,保存user对象必须设置中userInfo,才能级联新增和操作
*/
@Test
@Order(3)
@Transactional
void lazyQueryAll() {
System.out.println("===========lazyQueryAll()===========");
System.out.println(userRepository.findAll().get(0).getUsername());
System.out.println("===========分割线===========");
System.out.println(userInfoRepository.findAll().get(0).getUser().get(0).getUsername());
}
/**
* 级联添加: 只需要在新增时把userInfo设置到user中即可, 在保存user时会自动级联保存userInfo和外键信息
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo cn = new UserInfo(1L, "CN", null);
UserInfo en = new UserInfo(2L, "EN", null);
UserInfo uk = new UserInfo(3L, "UK", null);
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
}
2、打印日志如下:
lazyQueryById() 日志
===========lazyQueryById()=========== Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_ from user user0_ where user0_.user_id=? SAM ===========分割线=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_ from user_info userinfo0_ where userinfo0_.user_info_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? TOMlazyQueryAll() 日志
===========lazyQueryAll()=========== Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ SAM ===========分割线=========== Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_ from user_info userinfo0_ Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? SAM
4、立即加载测试(不推荐)
1、多对多一般也不建议设置立即加载,比较影响性能,这里只是为了测试,开启立即加载配置,处理新增数据依旧使用了级联模式。
@ManyToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinTable(name = "user_user_info",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "user_id"),
inverseJoinColumns = @JoinColumn(name = "user_info_id", referencedColumnName = "user_info_id"))
private List<UserInfo> userInfos = new ArrayList<>();
// @ToString(exclude = "user") 需要在方法上加上当前配置, 避免toString打印循环引用导致死循环
@ManyToMany(mappedBy = "userInfos", fetch = FetchType.EAGER)
private List<User> user = new ArrayList<>();
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
// 立即加载查询可以去除@Transactional注解
/**
* 立即加载: 可以发现第一次查询主实体类的同时, 就级联把关联对象集合查询出来了
*/
@Test
@Order(2)
void eagerQueryById() {
System.out.println("===========eagerQueryById()===========");
User user = userRepository.findById(1L).get();
System.out.println(user.getUsername());
System.out.println("===========分割线===========");
UserInfo userInfo = userInfoRepository.findById(3L).get();
System.out.println(userInfo.getCountry());
}
@Test
@Order(3)
void eagerQueryAll() {
System.out.println("===========eagerQueryAll()===========");
System.out.println(userRepository.findAll().get(0).getUsername());
System.out.println("===========分割线===========");
System.out.println(userInfoRepository.findAll().get(0).getCountry());
}
/**
* 级联添加: 只需要在新增时把userInfo设置到user中即可, 在保存user时会自动级联保存userInfo和外键信息
*/
@Test
@Order(1)
@Rollback(false) // 不自动回滚
@Transactional // 配置事务
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
UserInfo cn = new UserInfo(1L, "CN", null);
UserInfo en = new UserInfo(2L, "EN", null);
UserInfo uk = new UserInfo(3L, "UK", null);
// user保存后中间表(user_user_info)有4条数据
User sam = new User(1L, "SAM", Arrays.asList(cn, en));
User tom = new User(2L, "TOM", Arrays.asList(uk, en));
userRepository.saveAll(Arrays.asList(sam, tom));
}
}
2、打印日志如下:
eagerQueryById() 日志
===========eagerQueryById()=========== ## 第一次先查主表信息 Hibernate: select user0_.user_id as user_id1_0_0_, user0_.username as username2_0_0_, userinfos1_.user_id as user_id1_2_1_, userinfo2_.user_info_id as user_inf2_2_1_, userinfo2_.user_info_id as user_inf1_1_2_, userinfo2_.country as country2_1_2_ from user user0_ left outer join user_user_info userinfos1_ on user0_.user_id=userinfos1_.user_id left outer join user_info userinfo2_ on userinfos1_.user_info_id=userinfo2_.user_info_id where user0_.user_id=? ## 后面4条SQL是通过主表查到的外键去查外键表信息 Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? SAM ===========分割线=========== ## 第一次先查主表信息 Hibernate: select userinfo0_.user_info_id as user_inf1_1_0_, userinfo0_.country as country2_1_0_, user1_.user_info_id as user_inf2_2_1_, user2_.user_id as user_id1_2_1_, user2_.user_id as user_id1_0_2_, user2_.username as username2_0_2_ from user_info userinfo0_ left outer join user_user_info user1_ on userinfo0_.user_info_id=user1_.user_info_id left outer join user user2_ on user1_.user_id=user2_.user_id where userinfo0_.user_info_id=? ## 后面4条SQL是通过主表查到的外键去查外键表信息 Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? UKeagerQueryAll() 日志
===========eagerQueryAll()=========== ## 第一条SQL查询主实体类信息,包含了子实体类集合 Hibernate: select user0_.user_id as user_id1_0_, user0_.username as username2_0_ from user user0_ ## 后面的SQL都是通过查到的外键一条一条SQL查子实体类信息 Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? SAM ===========分割线=========== ## 第一条SQL查询主实体类信息,包含了子实体类集合 Hibernate: select userinfo0_.user_info_id as user_inf1_1_, userinfo0_.country as country2_1_ from user_info userinfo0_ ## 后面的SQL都是通过查到的外键一条一条SQL查子实体类信息 Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? Hibernate: select userinfos0_.user_id as user_id1_2_0_, userinfos0_.user_info_id as user_inf2_2_0_, userinfo1_.user_info_id as user_inf1_1_1_, userinfo1_.country as country2_1_1_ from user_user_info userinfos0_ inner join user_info userinfo1_ on userinfos0_.user_info_id=userinfo1_.user_info_id where userinfos0_.user_id=? Hibernate: select user0_.user_info_id as user_inf2_2_0_, user0_.user_id as user_id1_2_0_, user1_.user_id as user_id1_0_1_, user1_.username as username2_0_1_ from user_user_info user0_ inner join user user1_ on user0_.user_id=user1_.user_id where user0_.user_info_id=? CN
5、实体类映射关联的最佳实践
第⼀:我要说⼀种 Java ⾯向对象的设计原则:开闭原则。
即对扩展开放,对修改关闭。如果我们⼀直使⽤双向关联,两个实体的对象耦合太严重了。想象⼀下,随着业务的发展,User 对象可能是原始对象,围绕着 User 可能会扩展出各种关联对象。难道 User ⾥⾯每次都要修改,去添加双向关联关系吗?肯定不是,否则时间⻓了,对象与对象之间的关联关系就是⼀团乱麻。
所以,我们尽量、甚⾄不要⽤双向关联,如果⾮要⽤关联关系的话,只⽤单向关联就够了。双向关联正是 JPA 的强⼤之处,但同时也是问题最多,最被⼈诟病之处。所以我们要⽤它的优点,⽽不是学会了就⼀定要使⽤。
第⼆:我想说 CascadeType 很强⼤,但是我也建议保持默认。
即没有级联更新动作,没有级联删除动作。还有 orphanRemoval 也要尽量保持默认 false,不做级联删除。因为这两个功能很强⼤,但是我个⼈觉得这违背了⾯向对象设计原则⾥⾯的“职责单⼀原则”,除⾮你⾮常⾮常熟悉,否则你在⽤的时候会时常感到惊讶——数据什么时间被更新了?数据被谁删除了?遇到这种问题查起来⾮常麻烦,因为是框架处理,有的时候并⾮预期的效果。⼀旦⽣产数据被莫名更新或者删除,那是⼀件⾮常糟糕的事情。因为这些级联操作会使你的⽅法名字没办法命名,⽽且它不是跟着业务逻辑变化的,⽽是跟着实体变化的,这就会使⽅法和对象的职责不单⼀。
第三:我想告诉你,所有⽤到关联关系的地⽅,能⽤ Lazy 的绝对不要⽤ EAGER,否则会有 SQL 性能问题,会出现不是预期的 SQL。
第四:数据库外键约束一般不推荐使⽤,一般使用逻辑外键,使用Java关联即可。
6、实体类映射之 参考文献 & 鸣谢
讲明白Spring Data JPA实体关联注解:
Spring Data JPA(多表设计、一对多、多对多、多表查询)https://mp.weixin.qq.com/s/XezlJDltvugRFpSmcrjedw
Spring Data JPA 之 实体之间关联关系:https://blog.csdn.net/qq_40161813/article/details/125109649
SpringDataJPA实体类关系映射配置:https://blog.csdn.net/qq_42315782/article/details/103280330
SpringData JPA 之疑难杂症
1、JPA自动建表不生成外键
SpringBoot项目搭配的JPA使用时候,有一对多的关系注解,那么自动会生成外键。外键在有些时候,会导致代码不能走通,我们不想要怎么做。有两种解决方案.
1.1、多表关系映射:一对多
情况一:单向一对多/多对一,在@JoinColumn内加上@ForeignKey属性配置即可
@OneToMany
@JoinColumn(name="cid",foreignKey = @ForeignKey(name = "none",value = ConstraintMode.NO_CONSTRAINT))
@ManyToOne
@JoinColumn(name="cid",foreignKey = @ForeignKey(name = "none",value = ConstraintMode.NO_CONSTRAINT))
情况二:双向一对多,除了在@JoinColumn加@ForeignKey配置,还需要再另一方(一方)加配置
1.解决方案一:
// 一方加@org.hibernate.annotations.ForeignKey,注意:这个注解被废弃了,所以更新jar包的时候需要注意下
@org.hibernate.annotations.ForeignKey(name = “none”)
@OneToMany
// 多方配置不变
@ManyToOne
@JoinColumn(name="cid",foreignKey = @ForeignKey(name = "none",value = ConstraintMode.NO_CONSTRAINT))
2.解决方案二:
// 一方加@Transient,意思是忽略该字段,我认为加上这个字段后在加@OneToMany也无意义了.
@Transient
@OneToMany
// 多方配置不变
@ManyToOne
@JoinColumn(name="cid",foreignKey = @ForeignKey(name = "none",value = ConstraintMode.NO_CONSTRAINT))
2.2、多表关系映射:多对多
多对多也是类似的处理方式:
单向多对多:只要在@JoinTable内的@JoinColumn内加上@ForeignKey属性配置即可,记得连个表外键都要加
@ManyToMany(fetch = FetchType.EAGER)
@JoinTable(name="tb_student_teacher",
joinColumns=@JoinColumn(
name="student_id",
referencedColumnName = "student_id",
foreignKey = @ForeignKey(name = "none",value = ConstraintMode.NO_CONSTRAINT)),
inverseJoinColumns=@JoinColumn(
name="teacher_id",
referencedColumnName = "teacher_id",
foreignKey = @ForeignKey(name = "none",value = ConstraintMode.NO_CONSTRAINT)))
双向多对多:参照双向一对多/多对一,在另一方加注解即可。
2、关于实体对象查询异常
WARNING: Please consider reporting this to the maintainers of org.springframework.data.projection.DefaultMethodInvokingMethodInterceptor
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Hibernate: sql语句
java.lang.StackOverflowError
at java.base/java.lang.AbstractStringBuilder.inflate(AbstractStringBuilder.java:202)
at java.base/java.lang.AbstractStringBuilder.putStringAt(AbstractStringBuilder.java:1639)
at java.base/java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:513)
.......
关以这种错误大多都是编写的toString语句发生了错误,大家在写toString的时候一定要分清主表和从表,在编写主表的toString的时候一定要去除外键字段,而在编写从表的时候一定要加上外键字段,因为平时我们都是通过从表查询数据(因为从表有指向主表的外键),这样可以把主表的数据通过外键查询出来,但是主表上如果也有从表的字段的话就会一只循环,数据没完没了,所有抛异常也是对的,
总结一句话:从表有主表的字段,主表有从表的字段,打印从表顺带打印主表,但是主表里面还有从表字段,然后继续打印从表字段…….
解决方案:
- 去除 @Data 注解,替换成 @Getter 和 @Setter 注解,使用@ToString(exclude = “引用类型字段”)
- 也可以重写
toString()方法,把引用类型的输出删掉即可 - 查询后可以不要输出打印该对象,这样就不会死循环输出对象中的对象了(治标不治本, 不推荐)
在实体类上增加@JsonIgnoreProperties(value = "对方类引用本类的属性名")(我暂时试了是无效的,打印对象还是会报错)
3、关于延迟加载事务问题
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: cn.xw.domain.Teacher.students, could not initialize proxy - no Session
at org.hibernate.collection.internal.AbstractPersistentCollection.throwLazyInitializationException(AbstractPersistentCollection.java:606)
at org.hibernate.collection.internal.AbstractPersistentCollection.withTemporarySessionIfNeeded(AbstractPersistentCollection.java:218)
at org.hibernate.collection.internal.AbstractPersistentCollection.initialize(AbstractPersistentCollection.java:585)
at org.hibernate.collection.internal.AbstractPersistentCollection.read(AbstractPersistentCollection.java:149)
at org.hibernate.collection.internal.PersistentSet.toString(PersistentSet.java:327)
at java.base/java.lang.String.valueOf(String.java:2801)
at java.base/java.lang.StringBuilder.append(StringBuilder.java:135)
关于在使用延迟加载的时候,在当前的方法上必须设置@Transactional,因为在使用延迟加载底层已经使用了事务的相关方法
4、关于懒加载no session异常
解释的非常详细:https://blog.csdn.net/qq_45795744/article/details/123562759
org.hibernate.LazyInitializationException: failed to lazily initialize XXXXX could not initialize proxy - no Session
根据错误的提示信息:JPA 使用 lazy 懒加载模式读取 子实体对象时(集合属性读取时),当前针对数据库的访问与操作session已经关闭且释放了,故提示no Session可用。
原因:在我们配置了延时加载时,导致了EntityManager的提前关闭 等到再次使用的时候Spring即找不到了
解决办法关闭懒加载:lazy=“false”。若是用注解生成的。fetch = FetchType.EAGER。
# 这个配置的意思就是在没有事务的情况下允许懒加载(可以理解为开启懒加载,实际上默认是开启的)
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
当然了,这样的话,你的缓存就不起作用了。另外解决办法,获取数据时,使用用 left join fetch 或 inner join fetch 语法。
开启懒加载会影响性能,关闭会导致无法get子对象的值时自动查询(session 关了)最好的解决方式是再次查询子对象一次。
解决JPA延迟加载no Session报错:https://blog.csdn.net/weixin_45309354/article/details/125342528
Spring Boot中的spring.jpa.open-in-view = true属性是什么?https://www.jb51.cc/faq/884069.html
解决LazyInitializationException异常大概有这么几种方式:
- 关闭LazyInitialization, 将fetch设成eager
- 用Spring的OpenSessionInViewFilter
- SpringBoot的配置文件增加
spring.jpa.open-in-view=true(OSIV默认也是开启的),然后使用@Transactional - 在查询方法上增加事务@Transactional,延长Session的生成周期(推荐)
第一种方式显然不好,无法使用到延迟加载的特性,会带来性能问题
第二种方式只能用在Servlet容器下,而当我们在SpringBoot环境下运行单元测试的时候是无法启用OpenSessionInViewFilter的
第三种与第四种实际上是同一种方式,由于OSIV默认也是开启的,推荐使用第四种即可。
总结懒加载会话失效异常解决方案就两点:
- 关闭懒加载,开启立即加载
- 延长Session的生命周期
5、关于数据库方言问题(Dialect)
6月 03, 2020 4:57:00 下午 org.hibernate.dialect.Dialect <init>
INFO: HHH000400: Using dialect: org.hibernate.dialect.MySQLDialect
省去部分...
Hibernate: create table family (...) type=MyISAM
//上面一局为我们创建的是一张表并设置MyISAM引擎 错误就在这 无法运行了
6月 03, 2020 4:57:01 下午 org.hibernate.tool.schema.internal.ExceptionHandlerLoggedImpl handleException
WARN: GenerationTarget encountered exception accepting command : Error executing DDL "create table family (...) type=MyISAM" via JDBC Statement
org.hibernate.tool.schema.spi.CommandAcceptanceException: Error executing DDL "create table family (...) type=MyISAM" via JDBC Statement
//从上面错误可以看出 程序运行的时候默认的数据库方言设置了 org.hibernate.dialect.MySQLDialect 而这个默认是MyISAM引擎
问题所在:因为我导入的hibernate坐标是5.4.10.Final,在导入这类高版本的坐标往往要为数据库方言设置MySQL5InnoDBDialect的配置,在我前面也测试了,关于坐标版本问题,发现5.0.x.Final左右的版本不用设置数据库方言,默认即可。
# 设置数据库方言,建表使用MyISAM,默认是InnoDB
spring.jpa.database-platform=org.hibernate.dialect.MySQL5Dialect
具体的版本在创建数据库表的时候会抛各种异常,这里我整理了一下数据库方言,方便大家参考
数据库方言
DB2 org.hibernate.dialect.DB2Dialect
DB2 AS/400 org.hibernate.dialect.DB2400Dialect
DB2 OS390 org.hibernate.dialect.DB2390Dialect
PostgreSQL org.hibernate.dialect.PostgreSQLDialect
MySQL org.hibernate.dialect.MySQLDialect
MySQL with InnoDB org.hibernate.dialect.MySQLInnoDBDialect
MySQL with MyISAM org.hibernate.dialect.MySQLMyISAMDialect
Oracle (any version) org.hibernate.dialect.OracleDialect
Oracle 9i/10g org.hibernate.dialect.Oracle9Dialect
Sybase org.hibernate.dialect.SybaseDialect
Sybase Anywhere org.hibernate.dialect.SybaseAnywhereDialect
Microsoft SQL Server org.hibernate.dialect.SQLServerDialect
SAP DB org.hibernate.dialect.SAPDBDialect
Informix org.hibernate.dialect.InformixDialect
HypersonicSQL org.hibernate.dialect.HSQLDialect
Ingres org.hibernate.dialect.IngresDialect
Progress org.hibernate.dialect.ProgressDialect
Mckoi SQL org.hibernate.dialect.MckoiDialect
Interbase org.hibernate.dialect.InterbaseDialect
Pointbase org.hibernate.dialect.PointbaseDialect
FrontBase org.hibernate.dialect.FrontbaseDialect
Firebird org.hibernate.dialect.FirebirdDialect
6、Executing an update/delete query
Caused by: javax.persistence.TransactionRequiredException: Executing an update/delete query
如果代码执行报如上错误,是由于在执行了更新删除操作没有加上事物,我们只需要加上@Transactional即可。不加会报错。
注意:有一种情况除外,就是在做单元测试的时候,加了@Transactiona也不起作用,必须加上@Transactiona + @Rollback(false),具体缘由参考下篇文章(SpringBoot Junit事物自动回滚)
7、SpringBoot Junit事物自动回滚
1、问题:在Spring单元测试类中的更新方法测试成功通过并没有报错,但数据库没有插入数据。
测试代码如下(执行测试方法后,数据库没有插入数据):
@Test
@Transactional
public void save() {
User user = new User();
user.setUsername("admin");
user.setPassword("password");
userRepository.save(user); // userRepository继承了JpaRepository
}
输出日志:
2022-01-27 15:39:29.022 INFO 6964 --- [ main] o.s.t.c.transaction.TransactionContext : Began transaction (1) for test context [DefaultTestContext@301ec38b testClass = DemoApplicationTests, testInstance = com.example.demo.DemoApplicationTests@57ea113a, testMethod = save@DemoApplicationTests, testException = [null], mergedContextConfiguration = [MergedContextConfiguration@17a1e4ca testClass = DemoApplicationTests, locations = '{}', classes = '{class com.example.demo.DemoApplication}', contextInitializerClasses = '[]', activeProfiles = '{}', propertySourceLocations = '{}', propertySourceProperties = '{org.springframework.boot.test.context.SpringBootTestContextBootstrapper=true}', contextCustomizers = set[org.springframework.boot.test.context.filter.ExcludeFilterContextCustomizer@194fad1, org.springframework.boot.test.json.DuplicateJsonObjectContextCustomizerFactory$DuplicateJsonObjectContextCustomizer@65f8f5ae, org.springframework.boot.test.mock.mockito.MockitoContextCustomizer@0, org.springframework.boot.test.web.client.TestRestTemplateContextCustomizer@4d15107f, org.springframework.boot.test.autoconfigure.actuate.metrics.MetricsExportContextCustomizerFactory$DisableMetricExportContextCustomizer@5a5a729f, org.springframework.boot.test.autoconfigure.properties.PropertyMappingContextCustomizer@0, org.springframework.boot.test.autoconfigure.web.servlet.WebDriverContextCustomizerFactory$Customizer@71687585, org.springframework.boot.test.context.SpringBootTestArgs@1, org.springframework.boot.test.context.SpringBootTestWebEnvironment@1e7c7811], contextLoader = 'org.springframework.boot.test.context.SpringBootContextLoader', parent = [null]], attributes = map['org.springframework.test.context.event.ApplicationEventsTestExecutionListener.recordApplicationEvents' -> false]]; transaction manager [org.springframework.orm.jpa.JpaTransactionManager@4348fa35]; rollback [true]
Hibernate:
insert
into
sys_user
(id, password, username)
values
(null, ?, ?)
2022-01-27 15:39:29.261 INFO 6964 --- [ main] o.s.t.c.transaction.TransactionContext : Rolled back transaction for test: [DefaultTestContext@301ec38b testClass = DemoApplicationTests, testInstance = com.example.demo.DemoApplicationTests@57ea113a, testMethod = save@DemoApplicationTests, testException = [null], mergedContextConfiguration = [MergedContextConfiguration@17a1e4ca testClass = DemoApplicationTests, locations = '{}', classes = '{class com.example.demo.DemoApplication}', contextInitializerClasses = '[]', activeProfiles = '{}', propertySourceLocations = '{}', propertySourceProperties = '{org.springframework.boot.test.context.SpringBootTestContextBootstrapper=true}', contextCustomizers = set[org.springframework.boot.test.context.filter.ExcludeFilterContextCustomizer@194fad1, org.springframework.boot.test.json.DuplicateJsonObjectContextCustomizerFactory$DuplicateJsonObjectContextCustomizer@65f8f5ae, org.springframework.boot.test.mock.mockito.MockitoContextCustomizer@0, org.springframework.boot.test.web.client.TestRestTemplateContextCustomizer@4d15107f, org.springframework.boot.test.autoconfigure.actuate.metrics.MetricsExportContextCustomizerFactory$DisableMetricExportContextCustomizer@5a5a729f, org.springframework.boot.test.autoconfigure.properties.PropertyMappingContextCustomizer@0, org.springframework.boot.test.autoconfigure.web.servlet.WebDriverContextCustomizerFactory$Customizer@71687585, org.springframework.boot.test.context.SpringBootTestArgs@1, org.springframework.boot.test.context.SpringBootTestWebEnvironment@1e7c7811], contextLoader = 'org.springframework.boot.test.context.SpringBootContextLoader', parent = [null]], attributes = map['org.springframework.test.context.event.ApplicationEventsTestExecutionListener.recordApplicationEvents' -> false]]
2、原因:SpringBoot使用Junit编写单元测试,@Transactional默认是事物回滚的,这样测试的脏数据不影响数据库。具体看控制台输出关键日志部分:
Began transaction (1) for test context ....
Rolled back transaction for test: ....
3、解决方法:测试方法加上注解 @Rollback(true),关闭自动事物回滚。
@Test
@Transactional
@Rollback(false)
public void save() {
User user = new User();
user.setUsername("admin");
user.setPassword("password");
userRepository.save(user); // userRepository继承了JpaRepository
}
查看关键日志部分:
Began transaction (1) for test context ...
Committed transaction for test: ...
Spring Boot Junit事物自动回滚总结:
因为用了JPA配合Hibernate ,采用注解默认是开启了LayzLoad也就是懒加载,所以不得不在Junit的单元测试上加上@Transactional注解,这样Spring会自动为当前线程开启Session,这样在单元测试里面懒加载才不会因为访问完Repo之后,出现:
session not found.,但是单元测试里面如果加上了@Transactional会自动回滚事务,需要在单元测试上面加上@Rollback(false)
8、对象属性设置值会自动更新数据库
使用Spring Data JPA获取的对象,事物开启时,其属性变更后自动更新数据库问题排查与解决方案
参考文献 & 鸣谢:转-Spring Data JPA中对象属性自动更新数据库:https://www.cnblogs.com/east7/p/14453910.html
问题描述:
使用继承了JpaRepository的接口从数据库中获取到某个对象,然后操作这个对象的set属性值时,新值会直接更新到数据库。例如,UserRepository继承了JpaRepository,从数据库查询出User类实例user,当对user执行set属性修改时,新值会直接更新到数据库。
问题代码:(PS:出现这种情况有个前提条件,就是当前方法开启了事物)
@Test
@Transactional
@Rollback(false) // 由于是在junit中测试,所以必须取消自动回滚
public void testUpdate(){
// 持久化状态,当前方法加了事物,SpringDataJPA在事物完成的时候,会自动提交修改
User user = this.userRepository.findById(1L).get();
user.setUsername("王小小");
}
输出日志:
Hibernate:
select
user0_.id as id1_0_0_,
user0_.password as password2_0_0_,
user0_.username as username3_0_0_
from
sys_user user0_
where
user0_.id=?
Hibernate:
update
sys_user
set
password=?,
username=?
where
id=?
可以发现查询完对象后,在给对象设置值后,就自动更新到数据库了
问题分析:
由于方法上开启了事物,发现事务结束时会把属性发生改变的user对象更新到数据库,在控制台打印的日志中也可以看见相关update sql语句。百思不得其解,为什么从数据库中获取到的对象属性发生变更的时候,数据库就自动执行更新操作呢?原来是JPA的自带特性在作怪:Hibernate对象有四种状态,【持久态对象的属性被修改后,在数据库事务提交的时候,会更新数据库。】
回顾实体对象的四种状态以及转换关系:
Spring Data JPA 可以理解为 是对 JPA 规范的二次封装和抽象,底层还是使用了 Hibernate 的 JPA 技术实现。因此,还是要不辞劳苦地翻阅Hibernate文档。最新的Hibernate文档中为Hibernate对象定义了四种状态(原来是三种状态,面试的时候基本上问的也是三种状态),分别是:瞬时态(new, or transient)、持久态(managed, or persistent)、游状态(detached)和移除态(removed,以前Hibernate文档中定义的三种状态中没有移除态),如下图所示,就以前的Hibernate文档中移除态被视为是瞬时态。
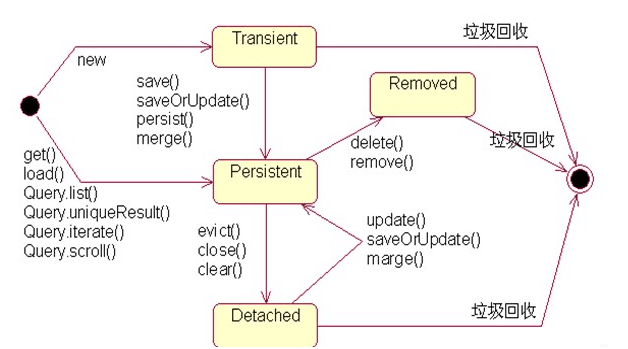
- 瞬时态:当new一个实体对象后,这个对象处于瞬时态,即这个对象只是一个保存临时数据的内存区域,如果没有变量引用这个对象,则会被JVM的垃圾回收机制回收。这个对象所保存的数据与数据库没有任何关系,除非通过Session的save()、saveOrUpdate()、persist()、merge()方法把瞬时态对象与数据库关联,并把数据插入或者更新到数据库,这个对象才转换为持久态对象。
- 持久态:持久态对象的实例在数据库中有对应的记录,并拥有一个持久化标识(ID)。对持久态对象进行delete操作后,数据库中对应的记录将被删除,那么持久态对象与数据库记录不再存在对应关系,持久态对象变成移除态(可以视为瞬时态)。持久态对象被修改变更后,不会马上同步到数据库,直到数据库事务提交。
- 游离态:当Session进行了close()、clear()、evict()或flush()后,实体对象从持久态变成游离态,对象虽然拥有持久和与数据库对应记录一致的标识值,但是因为对象已经从会话中清除掉,对象不在持久化管理之内,所以处于游离态(也叫脱管态)。游离态的对象与临时状态对象是十分相似的,只是它还含有持久化标识。
- 移除态:当调用EntityManger对实体进行delete后,该实体对象就处于删除状态。其本质也就是一个瞬时状态的对象
问题解决:
1、更新的方法不开启事物处理,然后使用save()等方法更新操作即可(缺点:没有事物无法回滚,不能保证数据一致性)
@Test
public void testUpdate(){
// 持久化状态的,不过没有加事物控制
User user = this.userCrudRepository.findById(1L).get();
user.setUsername("王小红");
this.userCrudRepository.save(user);
}
2、因持久层框架JPA自身的机制,会在事务提交后将持久状态的对象自动更新到数据库,为了避免自动更新,我们可以创建一个对象,设置好属性后再调用save()方法更新数据(缺点:比较繁琐,代码也会变得不够简洁)
@Test
@Transactional
public void testUpdate(){
// 持久化状态的,不过没有加事物控制
User user = this.userCrudRepository.findById(1L).get();
User userNew = new User();
userNew.setId(user.getId)
userNew.setUsername("admin");
userNew.setPassword(user.getPassword);
this.userCrudRepository.save(userNew);
}
3、把持久态的对象变成游离态即可,有如下三种方法(缺点也是需要注入EntityManager)
- close() 方法:关闭session可以,但是若后面还要用session这个方法就不太好了
- clear() 方法:将session中所有的对象全部清除缓存
- evict() 方法:将某一个对象清楚缓存session(推荐)
@PersistenceContext
private EntityManager entityManager;
@Test
@Transactional
public void testUpdate(){
// 持久化状态的,不过没有加事物控制
User user = this.userCrudRepository.findById(1L).get();
// 检查对象是否是持久化态
if (entityManager.contains(user)) {
// 获取session
Session session = entityManager.unwrap(org.hibernate.Session.class);
// 转换成游离态
session.evict(entry);
}
user.setUsername("王小红");
this.userCrudRepository.save(user);
}
9、@OneToOne 主类设置懒加载失效
Hibernate @OneToOne懒加载实现解决方案:http://wjhsh.net/jpfss-p-11058703.html
10、Hibernate 代理转换为真实的实体对象
1、实体类及测试代码:
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "user")
public class User implements Serializable {
// ...省略基本属性,只关注关联属性或字段
@Id
@Column(name = "user_id")
private Long userId;
@Column(name = "username")
private String username;
@OneToMany(mappedBy = "user")
private List<UserInfo> userInfos;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString(exclude = "user")
@Entity
@Table(name = "user_info")
public class UserInfo implements Serializable {
// ...省略基本属性,只关注关联属性或字段
@Id
@Column(name = "user_info_id")
private Long userInfoId;
@Column(name = "country")
private String country;
@JsonIgnore
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", referencedColumnName = "user_id")
private User user;
}
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
@TestPropertySource(properties = {
"spring.jpa.hibernate.ddl-auto=create",
"spring.jpa.properties.hibernate.format_sql=true"
})
class JpaApplicationTests {
@Autowired UserRepository userRepository;
@Autowired UserInfoRepository userInfoRepository;
@PersistenceContext EntityManager entityManager;
/**
* 初始化数据:非级联添加: 先保存user, 并且设置user到userInfo中, 然后再保存userInfo
*/
@Test
@Order(1)
@Rollback(false)
@Transactional
void cascadeSave() {
System.out.println("===========cascadeSave()===========");
// 从类方级联新增
User user1 = new User(1L, "DEV", null);
User user2 = new User(2l, "UAT", null);
userRepository.saveAllAndFlush(Arrays.asList(user1, user2));
UserInfo userInfo1 = new UserInfo(1L, "CN", user1);
UserInfo userInfo2 = new UserInfo(2L, "EN", user1);
UserInfo userInfo3 = new UserInfo(3L, "UK", user2);
UserInfo userInfo4 = new UserInfo(4L, "DE", user2);
userInfoRepository.saveAllAndFlush(Arrays.asList(userInfo1, userInfo2, userInfo3, userInfo4));
}
@Test
@Order(2)
@Transactional
void query() {
try {
System.out.println("===========query()===========");
/**
* 首先查询从类数据, 由于设置了懒加载, 并且JPA自带了缓存效果。
* 在第一次查询userInfo的时候实际上已经代理了user对象。
* 所以再次查询相关联user数据时, 直接获取了缓存中的代理对象.
* 代理对象看似有数据, 其实字段又都为null. 不影响正常使用, 但是会影响JSON序列化
*/
UserInfo userInfo = userInfoRepository.findById(1L).get();
User user = userRepository.findById(1L).get();
String json = new ObjectMapper().writeValueAsString(user);
System.out.println(json);
System.out.println("===========update()===========");
userRepository.saveAndFlush(new User(3l, "OAT", null));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}
2、正常执行测试代码会报如下错误(在ObjectMapper序列化时报错):
java.lang.RuntimeException: com.fasterxml.jackson.databind.exc.InvalidDefinitionException: No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS) (through reference chain: com.example.jpa.entity.User$HibernateProxy$CND2bnZ6["hibernateLazyInitializer"])
3、报错原因分析,首先我们DEBUG查看userInfo与user对象的值(可以发现虽然 userInfo 与 user 是分开2次查询的,但是 userInfo.user 与 user 是同一个引用对象,并且都是JPA的代理对象)从数据中筛选出的 user 不是真正的实体对象,虽然在当前的代码中不影响使用,但是在某些场景下,我们不希望只获取到代理对象。
> userInfo = {UsesrInfo@9823} "UserInfo(userInfoId=1, country=CN)"
> userInfoId = {Long@12666} 1
> country = "CN"
> user = {User$HibernateProxy$CND2bnZ6@12668} "User(userId=1, username=DEV, userInfos=[UserInfo(userInfoId=1, country=CN), UserInfo(userInfoId=2, country=EN)])"
> user = {User$HibernateProxy$CND2bnZ6@12668} "User(userId=1, username=DEV, userInfos=[UserInfo(userInfoId=1, country=CN), UserInfo(userInfoId=2, country=EN)])"
> $$_hibernate_interceptor = {ByteBuddyInterceptor}
userId = null
username = null
userInfos = null
4、解决方案:
将 Hibernate 代理转换为真实的实体对象
UserInfo userInfo = userInfoRepository.findById(1L).get(); user = (User) Hibernate.unproxy(user); User user = userRepository.findById(1L).get();清理当前Session的缓存即可(推荐)
UserInfo userInfo = userInfoRepository.findById(1L).get(); entityManager.clear(); User user = userRepository.findById(1L).get();
5、将 Hibernate 代理转换为真实的实体对象详细分析
从 Hibernate ORM 5.2.10开始,您可以这样做:
Object unproxiedEntity = Hibernate.unproxy(proxy);在 Hibernate 5.2.10之前。最简单的方法是使用Hibernate 内部实现提供的unproxy方法:
PersistenceContextObject unproxiedEntity = ((SessionImplementor) session).getPersistenceContext().unproxy(proxy);除此之外,还有一种方法,相较于上面稍微复杂了点(实际上就是Hibernate.unproxy()中的方法):
public static <T> T initializeAndUnproxy(T entity) { if (entity == null) { throw new NullPointerException("Entity passed for initialization is null"); } Hibernate.initialize(entity); if (entity instanceof HibernateProxy) { entity = (T) ((HibernateProxy) entity).getHibernateLazyInitializer() .getImplementation(); } return entity; }
6、参考文献:
- Spring Data JPA关于懒加载的那些事:https://blog.csdn.net/Huangjiazhen711/article/details/127084960
- 一次 Spring Data JPA 查询返回数据属性为 null 排查:https://www.cnblogs.com/seliote/p/15230641.html
参考文献 & 鸣谢
- 博客园(蚂蚁小哥)Spring Data JPA入门及深入(重点)https://www.cnblogs.com/antLaddie/p/12996320.html
- CSDN(布道)JPA之Spring Data JPA(重点)https://blog.csdn.net/alex_xfboy/article/details/82907517
- SpringDataJpa中的复杂查询和动态查询,多表查询(保姆级教程)https://juejin.cn/post/6844904160807092237
- SpringDataJPA+Hibernate框架源码剖析:https://blog.csdn.net/yangxiaofei_java/category_11645418.html
Spring Data JPA 文章汇总:
- 曾小二的秃头之路:https://blog.csdn.net/qq_40161813/category_11746503.html
- IT利刃出鞘:https://blog.csdn.net/feiying0canglang/category_11318443.html
- 架构悟道:https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzIwMjgxMTY2MQ==&action=getalbum&album_id=2452725517146685442
SpringData JPA 联表查询性能优化:
- JPA效率优化—@EntityGraph:https://juejin.cn/post/6869650227268157454
- Spring Data JPA 原理与实战第十三天 解决N+1 SQL问题:https://bgmbk.blog.csdn.net/article/details/124895647
1、配置JPA的数据源,需要配置:
- DataSource数据源
- EntityManager 实体管理器
- EntityManagerFactoryBean 实体管理器工厂
- PlatformTransactionManager 事务管理器
2、@PersistenceUnit、@PersistenceContext:https://blog.csdn.net/tfstone/article/details/119330721
@PersistenceUnit // @PersistenceUnit用来注入EntityManagerFactory
EntityManagerFactory entityManagerFactory;
@PersistenceContext // PersistenceContext 用来注入EntityManager
EntityManager entityManager;
主要区别
| 特性 | @PersistenceContext | @PersistenceUnit |
|---|---|---|
| 注入的对象 | EntityManager |
EntityManagerFactory |
| 生命周期管理 | 自动管理 EntityManager 的生命周期 |
需要手动创建和管理 EntityManager |
| 使用场景 | 简单的 CRUD 操作,通常在 DAO 层使用 | 需要手动管理 EntityManager 的复杂场景 |
| 事务管理 | 支持事务管理,通常与 Spring 的事务管理集成 | 需要手动管理事务 |
总结
- 使用
@PersistenceContext时,您可以更方便地进行持久化操作,Spring 会自动管理EntityManager的生命周期。 - 使用
@PersistenceUnit时,您可以更灵活地控制EntityManager的创建和管理,适用于更复杂的场景。
选择使用哪个注解取决于您的具体需求和应用程序的复杂性。对于大多数常见的持久化操作,@PersistenceContext 是更常用的选择。
3、SpringBoot配置实体管理器EntityManager:https://blog.csdn.net/qq_20916555/article/details/80860002
EntityManager是JPA中用于增删改查的接口,它的作用相当于一座桥梁,连接内存中的java对象和数据库的数据存储。使用EntityManager中的相关接口对数据库实体进行操作的时候, EntityManager会跟踪实体对象的状态,并决定在特定时刻将对实体的操作映射到数据库操作上面。
EntityManager的核心概念图:
Persistence
1 ⬇ 创
* ⬇ 建 1 *
EntityManageFactory ➡➡ EntityManag
1 ⬆ 配 创建 * ⬇ 管
1 ⬆ 置 1 * 1 ⬇ 理
PersistenceUnit ➡➡ PersistenceContext
创建
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 8629303@qq.com

